Последовательный анализ
Отличительной особенностью всех рассмотренных процедур выбора решения при распознавании (проверка простой гипотезы) была неизменность заранее заданного размера выборки n.
Наряду с этим существует другой подход к установлению правила выбора решения, при котором отказываются от постоянного размера выборки, а ограничивают эту величину в процессе эксперимента в зависимости от результатов уже выполненных наблюдений.
Алгоритм последовательного анализа:
1) вначале наблюдают первое значение х1 (т.е. извлекают выборку значения n=1);
2) выбирают одно из 3-х решений:
– принять гипотезу H0 (решение g0);
– принять гипотезу Н1 (решение g1);
– продолжить наблюдения, т.е. отказаться от принятия решений g0 и g1.
3) при принятии решений эксперименты заканчиваются;
4) в противном случае извлекают следующую выборку (х1,х2,n=2) (процедуры повторяются);
5) если окончательное решение не принято, то извлекается новая выборка и т.д.;
6) испытание заканчивается на той выборке, на основании которой принимается решение g0 и g1.
Определение: При последовательном анализе размер выборки заранее
неизвестен и является случайной величиной.
На каждом этапе пространство выборки делится на 3 области (а не на две!):
- G1 – критическую;
- G0 – допустимую;
- GПР – промежуточную.
Тогда алгоритм:
- если очередное Xi попадает в критическую область G1, то гипотеза H0 отвергается;
- если Xi попадает в допустимую область G0, то она принимается;
- если выборочное значение попало в промежуточную область GПР, то наблюдения продолжаются.
Следствие: Поскольку число способов разбиения пространства выбора
в принципе не ограничено, то неизбежен набор различных правил выбора решения. Тогда необходимо формирование критериев качества, с помощью которых можно сравнивать различные процедуры последовательного анализа и выбрать наилучшую.
Критерии качества
1. минимальная средняя стоимость эксперимента.
Определение: Если считать, что стоимость эксперимента пропорциональна размеру выборки n, то критерием качества последовательного правила выбора решения является минимум среднего значения размера выборки n, необходимый для принятия решений g0 и g1 при условии, что уровень значимость не превышает a!!, а мощность – не меньше, чем 1-b!!.
Следствие: Среднее значение размера выборки m1(n/H0) и m1(n/H1) при справедливости гипотез Н0 и Н1, соответственно, в общем случае не равны и требуется минимизация обеих величин.
Правило Вальда
Для всех правил выборки решения, где условные вероятности ошибок a и b не превосходят заданных значений, последовательное правило, состоящее в сравнении отношения правдоподобия L(x1,…,xn) с двумя порогами С0 и С1, приводит к наименьшим затратам (значениям) m1(n/H0) и m1(n/H1).
Оптимальное разбиение пространства выборки определяется неравенствами:
1) для допустимой области G0:
C0 < L(x1,…,xk) < C1; k=1,…,n-1; L(x1,…,xn) 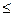 C0;
C0;
2) для критической области G1:
C0 < L(x1,…,xk) < C1; k=1,…,n-1; L(x1,…,xn) 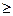 C1;
C1;
3) для промежуточной области GПР:
C0 < L(x1,…,xn) < C1; k=1,…,n.
Точное определение С0 и С1 математически сложно. Однако, доказано, что:
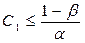
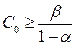
Пример: Проверка простой гипотезы о параметрическом распределении:
- гипотеза Н0: среднее значение нормальной случайной величины равно а0;
- альтернативная гипотеза Н1: среднее значение нормальной случайной величины а1.
Тогда N(s,a0) или N(s,a1)?
Элементы х1,…,хn – независимы.
Пусть имеем пока один порог С1, с которым сравнивается L(x) или
LnL(x). Для нормального закона:
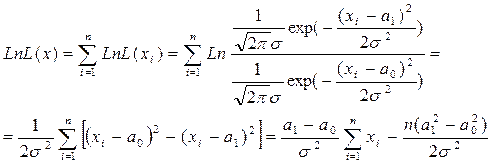
При фиксированном размере выборки имеем правило g1:
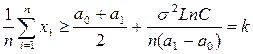 а1>a0
а1>a0
Для критерия максимального правдоподобия:
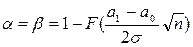
Замечательное следствие: При заданном a=b из этой формулы находим необходимый размер выборки:
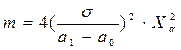
где Х2a = argF(X).
В математической статистике Xa называют процентным отклонением случайной величины, т.е. такую абсциссу кривой распределения, которая характеризуется тем, что часть площади под этой кривой находящаяся правее Хa, равна Х.
т.е. P{x Xa} = a.
Для критерия Неймана – Пирсона на заданном уровне значимости a величина К определяется по формуле (а1>а0):
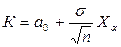
Еще одно следствие: Вероятности ошибок a и b в байесовском решении и вероятность ошибки 2-го рода для критерия Неймана – Пирсона зависят не от каждой из величин n, а1, а0, s в отдельности, а лишь от их единственной комбинации 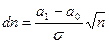 . Отсюда следует, что при уменьшении величины
. Отсюда следует, что при уменьшении величины 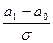 (в к раз, случай различения близких гипотез) для сохранения величин вероятности ошибок потребуется увеличение (в к2 раз!) размера выборки n.
(в к раз, случай различения близких гипотез) для сохранения величин вероятности ошибок потребуется увеличение (в к2 раз!) размера выборки n.
Если а1<а0, то решение g1 по критерию Неймана - Пирсона принимается при условии, что:
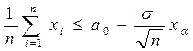
Ситуация 2: Вид аналитической функции априори неизвестен, т.е. характер априорной неопределенности таков, что какие-либо сведения об аналитическом описании исходного материала полностью отсутствуют: неизвестно распределение вероятности наблюдаемых значений xi, i=1,…,n, неизвестен вид платежной матрицы (функции потерь), неизвестны также плотности вероятности параметров f(ax), влияющих на величину потерь, неизвестны и последствия от принятия того или иного решения (виды оценивания).
За ту крайность приходится расплачиваться довольно серьезными ограничениями, которые выражают иную форму представления имеющихся априорных значений, отличную от параметрических описаний.
Следствие: Таким образом, параметрическое и непараметрическое описания исходных данных задачи соответствуют разным видам имеющихся ограниченных априорных знаний и взаимно дополняют друг друга.
Дата добавления: 2016-01-20; просмотров: 2104;