Неконтролируемая задача с самообучением
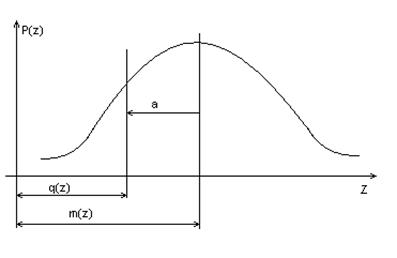
Пусть имеем дискриминантную функцию как g(x), предполагающую линейную аппроксимацию. Функция содержит априори неизвестные коэффициенты, которые в процессе самообучения подбираются таким образом, чтобы в соответствии с выбранным критерием реализовалось оптимальное разделение.
g(x) = k1×m1(x) + k2×m2(x) + … + kn×mn(x),
где mj(x) – функция, представляющая прошлый опыт, предыстория выборки;
kj – некоторые коэффициенты, определенные на интервале (0,1).
В процессе классификации значения g(x) непрерывно изменяются в зависимости от характера изменения Х во времени.
В этом случае при отсутствии априорных сведений о Р(х/а) контроль успешности классификации непосредственно невозможен.
Здесь подход: квазиоптимальное разделение на классы с неконтролируемым самообучением путем целенаправленного изменения алгоритма переработки текущей информации, основанного на ее накоплении и дальнейшего уточнения модели явления, с которым система имеет дело.
Здесь критерий – максимум правдоподобия.
Условимся: выборка состоит из независимых элементов и дисперсии обоих классов одинаковы, т.е.:
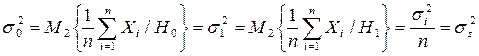
Плотность вероятности выборки Р(х/а) с независимыми элементами равна:
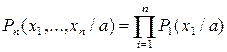 - это функция правдоподобия выборки
- это функция правдоподобия выборки
Тогда отношение правдоподобия:
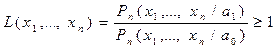
Полагая Р(х/а) – нормальный закон, получим:
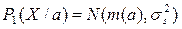
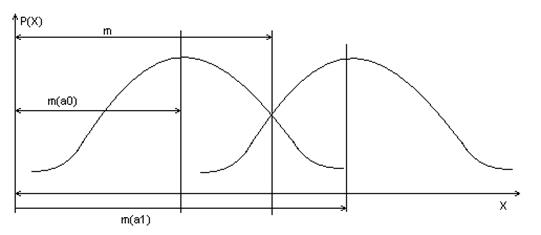
Задачу классификации решаем как построение разделяющей функции для некоторого одномерного бимодального распределения, т.е.
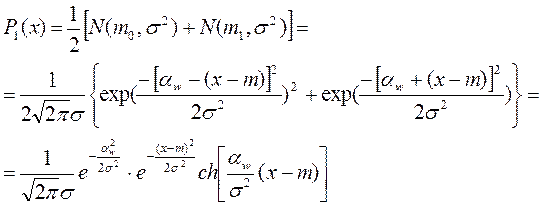
где aw = m-m0 = m1-m;
ch – гиперболический косинус.
В общем виде критерий разделения имеет вид:

Оценим максимум правдоподобия:
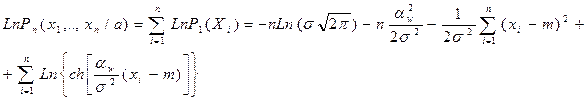
Из соотношения правдоподобия для бимодального нормального распределения получим:
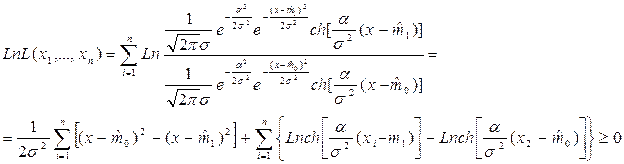
Отсюда нижняя оценка математического ожидания равна:
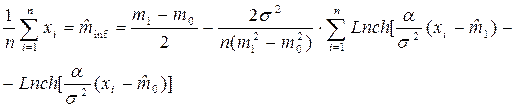
Здесь решающая процедура формирует разделяющие функции при неизвестных m1, m2, s и нефиксированной выборке эквивалентной построению оптимальной оценки 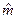 математического ожидания по выборочным значениями случайной величины Х с дисперсией:
математического ожидания по выборочным значениями случайной величины Х с дисперсией:
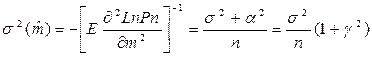
где 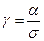 - то удаленность математических ожиданий m1 и m0 (в предположении, что s и a известны).
- то удаленность математических ожиданий m1 и m0 (в предположении, что s и a известны).
Оценка при всех значениях Х сходится к истинному значению математического ожидания и особенно эффективна при g<1, т.к. в этом случае дисперсия лишь незначительно отличаться от минимально возможной для статистической обработки, т.е.
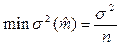
Эта оценка вычислима еще потому, что прогноз легко учитывает предысторию, т.е.
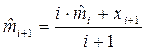
Если все параметры неизвестны, то оптимальное оценивание проблематично.
Если известно хотя бы m, то его оценка вычисляется как:
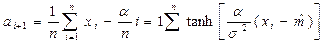
Асимптотическая дисперсия такой оценки:
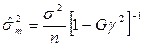 , где
, где
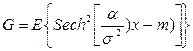 ,
,
С учетом того, что tanh с большой вероятностью P= 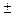 1, то:
1, то:
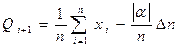 , где
, где
Dn = n1(xi³ i) – n2(xi³ i)
n1 + n2 = n.
Дата добавления: 2016-01-20; просмотров: 892;