Выбор функции. Тесты Бокса-Кокса.
Возможность построения нелинейных моделей, как с помощью их приведения к линейному виду, так и путем использования нелинейной регрессии, значительно повышают универсальность регрессионного анализа, но и усложняют задачу исследователя.
Если вы ограничиваетесь парным регрессионным анализом, то можно построить поле корреляции, график y(x) как диаграмму разброса. Однако обычно все не так просто. Часто несколько разных нелинейных функций соответствуют наблюдениям, если они лежат на некоторой кривой.
При рассмотрении альтернативных моделей с одним и тем же определением зависимой переменной процедура выбора достаточно проста. Наиболее разумным является оценивание регрессии на основе всех вероятных функций, которые можно вообразить, и выбор функции, в наибольшей степени объясняющей изменения зависимой переменной.
Если в примере мы получили, что линейная функция объясняет 64% дисперсии «у», а гиперболическая – 99,9%, то без колебаний (R2yx) выбираем последнюю.
Однако разные модели используют разные функциональные формы, то проблема выбора модели становится более сложной, так как нельзя непосредственно сравнить коэффициенты R2yx или суммы квадратов отклонений, т.е нельзя сравнивать статистически для линейного и логарифмических вариантов модели
Еще пример:
Линейная регрессия R2 = 0,985. СКО= 385,2
Двойная логарифмическая модель R2 = 0,9915, СКО = 0,02
Во втором случае СКО значительно меньше, но это ничего не решает. Значение log y< значительно меньше соответствующих значений у, поэтому и остатки меньше. Величина R2 безразмерна и во втором уравнении относится к разным понятиям. Во первом измеряет объясненную регрессией долю дисперсии, во втором - объясненную регрессией долю дисперсии log y. Если для одной модели R2 значительно больше, чем для другой, можно сделать оправданный выбор. Если же R21 @ R22 то проблема выбора усложняется. Для этого используют тест Бокса-Кокса.
Сравнения у и log y использует вариант теста, разработанного Полном Зарембой. Он предположил такое преобразование масштаба наблюдений у, при котором обеспечивалась бы возможность непосредственного сравнения СКО в линейной и логарифмической моделях. Процедура заключается в следующем:
1. Вычисляется среднее геометрическое значение у в выборке ( оно совпадает с экспонентой среднего арифметического log y, поэтому если вы уже оценили логарифмическую регрессию, то необходимо вычислить лишь экспоненту от этого значения).
2. Пересчитываются наблюдения у, они делятся на это значение, т.е (масштабируется):
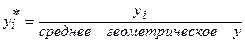
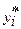 - пересчитанное значение для i наблюдения.
- пересчитанное значение для i наблюдения.
3. Оценивается регрессия для линейной модели с использованием вместо у в качестве зависимой переменной и для логарифмической модели с использованием log ( ) вместо log(у); во всех других отношениях модели должны оставаться неизменными. Теперь, значение СКО для двух регрессий сравнимы, и следовательно, модель с меньшей суммой квадратов отклонений обеспечивает лучше соответствующее.
4. Для того, чтобы проверить, не обеспечивает ли одна из моделей значимо лучше соответствующее можно вычислить величину 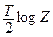 , где Т- число наблюдений, Z- отношение значений СКО в пересчитанных регрессий, и взять ее абсолютное значение (т.е игнорировать знак «-» если он имеется.). Эта статистика имеет распределение c2 с одной степенью свободы. Если она превышает критерий- значение c2 при выбранном уровне значимости, то делается вывод о наличии значимой разницы в качестве оценивания.
, где Т- число наблюдений, Z- отношение значений СКО в пересчитанных регрессий, и взять ее абсолютное значение (т.е игнорировать знак «-» если он имеется.). Эта статистика имеет распределение c2 с одной степенью свободы. Если она превышает критерий- значение c2 при выбранном уровне значимости, то делается вывод о наличии значимой разницы в качестве оценивания.
Пример: тест о расходах на продукты питания так и расходах на жилье в США. Для этих двух видов благ показали, что логарифмическая регрессия – среднее значение log(у) = 4,8422 (1) и 4,6662 (2). Масштабирующие множители равны e4.8422 и e4,6662
| СКО | расходы на питание | расходы на жилье |
| линейная регрессия | 0,0119 | 0,0341 |
| двойная логарифмическая регрессия. | 0,0119 | 0,0221 |
Из таблицы очевидно, что для регрессии расходов на питание соответствие одинаково хорошо в обоих случаях. В случае расходов на жилье, логарифмическая регрессия дает более точное соответствие логарифмического отношения значений СКО для вторых регрессией = 0,4337, и после умножения на 12,5 регрессий t = 4,52. Критерий- уровень c2 с одной степенью свободы составит 3,84 при 5% уровне значимости и 6,64 при 1%.
Эти результаты могут показаться неожиданными, так как можно предположить, что с точки зрения теории модель с log является более совершенной. Однако период выборки настолько мал, что кривизна функции Энгеля, вероятно не успеет проявиться, поэтому линейная функция может обеспечить столь же хорошее соответствие, что и нелинейная.
Дата добавления: 2016-05-16; просмотров: 1635;