Проблемы идентификации
При переходе от приведенной формы модели к структурной исследователь сталкивается с проблемой идентификации. Идентификация – это единственность соответствия между приведенной и структурной формами модели.
Рассмотрим проблему идентификации для случая с двумя эндогенными переменными. Пусть структурная модель имеет вид:

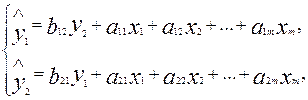
Где y1 и y2 – совместные зависимые.
Из второго уравнения можно выразить y1 следующей формулой:
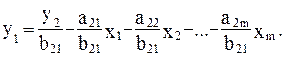
Тогда в системе имеем два уравнения для эндогенной переменной y1 с одним и тем же набором экзогенных переменных, но с разными коэффициентами при них:
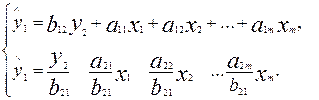
Наличие двух вариантов для лучить значения эндогеннной авит: е от параметров обычной линейной регрессии.
расчета структурных коэффициентов одной и той же модели связано с неполной ее идентификацией. Структурная модель в полном виде, состоящая в каждом уравнении системы из n эндогенных переменных, содержит n(n-1+m) параметров. Так, при n=2 и m=3 полный вид структурной модели составит:
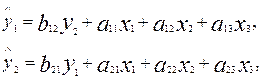 (4.3)
(4.3)
Как видим, модель содержит восемь структурных коэффициентов, что соответствует выражению n.(n-1+m).
Приведенная форма модели в полном виде содержит nm параметров. Для нашего примера это означает наличие шести коэффициентов приведенной формы модели. В этом можно убедиться, обратившись к приведенной форме модели, которая будет иметь вид:
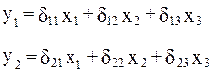
Действительно, она включает в себя шесть коэффициентов 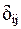 .
.
На основе шести коэффициентов приведенной формы модели требуется определить восемь структурных коэффициентов рассматриваемой структурной модели, что , естественно, не может привести к единственности решения. В полном виде структурная модель содержит большее число параметров, чем приведенная форма модели. Соответственно n*(n-1+m) параметров структурной модели не могут быть однозначно определены из nm параметров приведенной формы модели.
Чтобы получить единственно возможное решение для структурной модели, необходимо предположить, что некоторые из структурных коэффициентов модели ввиду слабой взаимосвязи признаков с эндогенной переменной из левой части системы равны нулю. Тем самым уменьшиться число структурных коэффициентов модели. Так, если предположить, что в нашей модели a13=0 и a21=0 , то структурная модель примет вид: 
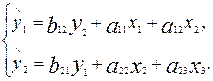 (4.4)
(4.4)
В такой модели число структурных коэффициентов не превышает число коэффициентов приведенной модели, которое равно 6. Уменьшение числа структурных коэффициентов модели
Возможно и другим путем : например, путем приравания некоторых к друг другу, т. е. путем предположений, что их воздействие на формируемую эндогенную переменную одинаково. На структурные коэффициенты могут накладываться, например, ограничения вида 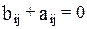 .
.
С позиции идентифицируемости структурные модели можно подразделить на три вида:
Идентифицируемые ;
Неидентифицируемые;
Сверхидентифицируемые.
Модель идентифицируемые, если все структурные ее коэффициенты определяются однозначно, единственным образом по коэффициентам приведенной формы модели, т. е. если число параметров структурной модели равно числу параметров приведенной формы модели. В этом случае структурные коэффициенты модели оцениваются через параметры приведенной формы модели и модель идентифицируема. Рассмотренная выше структурная модель (4.4) с двумя эндогенными и тремя экзогенными ( предопределенными) переменными, содержащая шесть структурных коэффициентов, представляет собой идентифицируемую модель.
Модель неидентифицируема, если число приведенных коэффициентов меньше числа структурных коэффициентов, и в результате структурные коэффициенты не могут быть оценэмы модели. ли равно числу мы модели, т. ены через коэффициенты приведенной формы модели. Структурная модель в полном виде (4.1), содержащая n эндогенных и m предопределенных переменных в каждом уравнении системы, всегда неидентифицируема.
Модель сверхидентифицируема, если число приведенных коэффициентов больше числа структурных коэффициентов. В этом случае на основе коэффициентов приведенной формы можно получить два или более значений одного структурного коэффициента. В этом модели число структурных коэффициентов меньше числа коэффициентов приведенной формы. Так, если в структурной модели полного вида (4.1) предположить нулевые значения не только коэффициентов a13 и a21 (кА в модели (4.2)), но и a22=0, то система уравнений станет сверхидентифицируемой:
 (4.5)
(4.5)
В ней пять структурных коэффициентов не могут быть однозначно определены из шести коэффициентов не могут быть однозначно определены из шести коэффициентов приведенной формы модели. Сверхидентифируемая модель в отличие от не идентифицируемой модели практически решаема, но требует для этого специальных методов исчисления параметров.
Структурная модель всегда представляет собой систему совместных уравнений, каждое из которых требуется проверять на идентификацию. Модель считается идентифицируемо. Если хотя бы одно из уравнений системы неидентифицируемой. Сверхитифицируемое уравнение.
Выполнение условия идентифицируемости модели проверяется для каждого уравнения системы. Чтобы уравнение было идентифицируемо, необходимо, чтобы число предопределенных переменных, отсутствующих в данном уравнении, но присутствующих в системе, было равно числу эндогенных переменных в данном уравнении без одного.
Если обозначить число эндогенных переменных в j-м уравнении системы через H, а число экзогенных (предопределенных) переменных, которые содержаться в системе, но не входят в данное уравнение, - через D, то условие идентифицируемости модели может быть записано в виде следующего счетного правила:
D+1=H - уравнение идентифицируемо;
D+1<H - уравнение неидентифицируемо;
D+1>H - уравнение сверхидентифицируемо.
Предположим, рассматривается следующая система одновременных уравнений:
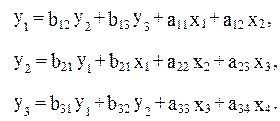 (4.6)
(4.6)
Первое уравнение точно идентифицируемо, ибо в нем присутствуют три эндогенные переменные- y1, y2, y3 т.е. H=3, и две экзогенные переменные-x1 и x2, число отсутствующих экзогенных переменных равно двум –x3 и x4, D=2. тогда имеем равенство: D+1=H, т. е. 2+1=3, что означает наличие идентифицируемого уравнения.
Во втором уравнении системы H=2 (y1 и y2) и D=1 (x4). Равенство D+1=H, т. е. 1+1=2. уравнение идентифицируемо.
В третьем уравнении системы H=3 (y1, y2, y3), a D=2 (x1 и x2). Следовательно, по счетному правилу D+1=H, и это уравнение идентифицируемо. Таким образом, система (4.6) в целом идентифицируемо. Таким образом, система (4.6) в целом идентифицируема.
Предположим, что в рассматриваемой модели a21=0 и a33=0. Тогда система примет вид:
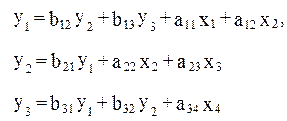 (4.7)
(4.7)
Первое уравнение этой системы не изменилось. Система по прежнему содержит три эндогенные и две экзогенные переменные, поэтому для него D=2 при H=3, и оно, как и в предыдущей системе, идентифицируемым оказывается и третье уравнение системы, где H=3 (y1, y2, y3) и D=3 (x1, x2,x3), т.е. счетное правило составляет неравенство: 3+1>3менные, де следующего счетного равила:
ющих в данном уравнении, но присут или D+1>H.
Модель в целом является сверхидентифицируемой.
Предположим, что последнее уравнение системы (4.7) с тремя эндогенными переменными имеет вид:
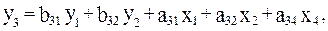
т. е. в отличие от предыдущего уравнения в него включены еще две экзогенные переменные, участвующие в системе, -x1 и x2. в этом случае уравнение становится неидентифицируемо, ибо при H=3, D=1 (отсутствует только x3) и D+1<H , 1+1<3. Итак, несмотря на то что первое уравнение идентифицируемо, второе сверхидентифицируемо, вся модель считается неидентифицируемой и не имеет статистического решения.
Для оценки параметров структурной модели система должна быть идентифицируема или сверхидентифицируема.
Рассмотренное счетное правило отражает необходимое, но недостаточное условие идентификации. Более точно условия идентификации определяются, если накладывать ограничения на коэффициенты матриц параметров структурной модели.
Уравнение идентифицируемо, если по отсутствующим в нем переменным (эндогенным и экзогенным) можно из коэффициентов при них в других уравнениях системы получить матрицу, определитель которая не равен нулю, а ранг матрицы не меньше, чем число эндогенных переменных в системе без одного.
Целесообразность проверки условия идентификации модели через определитель матрицы коэффициентов, отсутствующих в данном уравнении, но присутствующих в других, объясняется тем , что возможна ситуация, когда для каждого уравнения системы выполнено счетное правило, а определитель матрицы названных коэффициентов равен нулю. В этом случае соблюдается лишь необходимое, но недостаточное условие идентификации.
Обратимся к следующей структурной модели:
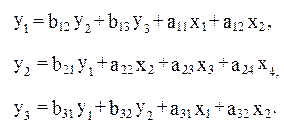 (4.8)
(4.8)
Проверим каждое уравнение системы на необходимое и достаточное условия идентификации. Для первого уравнения H=3 (y1, y2 , y3) и D=2 (x3 и x4 отсутствуют), т. е. D+1= H и необходимое условие идентификации выдержано, поэтому уравнение точно идентифицируемо. Для проверки на достаточное условие идентификации заполним следующую таблицу коэффициентов при отсутствующих в первом уравнении переменных, в которой определитель матрицы (detA) коэффициентов равен нулю:
| Уравнения | Переменные | |
| х3 | х4 | |
| а23 | а24 | |
итуация, когда для каждого уравнения системы выполнено счетное правило, а определитель матрицы называнных их в данном уравнен.
Следовательно, достаточное условие идентификации не выполняется и первое уравнение нельзя считать идентифицируемым.
Для второго уравнения H=2 (y1 и y2), D=1 (отсутствует х1) счетное парило дает утвердительный ответ: уравнение идентифицируемо (D+1=H).
Достаточное условие идентификации выполняется. Коэффициенты при отсутствующих во втором уравнении переменных составят:
| Уравнения | Переменные | |
| у3 | х1 | |
| b13 | a11 | |
| -1 | a31 |
Согласно таблице DetA ¹ 0 ранг матрицы равен 2, что соответствует следующему критерию: ранг матрицы коэффициентов должен быть не менее чем число эндогенных переменных в системе без одного. Итак второе уравнение точно идентифицируемо.
Третье уравнение системы содержит Н = 3 и D = 2, т.е. по необходимому условию идентификации оно точно идентифицируемо (D+1=H). Противоположный вывод имеем, проверив его на достаточное условие идентификации. Составим таблицу коэффициентов при отсутствующих в третьем уравнении переменных в которой detA = 0:
| Уравнения | Переменные | |
| у3 | х1 | |
| а23 | а24 |
Из таблицы видно, что достаточное условие идентификации не выполняется. Уравнение неидентифицируемо. Следовательно, рассматриваемая в целом структурная модель, идентифицируемая по счетному правилу, не может считаться идентифицируемой, исходя из достаточного условия идентификации.
В эконометрических моделях часто на ряду с уравнениями, параметры которых должны быть статистически оценены, используются балансовые тождества переменных, коэффициенты при которых равны ±1. в этом случае хотя само тождество и не требует проверки на идентификацию, ибо коэффициенты переменных в тождестве известны, в проверке на идентификацию собственно структурных уравнений системы тождества участвуют.
Например, рассмотрим эконометрическую модель экономики страны:


Где у1 – расходы на конечное потребление данного года;
у2 – валовые инвестиции в текущем году;
у3 – расходы на заработную плату в текущем году;
у4 – валовой доход за текущий год;
х1 – валовой доход предыдущий год;
х2 – государственные расходы текущего года;
А – свободный член уравнения;
e – случайные ошибки.
В этой модели четыре эндогенные переменные (у1, у2, у3, у4). Причем, переменная у4 заданна тождеством. Поэтому практически статистическое решение необходимо только для первых трех первых уравнений системы, которые необходимо проверить на идентификацию. Модель содержит две предопределенных переменных – экзогенную х2 и лаговую х1.
При практическом решении задачи на основе статистической информации за ряд лет или по совокупности регионов за один год в уравнениях эндогенных переменных у1, у2, у3 обычно содержится свободный член (А01, А02, А03), значение которого аккумулирует влияние неучтенных в уравнении факторов и не влияет на определение идентифицируемости модели.
Поскольку фактические данные об эндогенных переменных у1, у2, у3 могут отличаться от теоретических постулируемых моделью, то принято в модель включать случайную составляющую для каждого уравнения системы, исключив тождества. Случайные составляющие (возмущения) обозначены через e1, e2, и e3. Они не влияют на решение вопроса об идентификации модели.
В рассматриваемой эконометрической модели первое уравнение системы точно идентифицируемо, ибо Н = 3 и D = 2, и выполняется необходимое условие идентификации (D + 1 = H). Кроме того, выполняется и достаточное условие идентификации, т.е. ранг матрицы равен 3, а определитель ее равен 0: detА равен –а31 что видно в следующей таблице:
| Уравнения | у2 | х1 | х2 |
| -1 | а21 | ||
| –а31 | |||
Второе уравнение системы также точно идентифицируемо: Н=2 и D=1, т.е. счетное правило выполнено: D + 1 = H, также выполнено достаточное условие идентификации: ранг матрицы равен 3 и detА равен –b34:
| Уравнения | у2 | х1 | х2 |
| -1 | b14 | ||
| b34 | |||
| -1 |
Аналогично третье уравнение системы также идентифицируемо: Н=2 и D=1, D + 1 = H и detА ¹ 0, а ранг матрицы А = 3 и detА = 1:
| Уравнения | у2 | х1 | х2 |
| -1 | |||
| -1 | |||
Идентификация уравнений достаточно сложна и не ограничивается только выше изложенным. На структурные коэффициенты модели могут накладываться и другие ограничения, например, в производственной функции сумма эластичностей может быть равна по предложению 1. Могут накладываться ограничения на дисперсии и ковариации остаточных величин.
Косвенный, двухшаговый и трехшаговый метод наименьших квадратов, общая схема алгоритма расчетов. Применение эконометрических моделей. Модель Кейнса (статистическая и динамическая формы). Модель Клейна.
Коэффициент структурной модели могут быть оценены разными способами в зависимости от вида системы одновременных уравнений. Наибольшее распространение в литературе получили следующие методы оценивание коэффициентов структурной модели:
· косвенный метод наименьших квадратов;
· двухшаговый метод наименьших квадратов;
· трехшаговый метод наименьших квадратов;
· метод максимального правдоподобия с полной информацией;
· метод максимального правдоподобия при ограниченной информации.
Косвенный и двухшаговый метод наименьших квадратов подробно описаны в литературе и рассматриваются как традиционные методы оценки коэффициентов структурной модели. Эти методы достаточно легко реализуемы. Косвенный метод наименьших квадратов (КМНК) применяется для идентифицируемой системы одновременных уравнений, а двухшаговый метод наименьших квадратов (ДМНК) используется для оценки коэффициентов сверхидентифицируемой модели. Перечисленные методы оценивания также используют для сверхидентифицируемых систем уравнений.
Метод максимального правдоподобия рассматривается как наибелее общий метод оценивания, результаты которого при нормальном распределении признаков совпадают с МНК. Однако при большом числе уравнений системы этот метод приводит к достаточно сложным вычислительным процедурам. Поэтому в качестве модификации используется метод максимального правдоподобия при ограниченной информации (метод наименьшего дисперсионного отношения), разработанный в 1949г. Т. Андерсоном и Н. Рубинным. Математическое описание метода дано, например, в работе Дж. Джонстона.
В отличие от метода максимального правдоподобия в данном методе сняты ограничения на параметры, связанные с функционированием системы в целом. Это делает решение более простым, но трудоемкость вычислений остается достаточно высокой. Несмотря на его значительную популярность, к середине 60-х годов он был практически вытеснен двухшаговым методом наименьших квадратов (ДМНК) в связи с гораздо большей простой последнего. Этому способствовала также разработка в 1961 г. Г. Тейлом семейства оценок коэффициентов структурной модели. Для структурной модели Г. Тейл определил семейство оценок класса К и показал, что оно включает три важных оператора оценивания: обычный МНК при К=0, ДМНК при К=1 и метод ограниченной информации при limK=1. В последнем случае решение структурной модели соответствует оценкам ДМНК.
Дальнейшим развитием ДМНК является трехшаговый МНК (ТМНК), предложенный в 1962 г. А. Зельнером и Г. Тейлом. Этот метод оценивания пригоден для всех видов уравнений структурной модели. Однако при некоторых ограничениях на параметры более эффективным оказывается ДМНК. С концепцией данного метода можно ознакомиться в работе Дж. Джонстона. Он позволяет получить оценки с учетом взаимосвязи уравнений.
Косвенный метод наименьших квадратов (КМНК)
Как уже отмечалось, КМНК применяется в случае точно идентифицируемой структурной модели. Процедура применения КМНК предполагает выполнения следующих этапов работы:
1. Структурная модель преобразовывается в приведенную форму модели.
2. Для каждого уравнения приведенной формы модели обычным МНК оценивается приведенные коэффициенты (dij).
3. Коэффициенты приведенной формы модели трансформируются в параметры структурной модели.
Рассмотрим применение КМНК для простейшей идентифицируемой эконометрической модели с двумя эндогенными и двумя экзогенными переменными:
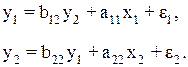
Пусть для построения данной модели мы располагаем некоторой информацией по регионам:
| Регион | у1 | у2 | х1 | х2 |
| Средние | 6,2 | 2,4 | 3,4 |
Приведенная форма модели составит:
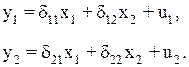
где u1, u2 – случайные ошибки приведенной формой модели.
Для каждого уравнения приведенной формы модели применяем традиционный МНК и определяем d-коэффициенты. Чтобы упростить процедуру расчетов, можно работать с отклонениями от средних уровней, т.е.  и
и  . Тогда для первого уравнения приведенной формы модели система нормальных уравнений составит:
. Тогда для первого уравнения приведенной формы модели система нормальных уравнений составит:
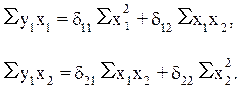
Применительно к рассматриваемому примеру, используя отклонения от средних уровней, имеем:

Решая данную систему, получим следующее первое уравнение приведенной формой модели:
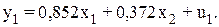
Аналогично применяем МНК для второго уравнения приведенной формой модели, получим:

Система нормальных уравнений составит:
Применительно к нашему примеру имеем:
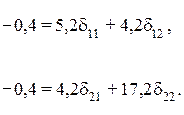
Откуда второе приведенное уравнение составит:
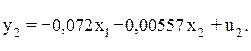
Таким образом, приведенная форма модели имеет вид:
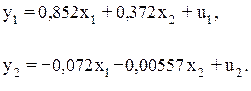
Переходим от приведенной формой модели к структурной форме модели, т.е. к системе уравнений:
Для этой цели из первого уравнения приведенной формой модели надо исключить х2, выразив его из второго уравнения приведенной формой и подставив в первое:

Тогда 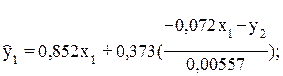
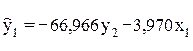 - первое уравнение структурной модели.
- первое уравнение структурной модели.
Чтобы найти второе уравнение структурной модели, обратимся вновь к приведенной форме модели. Для этой цели из второго уравнения приведенной формой модели следует исключить х1, выразив его через первое уравнение приведенной формой и подставив в второе:
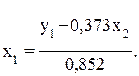
и 
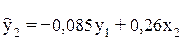 - второе уравнение структурной модели.
- второе уравнение структурной модели.
Итак, структурная форма модели имеет вид:
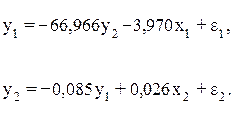
Эту же систему можно записать, включив в нее свободный член уравнения, т.е. перейти от переменных в виде отклонений от среднего уровня к исходным переменным у и х.
Свободные члены уравнений определим по формулам:
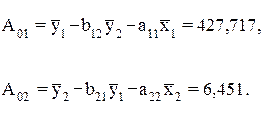
Тогда структурная модель имеет вид:
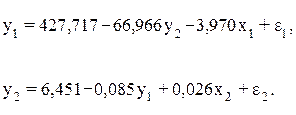
При обработке по программе DSTAT система приведенных уравнений отсутствует, сразу же выдается структурная модель.
Оценка значимости модели дается через F-критерий и R2 для каждого уравнения в отчетности. В рассматриваемом примере хороших результатов достичь не удалось: ввиду малого числа наблюдений значения F-критерия Фишера несущественны (при уровне значимости 0,005 F-табличное значение равно 19, а фактическое F=7 для первого уравнения).
Если к каждому уравнению структурной формой модели применить традиционный МНК, то результаты будут резко отличаться:
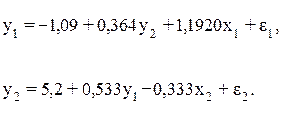
Как видим, не совпадают даже знаки коэффициентов при переменных: в первом уравнении структурной формы коэффициенты меньше нуля, а в уравнении регрессии больше нуля; во втором уравнении обратное воздействие у1 на у2 в структурной модели сменяется на прямое в уравнении регресс, а с фактором х2 наоборот.
Различия между коэффициентами регрессии и структурными коэффициентами модели численно могут быть и не менее существенными. Так, например, Г. Тинтнер, рассматривая статическую модель Кейнса для австрийской экономики за 1948-1956 гг., получил функцию потребления классическим МНК в виде С = 0,782у + 71,6, а используя КМНК,
С = 0,7812у + 73,212.
При сравнении результатов, полученных традиционным МНК и с помощью КМНК, следует иметь в виду, что традиционный МНК, применяемый к каждому уравнению структурной формы модели, взятому в отдельности, дает смещенные оценки структурных коэффициентов. Как показал Т. Хаавельмо, рассматривая две взаимосвязанные регрессии:
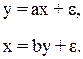
коэффициент регрессии отличается от структурного коэффициента и совпадает с ним только в одном частном случае, когда переменная у не содержит ошибок (т.е. e1 = 0), а ошибки переменной х имеет дисперсию, равную единице.
Кроме того, при интерпретации коэффициентов множественной регрессии предполагается независимость факторов друг от друга, что становится невозможным при рассмотрении системы совместных уравнений. Так, в нашем примере уравнение регрессии 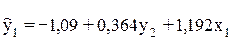 показывает, что с ростом х1 на единицу у1 возрастает в среднем на 1,192 ед. при неизменном уровне значения у2. Между тем в соответствии с системой одновременных уравнений переменная у2 не может быть неизменной, ибо она в свою очередь зависит от у1.
показывает, что с ростом х1 на единицу у1 возрастает в среднем на 1,192 ед. при неизменном уровне значения у2. Между тем в соответствии с системой одновременных уравнений переменная у2 не может быть неизменной, ибо она в свою очередь зависит от у1.
Нарушение предпосылки независимости факторов друг от друга при использовании традиционного МНК в системе одновременных уравнений приводит к несостоятельности оценок структурных коэффициентов; в ряде случаев они оказываются экономически бессмысленными. Опасность таких результатов возрастает при увеличении числа эндогенных переменных в правой части системы, ибо становится невозможным расщепить совместное влияние эндогенных переменных и видеть изолированные меры их воздействия в соответствии с предпосылками традиционного МНК.
Компьютерная программа применения МНК предполагает, что система уравнений содержит в правой части в каждом уравнений как эндогенные, так и экзогенные переменные. Так в п. 4.3. рассматривалась модель экономики страны с четырьмя эндогенными и двумя экзогенными переменными, в которой в первом уравнении системы не содержалось не одной экзогенной переменной. Для такой модели непосредственное получение структурных коэффициентов невозможно. В этом случае сначала определяется система приведенной формы модели, решаемая обычным МНК, а затем путем алгебраических преобразований переходят к коэффициентам структурной модели.
Двухшаговый метод наименьших квадратов (ДМНК)
Если система сверхидентифицируема, то КМНК не используется, ибо он не дает однозначных оценок для параметров структурной модели. В этом случае могут использоваться разные методы оценивания, среди которых наиболее распространенным и простым является Двухшаговый метод наименьших квадратов (ДМНК).
Основная идея ДМНК – на основе приведенной формы модели получить для сверхидентифицируемого уравнения теоретические значения эндогенных переменных, содержащихся в правой части уравнения.
Далее, поставив их вместо фактических значений, можно применить обычный МНК к структурной форме сверхидентифицируемого уравнения. Метод получил название двухшагового МНК, ибо дважды используется МНК: на первом шаге при определении приведенной формы модели и нахождении на ее основе оценок теоретических значений эндогенной переменной 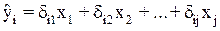 и на втором шаге применительно к структурному сверхиудетифицируемому уравнению при определении структурных коэффициентов модели по данным теоретических (расчетных) значений эндогенных переменных.
и на втором шаге применительно к структурному сверхиудетифицируемому уравнению при определении структурных коэффициентов модели по данным теоретических (расчетных) значений эндогенных переменных.
Сверхидетифицируемая структурная модель может быть двух типов:
· все уравнения системы сверхидетифицируемы;
· система содержит наряду со сверхидетифицируемыми точно идентифицируемые уравнения.
Если все уравнения системы сверхиудетифицируемые, то для оценки структурных коэффициентов каждого уравнения используется ДМНК. Если в системе есть точно идентифицируемые уравнения, то структурные коэффициенты по ним находятся из системы приведенных уравнений
Применим ДМНК к простейшей сверхидетифицируемой модели:
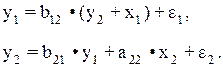
Данная модель может быть получена из предыдущей идетифицируемой модели:
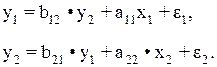
если наложить ограничения на ее параметры, а именно:
b12 = a11.
В результате первое уравнение стало сверхидетифицируемым: Н = 1 (у1), D = 1 (х2) и D + 1 > H. Второе уравнение не изменилось и является точно идентифицируемым: Н = 2, D = 1 и D + 1 = H.
На первом шаге найдем приведенную форму модели, а именно:
Предполагая использование тех же исходных данных, что и в предыдущем примере, получим ту же систему приведенных уравнений:
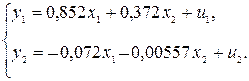
На основе второго уравнения данной системы можно найти теоретические значения для эндогенной переменной у2, т.е. 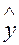 . С этой целью в уравнение
. С этой целью в уравнение 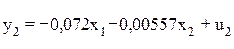 поставляем значения х1 и х2 (в нашем примере это отклонения от средних уровней). Оценки для эндогенной переменной у2 приведены в таблице:
поставляем значения х1 и х2 (в нашем примере это отклонения от средних уровней). Оценки для эндогенной переменной у2 приведены в таблице:
Дата добавления: 2016-05-16; просмотров: 1541;