Основные случайные величины
Любой сходящийся интеграл от неотрицательной функции порождает непрерывное распределение. Именно, если 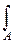 j(x)dx=I, то роль плотности играет
j(x)dx=I, то роль плотности играет
|
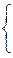
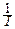 j(x), если xÎA,
j(x), если xÎA,0, если xÏA.
Любая конечная сумма или сходящийся ряд с неотрицательными слагаемыми порождает дискретное распределение. Именно: если 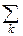 qk=S, то роль дискретных вероятностей играют pk=
qk=S, то роль дискретных вероятностей играют pk= 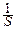 qk, а в качестве xkможно взять любые числа; наиболее простой выбор: xk=k.
qk, а в качестве xkможно взять любые числа; наиболее простой выбор: xk=k.
Рассмотрим конкретные примеры.
1°. Равномерное распределение. Его порождает интеграл 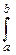 dx=b-a.
dx=b-a.
|
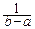 , если xÎ[a, b],
, если xÎ[a, b],0, если xÏ[a, b].
Этот закон распределения будем обозначать R(a, b); числа a и b называются параметрами распределения. Тот факт, что случайная величина X равномерно распределена на отрезке [a, b], будем обозначать следующим образом: X~R(a, b).
В частности, плотность случайной величины X~R(0, 1) имеет наиболее простой вид:
|
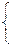
0, если xÏ[0, 1].
Функция распределения такой случайной величины равна:
|
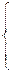
x, если 0£x£1,
1, если x>0.
Если мы наугад выбираем точку на отрезке [0, 1], то её абсцисса x является конкретным значением случайной величины X~R(0, 1). Слово ''наугад" имеет в теории вероятностей терминологическое значение и говорится с целью подчеркнуть, что соответствующая непрерывная случайная величина распределена равномерно, или дискретная случайная величина имеет конечное число N возможных равновероятных значений.
2°. Экспоненциальное распределение.
Его порождает интеграл 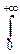 e-mxdx=
e-mxdx= 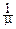 , m>0.
, m>0.
|
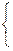
me-mx, если x³0,
0, если x<0,
|
1-me-mx, если x³0,
0, если x<0.
То обстоятельство, что случайная величина распределена по экспоненциальному закону, будем записывать так: X~Exp(m), m называется параметром распределения (m>0).
3°. Распределение Коши. Его порождает интеграл 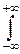
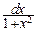 dx=p.
dx=p.
Плотность вероятности: p(x)= 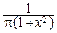 , -¥<x<+¥.
, -¥<x<+¥.
4°. Гамма-распределение. Его порождает интеграл, который определяет гамма-функцию: G(l)= e-ttl-1dt, l>0. Выполним в этом интеграле замену переменной, положим: t=mx, m>0:
G(l)=ml e-mxxl-1dx.
|
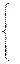
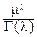 xl-1e-mx, если x>0,
xl-1e-mx, если x>0,
0, если x£0.
Будем обозначать это распределение G(l, m), l и m – параметры распределения (l>0, m>0).
5°. Нормальное распределение. Его порождает интеграл Пуассона:
I= 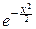 dx=
dx= 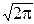 .
.
Докажем это равенство. Интеграл бы легко вычислялся, если бы подынтегральное выражение содержало множитель x. Такой множитель можно ввести под знак интеграла с помощью следующего остроумного приёма.
Запишем квадрат интеграла в следующем виде:
I2= dx× 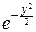 dy,
dy,
а теперь представим произведение интегралов как двойной интеграл:
I2= 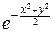 dxdy.
dxdy.
Перейдём в этом интеграле к полярным координатам. Положим: x=rcosj, y=
=rsinj, и ещё вспомним, что абсолютная величина якобиана при переходе от декартовых координат к полярным равна r. Заметим, наконец, что областью интегрирования двойного интеграла является вся плоскость, так что границы изменения переменных r и j, соответственно, таковы: rÎ[0; +¥), jÎ[0; 2p). Поэтому:
I2= 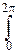 dj
dj 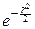 rdr.
rdr.
Теперь легко убедиться, что rdr=1, а потому I2=2p.
Распределение с плотностью
p(x)= 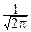 , xÎ(-¥; +¥)
, xÎ(-¥; +¥)
называется стандартным нормальным законом и обозначается N(0, 1).
Ему соответствует функция распределения:
F0(x)= 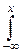 dx.
dx.
Обычно принято табулировать интеграл
F(x)= 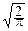
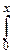 dx,
dx,
называемый интегралом ошибок или интегралом Лапласа. Функция распределения стандартного нормального закона просто выражается через этот интеграл:
F0(x)= 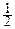 + F(x).
+ F(x).
Если в интеграл Пуассона ввести параметры масштаба и сдвига с помощью замены переменной, заменив x на 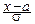 , то он примет вид:
, то он примет вид:
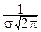
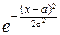 dx=1.
dx=1.
Случайную величину с плотностью вероятности
p(x)= , xÎ(-¥; +¥),
называют нормально распределённой случайной величиной или просто нормальной. Соответствующий ей закон распределения обозначают N(a, s), a и s – параметры распределения (s>0, a – любое вещественное число).
График p(x) представлен на рис. 1.
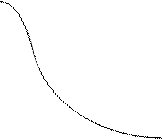     
|
a – точка максимума p(x), его значение равно . Так как площадь под кривой всегда равна единице, то чем меньше s, тем больше вероятности сосредоточивается вблизи максимума. Таким образом, устанавливаем вероятностный смысл параметров нормального закона: областью наиболее вероятных значений нормальной случайной величины является окрестность точки a, а s указывает на степень концентрации вероятности в окрестности точки a – чем меньше s, тем менее вероятны заметные отклонения X от a.
Функцию распределения произвольного нормального закона легко выразить через интеграл Лапласа. Для этого нужно в выражении для функции распределения
F(x)= dx
выполнить замену переменной, положив =y:
F(x)= 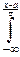 dy= + F(
dy= + F( 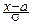 ).
).
6°. Геометрическое распределение. Его порождает геометрическая прогрессия: 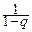 =
= 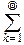 qk-1, 0<q<1.
qk-1, 0<q<1.
Соответствующая дискретная случайная величина имеет возможные значения xk=k, k=1, 2, ¼ с вероятностями pk=(1-q)qk-1. Обозначение геометрического распределения: G(q), q – параметр распределения (0<q<1).
7°. Пуассоновское распределение. Его порождает разложение в ряд показательной функции: el= 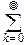
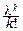 , l>0, которому отвечает дискретная случайная величина, принимающая целые неотрицательные значения xk=k, k=0, 1, 2, ¼ с вероятностями pk=
, l>0, которому отвечает дискретная случайная величина, принимающая целые неотрицательные значения xk=k, k=0, 1, 2, ¼ с вероятностями pk= 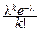 .
.
Будем обозначать это распределение через P(l), l – параметр распределения (l>0).
8°. Биномиальное распределение. Его порождает формула бинома Ньютона: (p+q)n= 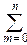
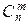 pmqn-m.
pmqn-m.
Чтобы сумма вероятностей распределения pkравнялась единице и все они были положительными, возьмём p>0, q>0, p+q=1, т. е. q=1-p. Возможными значениями будем считать xk=k, k=0, 1, 2, ¼ , n, а их вероятностями – pk= 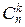 pkqn-k. Обозначим это распределение B(n, p), n и p – параметры распределения (0<p<1, nÎN, т. е. n – натуральное число).
pkqn-k. Обозначим это распределение B(n, p), n и p – параметры распределения (0<p<1, nÎN, т. е. n – натуральное число).
Биномиальная случайная величина появляется, например, в схеме Бернулли, называемой также схемой последовательных независимых испытаний. Состоит она в следующем: осуществляется некоторый комплекс условий, при котором мы имеем одно и только одно из двух событий: либо "успех", либо "неудачу", причём вероятность "успеха" равна p, вероятность "неудачи" равна q=
=1-p; эта попытка независимым образом повторяется n раз. Считая опытом все n попыток, можем считать элементарным событием опыта цепочку длины n, полученных в результате опыта "успехов" (У) и "неудач" (Н): УУУННУ
Н¼У.
Определим случайную величину X, задав её как число успехов в одном опыте. Событию {X=k} благоприятствуют те элементарные события, которые содержат "успех" ровно k раз, а "неудачу" – остальные n-k раз. Число таких благоприятствующих событию {X=k} элементарных событий, равно, очевидно, , а вероятности всех их одинаковы и по теореме умножения для независимых событий равны pkqn-k. Окончательно получаем: P{X=k}= pkqn-k, а возможными значениями случайной величины X оказываются числа xk=k, k=
=0, 1, 2, ¼ n. Таким образом, число успехов X в схеме Бернулли – биномиальная случайная величина: X~B(n, p).
Пусть имеется вероятностное пространство (W, Å, P(×)) и рассматривается некоторое событие A. Обозначим его вероятность P(A)=p. Пусть испытание независимым образом повторяется n раз, причём событие A в этих n последовательных попытках наблюдалось k раз. Число k называется абсолютной частотой события A. Оно является конкретным значением случайной величины X, определённой на серии из n независимых испытаний. Ничто не мешает объявить событие A "успехом", а событие 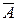 – "неудачей". Это превращает последовательность из n испытаний в схему Бернулли, а абсолютная частота события A оказывается распределённой по закону Бернулли.
– "неудачей". Это превращает последовательность из n испытаний в схему Бернулли, а абсолютная частота события A оказывается распределённой по закону Бернулли.
Геометрическое распределение также просто связано со схемой Бернулли: будем повторять попытку до появления первого "успеха". Элементарным событием в таком опыте является цепочка, у которой "успех" расположен только на последнем (k-м) месте, а на всех предыдущих местах (а их k-1) – только "неудачи": ННННН¼НУ. Свяжем с этим опытом случайную величину X – общее число попыток в опыте. Очевидно, значениями этой случайной величины могут быть xk=k, k=1, 2, 3, ¼ , а их вероятности pk=qk-1p, что и совпадает с геометрическим распределением G(p).
Дата добавления: 2017-09-19; просмотров: 567;