Числовые характеристики случайных величин: математическое ожидание, дисперсия, коэффициент корреляции
Наиболее полная информация о случайной величине содержится в законе её распределения. Более бедную, но зато и более конкретную информацию о ней дают её числовые характеристики. Простейшей из них является математическое ожидание, которое интерпретируется как среднее значение случайной величины. Если посмотреть на закон распределения как на распределение единичной вероятностной массы между значениями случайной величины, то в качестве среднего значения можно взять координаты центра тяжести этой массы. По известным из анализа и механики формулам получаем формулы для вычисления абсциссы центра тяжести:
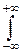 xp(x)dx – в непрерывном случае,
xp(x)dx – в непрерывном случае,
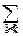 xkpk– в дискретном случае.
xkpk– в дискретном случае.
Для того, чтобы дать определение, пригодное и для общего случая, необходимо обобщить понятие риманова интеграла.
Сделаем поэтому небольшое математическое отступление.
––²––
Интеграл Стилтьеса
Интеграл Стилтьеса определяется для двух функций: одна из них j(x) – называется интегрируемой, другая F(x) – интегрирующей. Разобьём всю ось на интервалы Dtk: [tk, tk+1), относя для определённости к интервалу левый конец и исключая правый. В каждом интервале выберем произвольно точку xkи составим интегральную сумму
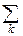 j(xk)[F(tk+1)-F(tk)].
j(xk)[F(tk+1)-F(tk)].
Перейдём к пределу, устремив наибольший из интервалов к нулю. Если предел существует и не зависит ни от способа разбиения оси на интервалы, ни от способа выбора точек xkна них, то он называется интегралом Стилтьеса от функции j(x) по функции F(x) и обозначается: j(x)dF(x).
Легко убедиться в том, что обычные свойства интеграла сохраняются: постоянный множитель можно выносить за знак интеграла, интеграл от суммы равен сумме интегралов.
Интеграл Римана является частным случаем интеграла Стилтьеса для F(x)=x.
Рассмотрим два частных случая:
a. F(x) – ступенчатая функция, имеющая в точках xiскачки величины piи постоянная между этими точками. Приращения F(tk+1)-F(tk) на тех интервалах Dtk, которые не содержат точек разрыва функции F(x), равны нулю; если же точка xiявляется единственной точкой разрыва F(x), содержащейся в интервале Dtk, то разность F(tk+1)-F(tk) равна pi. Считая, что все точки разрыва изолированные, при переходе к пределу получим: j(x)dF(x)= 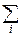 j(xi)pi.
j(xi)pi.
b. F(x) – дифференцируемая функция: существует производная F¢(x)=p(x). В интегральной сумме для интеграла Стилтьеса j(xk)[F(tk+1)-F(tk)] каждую из разностей [F(tk+1)-F(tk)] заменим по формуле Лагранжа: на каждом промежутке Dtkнайдётся такая точка hk, в которой F(tk+1)-F(tk)=F¢(hk)=
=p(hk)Dtk; пользуясь произволом в выборе точек xkиз промежутка Dtk, возьмём в каждом слагаемом интегральной суммы xk=hkи тогда сумма примет вид:
j(hk)p(hk)Dtk,
а это – ни что иное, как риманова интегральная сумма для функции j(x)p(x). Поэтому:
j(x)dF(x)= j(x)p(x)dx.
В теории вероятностей интеграл Стилтьеса оказался удобным средством объединения случаев непрерывного и дискретного распределений в общем случае.
––²––
Вернёмся к изучению числовых характеристик случайных величин.
1°. Выше мы ввели понятие математического ожидания для дискретной и непрерывной случайных величин.
Пусть теперь X – случайная величина с функцией распределения F(x). Возьмём произвольную функцию j(x).
Назовём математическим ожиданием функции j от случайной величины X число Mj(X), определяемое равенством:
Mj(X)= j(x)dF(x).
В частности, для непрерывной случайной величины с плотностью вероятности p(x) получаем:
Mj(X)= j(x)p(x)dx,
а для дискретной случайной величины с распределением pk=P{X=xk}:
Mj(X)= j(xk)pk.
В случае, когда j(x)=x, последние три формулы принимают вид:
MX= xdF(x) – в общем случае,
MX= xp(x)dx – в непрерывном случае,
MX= xkpk– в дискретном случае.
Формулы для непрерывного и дискретного случаев совпали с формулами для абсциссы центра тяжести распределения вероятностной массы, и тем самым оправдывается истолкование математического ожидания случайной величины X как среднего значения.
Для корректности определения математического ожидания следует обсудить вопрос о его существовании и единственности.
Вопрос о единственности Mj(X) возникает потому, что j(X) сама является случайной величиной со своей функцией распределения Fj(x) и в соответствии с нашим определением её математическое ожидание равно xdFj(x).
Для однозначности определения необходимо выполнение равенства
j(x)p(x)dx= xdFj(x)
и такое равенство действительно можно доказать: оно даёт правило замены переменных в интеграле Стилтьеса. Мы здесь вынуждены принять его без доказательства.
Вопрос о существовании математического ожидания: ясно, что в непрерывном и дискретном случае любая ограниченная случайная величина имеет математическое ожидание. Если же X может принимать сколь угодно большие значения, то в дискретном случае сумма, определяющая MX, становится бесконечным рядом, а в непрерывном – интеграл становится несобственным, причём оба могут расходиться. Очевидно, в непрерывном случае достаточным условием существования среднего значения у случайной величины является
p(x)=O( 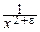 ) при x®±¥ (e>0),
) при x®±¥ (e>0),
а в дискретном случае:
xkpk=O( 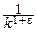 ) при k®¥ (e>0).
) при k®¥ (e>0).
Однако оба эти условия не являются необходимыми.
Легко также придумать примеры случайных величин, не имеющих среднего. Для непрерывного случая таким примером может служить распределение Коши. В дискретном подобный пример придумать ещё проще, если учесть, что вероятность pkможно приписать сколь угодно большим числам xk.
Если дана двумерная случайная величина (X, Y), то математическое ожидание функции j(X, Y) определяется равенствами
Mj(X, Y)= j(x, y)p(x, y)dxdy – в непрерывном случае
(интеграл берётся по всей плоскости),
Mj(X, Y)= 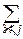 j(xi, yj)pij– в дискретном случае
j(xi, yj)pij– в дискретном случае
(сумма берётся по всем возможным значениям
двумерной случайной величины).
2°. Второй по важности числовой характеристикой случайной величины X служит её дисперсия DX. Дисперсией называется
DX=M[(X-MX)2]= (x-MX)2dF(x),
т. е. среднее значение квадрата отклонения случайной величины от её среднего. Эта формула в непрерывном случае переходит в
DX= (x-MX)2p(x)dx,
а в дискретном в:
DX= (xk-MX)2pk.
Если среднее есть не у всех случайных величин, то дисперсия и подавно. В дальнейшем все теоремы о MX и DX без особых оговорок формулируются лишь для тех X, которые их имеют.
Размерность дисперсии равна квадрату размерности случайной величины X. Поэтому иногда удобно вместо DX рассматривать величину sX= 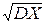 , называемую средним квадратичным отклонением случайной величины X или просто стандартом.
, называемую средним квадратичным отклонением случайной величины X или просто стандартом.
Дисперсия и стандарт мыслятся как меры разброса значений случайной величины вокруг её среднего.
3°. Докажем несколько простых утверждений:
Математическое ожидание постоянной C равно C: MC=C.
Постоянный множитель можно выносить за знак математического ожидания:
M(CX)=CMX.
Дисперсия постоянной равна нулю: DC=0.
Постоянный множитель выносится за знак дисперсии в квадрате:
D(CX)=C2DX.
Постоянную C можно рассматривать как частный случай дискретной случайной величины, принимающей единственное значение C с вероятностью, равной 1. Поэтому MC=C×1=C.
Свойство M(CX)=CMX следует из определения математического ожидания как предела интегральных сумм: постоянный множитель можно выносить за знак суммы и знак интеграла.
О дисперсии:
DC=M[(C-MC)2]=M[(C-C)2]=M0=0;
D(CX)=M[(CX-M(CX))2]=M[(CX-CM(X))2]=
=M[C2(C-MC)2]=C2×M[(X-MX)2]=C2DX.
4°. Математическое ожидание суммы случайных величин равно сумме их математических ожиданий:
M(X+Y)=MX+MY.
Докажем эту теорему отдельно для непрерывного и дискретного случая.
a. Непрерывный случай. Пусть p(x, y) – двумерная плотность вероятности.
Согласно определению математического ожидания функции от двумерной случайной величины:
M(X+Y)= (x+y)p(x, y)dxdy.
Представляя двойной интеграл как сумму двух повторных и выбирая соответствующий порядок интегрирования в слагаемых, имеем:
M(X+Y)= xdx p(x, y)dy+ ydy p(x, y)dx=
= xpX(x)dx+ ypY(y)dy=MX+MY.
b. Дискретный случай.
M(X+Y)= (xi+yj)pij.
Представляем двойную сумму как две повторные:
M(X+Y)= xi 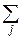 pij+ yi pij= xipi+ yjpj=MX+MY.
pij+ yi pij= xipi+ yjpj=MX+MY.
Аналогично эту теорему можно доказать для смешанного случая. Общая же формулировка потребовала бы введения двумерного интеграла Стилтьеса.
5°. Предыдущая теорема естественно обобщается на сумму n слагаемых:
M 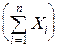 =
= 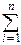 MXi.
MXi.
Как частный случай применения этой формулы отметим следующую задачу: имеются события A1, A2, ¼ , An, их вероятности соответственно равны p1, p2, ¼ , pn. Спрашивается, чему равно ожидаемое число событий A1, A2, ¼ , An, которые произойдут в опыте? Определим вспомогательные случайные величины Xiравенствами:
|
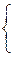
0, если событие Aiне произошло.
Всего в опыте происходит Xi событий, а ожидаемое число равно
M = MXi= 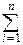 pi.
pi.
6°. Ещё одна формула для дисперсии: DX=M(X2)-M2(X).
Действительно, в силу теорем 3° и 4° имеем:
DX=M[(X-MX)2]=M(X2)-MX×MX+M[M(X)2]=
=M(X2)-2.M2(X)+M2(X)=M(X2)-M2(X).
В частности, если MX=0, то DX=M(X2).
7°. Нормированной случайной величиной X*назовём:
X*= 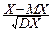 .
.
Это – безразмерная случайная величина, причём:
a) MX*=0, b) M(X*2)=1, c) DX*=1.
Действительно, по теореме 3° и 4°:
MX*=M( )= 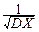 (MX-MX)=0,
(MX-MX)=0,
M(X*2)=M[ 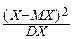 ]=
]= 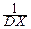 M[(X-MX)2]= DX=1,
M[(X-MX)2]= DX=1,
DX*=M(X*2)-(MX*)2=1-0=1.
8°. Если DX=0, то почти наверное X=const. Действительно,
DX= (x-MX)2dF(x).
Интегрируемая функция (x-MX)2 неотрицательна, причём обращается в ноль, только в точке x=MX. Интегрирующая функция F(x) монотонно неубывающая, причём её наименьшее значение ³0, а наибольшее £1. Очевидно, равенство DX=0 возможно лишь в том случае, когда весь рост функции F(x) сосредоточен в точке MX, а это и означает, что X=const почти наверное.
9°. Пусть дана двумерная случайная величина (X, Y). Назовем коэффициентом корреляции двумерной случайной величины число
r=r(X, Y)=M(X*, Y*)= 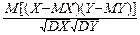 .
.
Числитель здесь называется ковариацией случайных величин X и Y:
cov(X, Y)=M[(X-MX)(Y-MY)]=M(XY)-MX×MY.
Из определения коэффициента корреляции следует, что
cov(X, Y)=r× × 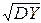 .
.
Очевидно, коэффициент корреляции не меняется при линейном преобразовании случайных величин; в частности, r(X, Y)=r(X*, Y*).
Коэффициент корреляции – числовая характеристика пары случайных величин, определённых на одном и том же вероятностном пространстве, –заслужил репутацию меры линейной связи величин X и Y.
Основанием к этому служат последующие теоремы о коэффициенте корреляции.
10°. M(XY)=MX×MY+cov(X, Y) или M(XY)=MX×MY+r× × .
Действительно:
M(XY)=M{[(X-MX)+MX]×[(Y-MY)+MY]}=
=M[(X-MX)×(Y-MY)]+MY×M(X-MX)+MX×M(Y-MY)+M(MX×MY)=
=MX×MY+cov(X, Y).
Если коэффициент корреляции равен нулю, то математическое ожидание произведения случайных величин равно произведению их математических ожиданий: r=0 Û M(X×Y)=MX×MY.
Случайные величины X и Y, коэффициент корреляции которых равен нулю, называются некоррелированными.
11°. Если случайные величины X и Y независимы, то M(XY)=MX×MY.
Докажем эту теорему отдельно для непрерывного и дискретного случая.
a. Непрерывный случай. Пусть p(x, y) – двумерная плотность вероятности. Так как X и Y независимы, то p(x, y)=pX(x)pY(y). Поэтому:
M(XY)= xyp(x, y)dxdy= xpX(x)dx ypY(y)dy=MX×MY.
b. Дискретный случай. Вероятности pijможно представить как: pij=piqj
M(XY)= xiyjpij= xiyjpiqj= xipi yjqj=MX×MY.
12°. Если случайные величины X и Y независимы, то они некоррелированы: r=0.
Это утверждение следует из 11° и формулы для коэффициента корреляции:
r= 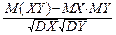 .
.
13°. Для двух произвольных случайных величин X и Y:
D(X±Y)=DX+DY±2r
или
D(X±Y)=sX2+sY2±2rsXsY.
Для некоррелированных, тем более – для независимых случайных величин:
D(X±Y)=DX+DY.
В частности, D(aX+b)=a2DX, D(X+c)=DX.
14°. Как частный случай теоремы 13° находим: D(X*±Y*)=2(1±r).
Для доказательства достаточно воспользоваться теоремой 7°.
15°. Обобщим теорему 13° на случай n слагаемых.
D =M 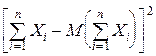 =M
=M 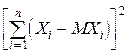 =
=
=M 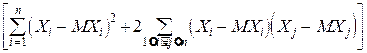 =
=
= DXi+2 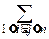 cov(Xi, Xj)= DXi+2 r(Xi, Xj)×si×sj,
cov(Xi, Xj)= DXi+2 r(Xi, Xj)×si×sj,
где si= 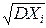 , sj=
, sj= 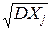 .
.
Для попарно некоррелированных случайных величин дисперсия суммы
равна сумме дисперсий: D = DXi.
16°. Для того, чтобы случайные величины X и Y были связаны линейно, необходимо и достаточно, чтобы их коэффициент корреляции r был равен ±1.
a. Необходимость. Пусть Y=aX+b.
Имеем:
r= = 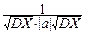 M{(X-MX)×[aX+b-M(aX+b)]}=
M{(X-MX)×[aX+b-M(aX+b)]}=
= 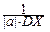 M{(X-MX)×[aX-aMX+b-Mb]}=
M{(X-MX)×[aX-aMX+b-Mb]}=
= a×M[(X-MX)2]= 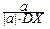 DX=
DX= 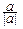 =signa.
=signa.
b. Достаточность. Пусть r=±1.
По теореме 14°: D(X*±Y*)=2(1±r).
Поэтому, если r=1, то D(X*-Y*)=2(1-r)=0 и по теореме 8°: с вероятностью, равной 1, X*-Y*=const Û - 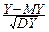 =const, т. е. X и Y связаны линейно.
=const, т. е. X и Y связаны линейно.
Если же r=-1, то D(X*+Y*)=2(1+r)=0 и почти наверное X*+Y*=const Û + =const и опять получается, что X и Y линейно связаны.
17°. Пусть наблюдается двумерная случайная величина (X, Y), при этом представляет интерес случайная величина Y, тогда как измерению доступны значения случайной величины X. Желательно по X предсказать (в каком-то смысле – наилучшим образом) Y. В качестве предсказания можно мыслить различные функции j(X): Y»j(X), а качество приближения оценивать среднеквадратической ошибкой: оптимальным считать такое приближение j(X), которое минимизирует математическое ожидание M[(Y-j(X))2].
Здесь мы найдём лучшее приближение среди всех линейных приближений, причём будем решать эту задачу для нормированных случайных величин X*, Y*, т. е. будем предполагать, что Y*»aX*±b.
Ищем такие a и b, которые минимизируют функцию
I(a, b)=M[(Y*-aX*-b)2].
Очевидно,
I(a, b)=M(Y*2)+a2(MX*)2+b2-2aM(X*Y*)+2bMY*+2abMX*
и по теореме 7°:
I(a, b)=1+a2-b2-2ar.
Уравнения для нахождения экстремума:
|
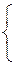
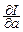 =2a-2r=0,
=2a-2r=0,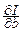 =2b=0.
=2b=0.
Отсюда следует, что a=r, b=0 и наилучшее предсказание: Y*»rX* или:
»r ,
что можно переписать в виде:
Y»r 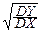 (X-MX)+MY
(X-MX)+MY
(именно эту формулу мы бы получили, если бы решали задачу для (X, Y), а не для (X*, Y*)).
Прямая
y=r (x-MX)+MY
называется линией регрессии Y на X.
В частности, если X и Y – независимые случайной величины, то наша формула указывает следующее наилучшее предсказание: Y»MY и никакой информации о Y случайная величина X не содержит.
18°. Для n-мерной случайной величины (X1, X2, ¼ , Xn) роль дисперсии играет так называемая ковариационная матрица:
D=||cov(Xi, Xj)||,
или
D=||rijsisj||,
где rij=r(Xi, Xj), si= , sj= .
D – симметричная матрица размера n´n с диагональными элементами, равными дисперсиям случайных величин.
Найдём ковариационную матрицу n-мерного нормального закона, задаваемого совместной плотностью
p(x1, x2, ¼ , xn)= 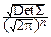 exp(-
exp(- 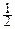 (x-a)TS(x-a)),
(x-a)TS(x-a)),
где xT=(x1, x2, ¼ , xn), aT=(a1, a2, ¼ , an), S=ATA=||aij||.
С помощью линейного преобразования Y=A(X-a) можно привести квадратичную форму (x-a)TS(x-a) к сумме квадратов переменных y1, y2, ¼ , yn.
Плотность p(x1, x2, ¼ , xn) постоянна на эллипсоидах (x-a)TS(x-a)=const. Из соображений симметрии ясно, что центр тяжести такого распределения лежит в точке (a1, a2, ¼ , an), так что вектор математических ожиданий равен
(MX1, MX2, ¼ , MXn)=(a1, a2, ¼ , an).
Ковариационная матрица выглядит поэтому так:
D=||M[(Xi-ai)(Xj-aj)]||.
Общий элемент этой матрицы равен
cov(Xi, Xj)= 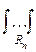 (xi-ai)(xj-aj)exp(-
(xi-ai)(xj-aj)exp(- 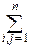 aij(xi-ai)(xj-aj))dx1¼dxn.
aij(xi-ai)(xj-aj))dx1¼dxn.
Переходим к новым переменным y1, y2, ¼ , ynпо формуле Y=A(X-a). Якобиан этого преобразования, очевидно, равен J= 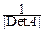 =
= 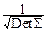 . Матрица A обратима, так что X-a=A-1Y.
. Матрица A обратима, так что X-a=A-1Y.
При вычислении интеграла учёт чётности и нечётности отдельных слагаемых даёт:
cov(Xi, Xj)= 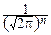
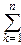 yk2(A-1)ki(A-1)kjexp(-
yk2(A-1)ki(A-1)kjexp(- 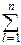 yi2)dy1¼dyn=
yi2)dy1¼dyn=
= (A-1)ki(A-1)kj,
а это есть, очевидно, общий элемент матрицы (ATA)-1. Отсюда следует, что ковариационная матрица D есть матрица, обратная матрице S:
D=S-1.
Нормальный n-мерный закон можно поэтому задать с помощью вектора математических ожиданий a=(a1, a2, ¼ , an) и ковариационной матрицы D:
p(x1, x2, ¼ , xn)= 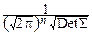 exp(- (x-a)D-1(x-a)T).
exp(- (x-a)D-1(x-a)T).
Ковариационная матрица двумерного нормального закона равна:
D= 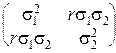 .
.
В соответствии с правилами нахождения обратной матрицы, известными из алгебры, легко вычислить D-1, т. е. матрицу S:
S= 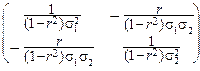 .
.
Поэтому двумерную нормальную плотность можно задать следующей формулой:
p(x, y)= 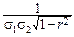 exp{-
exp{- 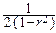 [
[ 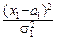 -2r
-2r 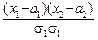 +
+ 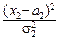 ]}.
]}.
Устройство матрицы A можно понять из геометрических соображений. Поскольку положительно определённая квадратичная форма определяет эллипсоид, можно с помощью поворота координатной системы, т. е. с помощью ортогонального преобразования X-a=OY, Y=OT(X-a) направить оси координат по осям симметрии эллипсоида. Это приводит квадратичную форму в показателе экспоненты к сумме 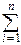 liyi2:
liyi2:
p(y1, y2, ¼ , yn)= 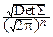 exp(-
exp(- 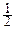 YTOTSOY),
YTOTSOY),
где OTSO=L – диагональная матрица: L=diag(l1, l2, ¼ , ln).
19°. Пусть X1, X2, ¼ , Xn– попарно некоррелированные случайные величины с одинаковыми математическими ожиданиями и одинаковыми дисперсиями:
MXi=a, DXi=s2, i=1, 2, … , n.
Обозначим через 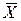 среднее арифметическое величин X1, X2, ¼ , Xn:
среднее арифметическое величин X1, X2, ¼ , Xn:
= 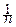 Xi.
Xi.
Тогда: 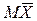 =a,
=a, 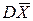 = s2.
= s2.
Эти равенства непосредственно следуют из теорем 3°, 5° и 15°.
Теорема 19°, в частности, применима к последовательности X1, X2, ¼ , Xnнезависимых и одинаково распределённых случайных величин, имеющих математическое ожидание и дисперсию. В этой схеме содержится случай повторных независимых измерений физической величины, точное значение которой равно a; в измерения вкрадываются случайные ошибки и n независимых измерений дают случайные значения X1, X2, ¼ , Xn. Если измерения не содержат систематической ошибки (на вероятностном языке это означает, что MXi=a, i=1, 2, … , n) и являются равноточными (т. е. DXi=s2, i=1, 2, … , n), то среднее арифметическое обладает двумя упомянутыми свойствами: =a, =
= s2. Это означает, что среднее арифметическое также не содержит систематической погрешности, а его среднеквадратическая ошибка в 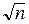 раз меньше, чем ошибка одного измерения. Это объясняет выгодность повторения независимых измерений для более точного измерения. Однако в то же время ясно, что точность растёт медленнее, чем число наблюдений. Чтобы, например, повысить точность измерений в десять раз, нужно увеличить число наблюдений в сто раз.
раз меньше, чем ошибка одного измерения. Это объясняет выгодность повторения независимых измерений для более точного измерения. Однако в то же время ясно, что точность растёт медленнее, чем число наблюдений. Чтобы, например, повысить точность измерений в десять раз, нужно увеличить число наблюдений в сто раз.
Дата добавления: 2017-09-19; просмотров: 1405;