Для оценки плотности в некоторой точке методом “парзеновского окна” подсчитывается количество объектов, попадающих в фиксированную малую окрестность .
Эта окрестность 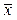 выбирается таким образом, что с увеличением N ее объем VN уменьшается. Если при N®¥ VN®0, k®¥ и k/N®0, то оценка плотности в точке является состоятельной.
выбирается таким образом, что с увеличением N ее объем VN уменьшается. Если при N®¥ VN®0, k®¥ и k/N®0, то оценка плотности в точке является состоятельной.
Этим условиям удовлетворяют многие виды зависимостей, например:
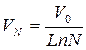 ;
; 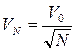 и т.д.
и т.д.
Тогда 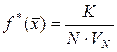
Средняя эмпирическая плотность 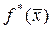 в окрестности точки используется также и для оценки плотности методом “KN ближайших соседей”. Только в отличие от метода “парзеновского окна” (где к – величина случайная) здесь “KN ближайших соседей” определяются как функция от N, причем окрестность берется таких размеров, чтобы включать ровно KN ближайших объектов.
в окрестности точки используется также и для оценки плотности методом “KN ближайших соседей”. Только в отличие от метода “парзеновского окна” (где к – величина случайная) здесь “KN ближайших соседей” определяются как функция от N, причем окрестность берется таких размеров, чтобы включать ровно KN ближайших объектов.
В зависимости от значений KN к N предъявляются аналогичные требования:
- при N®¥ необходимо, чтобы KN®¥ и KN®0, именно это обеспечивает сходимость оценки в точке ;
- при определении KN можно использовать те же функции, т.е. KN=LnN, 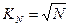 и т.д.
и т.д.
Методы “парзеновского окна” и “обобщенной гистограммы” являются
по сути дела “локальными” аналогами гистограмм, построенных соответственно при равных интервалах разбиения и при условии попадания в них примерно одинакового числа реализаций.
Основное неудобство:
- неопределенность в выборе зависимостей VN от N и KN от N;
- методы непараметрического оценивания в целом хороши только при
достаточно больших выборках (при малых выборках об их качествах трудно что-либо утверждать).
На практике часто прибегают к эвристическому конструированию
(формированию) функций плотности 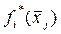 , j=1,…,n, I=1,…,m и функций P(Qi), основанному на экспертных оценках:
, j=1,…,n, I=1,…,m и функций P(Qi), основанному на экспертных оценках:
- определяется группа экспертов (веса для которых Bk, k=1,…,t),
оценивающих возможные значения признаков xj объектов всех классов;
- каждый из экспертов Ак сообщает значение признака как CK(Xj/Qi), при
этом некоторые из значений признака xj объектов класса Qi, указанные разными экспертами, могут совпадать, т.е. Cg(Xj/Qi) = Cq(Xj/Qi), g,qÎ1,…,t; кроме того некоторые эксперты могут указать на несколько возможных значений признака Xj в i-том классе Qi, т.е.:
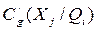 ,
, 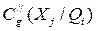 и т.д.;
и т.д.;
необходимо учитывать также, что некоторые эксперты “промолчат” (указания 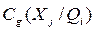 отсутствуют);
отсутствуют);
- определяется усредненный вес мнений экспертов группы L0(Xj/Qi):
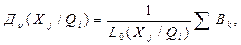
AkÎLn(Xj/Qi)
где Ln(Xj/Qi) – группа экспертов; n = 1,…,r(Xj/Qi);
L0(Xj/Qi) – число экспертов в группе Ln;
Алгоритм: группа экспертов Ln(Xj/Qi) указала, что значение признака Xj в классе Qi составляет Сn(Xj/Qi).
Следствие: Статистическая вероятность того, что значение признака Xj у объектов, принадлежащих классу Qi равна величине Сn(Xj/Qi) указанной группой экспертов Ln(Xj/Qi), пропорциональна усредненному весу мнений этой группы, т.е.:
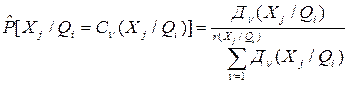
Это соотношение позволяет сформировать статистические ряды:
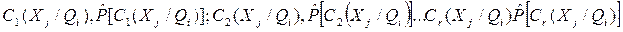
а на их основе путем сглаживания определить оценки искомых функций распределения вероятностей .
Метод определения функций P(Qi) аналогичен.
Следствие: Таким образом, эвристический подход к формированию априорных сведений основывается на обработке результатов опроса группы экспертов с учетом их авторитета (веса).
Дата добавления: 2016-01-20; просмотров: 1252;