Методы анализа больших систем
Теория систем большей частью основывает свои практические методы на платформе математической статистики. Можно выделить три подхода к решению задач, в которых используются статистические данные [5].
Алгоритмический подход, при котором мы имеем статистические данные о некотором процессе и по причине слабой изученности процесса его основную характеристику (например, эффективность экономической системы) мы вынуждены сами строить “разумные” правила обработки данных, базируясь на своих собственных представлениях об интересующем нас показателе.
Аппроксимационный подход, когда у нас есть полное представление о связи данного показателя с имеющимися у нас данными, но неясна природа возникающих ошибок — отклонений от этих представлений.
Теоретико-вероятностный подход, когда требуется глубокое проникновение в суть процесса для выяснения связи показателя со статистическими данными.
В настоящее время все эти подходы достаточно строго обоснованы научно и “снабжены” апробированными методами практических действий.
Но существуют ситуации, когда нас интересует не один, а несколько показателей процесса и, кроме того, мы подозреваем наличие нескольких, влияющих на процесс, воздействий — факторов, которые являются не наблюдаемыми, скрытыми или латентными.
Наиболее интересным и полезным в плане понимания сущности факторного анализа — метода решения задач в этих ситуациях, является пример использования наблюдений при эксперименте, который ведет природа. Ни о каком планировании здесь не может идти речь — нам приходится довольствоваться пассивным экспериментом.
Удивительно, но и в этих “тяжелых” условиях теория систем предлагает методы выявления таких факторов, отсеивания слабо проявляющих себя, оценки значимости полученных зависимостей показателей работы системы от этих факторов.
Пусть мы провели по n наблюдений за каждым из kизмеряемых показателей эффективности некоторой системы и данные этих наблюдений представили в виде матрицы (таблица 1).
Таблица 1- Матрица исходных данных E[n·k]
| E 11 | E12 | … | E1i | … | E1k |
| E 21 | E22 | … | E2i | … | E2k |
| … | … | … | … | … | … |
| E j1 | Ej2 | … | Eji | … | Ejk |
| … | … | … | … | … | … |
| E n1 | En2 | … | Eni | … | Enk |
Пусть мы предполагаем, что на эффективность системы влияют и другие — ненаблюдаемые, но легко интерпретируемые (объяснимые по смыслу, причине и механизму влияния) величины — факторы.
Сразу же сообразим, что чем больше n и чем меньше число факторов m(а может их и нет вообще!),тем больше надежда оценить их влияние на интересующий нас показательE.
Столь же легко понять необходимость условияm < k, объяснимогона простом примере аналогии — если мы исследуем некоторые предметы с использованием всех 5 человеческих чувств, то наивно надеяться на обнаружение более пяти “новых”, легко объяснимых, но неизмеряемых признаков у таких предметов, даже если мы “испытаем” очень большое их количество.
Вернемся к исходной матрице наблюдений E[n·k] и отметим, что перед нами, по сути дела, совокупности по n наблюдений над каждой из k случайных величин E1, E2, … E k. Именно эти величины “подозреваются” в связях друг с другом — или во взаимной коррелированности.
Из рассмотренного ранее метода оценок таких связей следует, что мерой разброса случайной величины Eiслужит ее дисперсия, определяемая суммой квадратов всех зарегистрированных значений этой величины S(Eij)2 и ее средним значением (суммирование ведется по столбцу).
Если мы применим замену переменных в исходной матрице наблюдений, т.е. вместо Ei j будем использовать случайные величины
Xij = 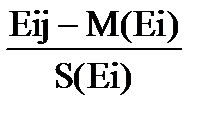 ,
,
то мы преобразуем исходную матрицу в новую X[n·k](таблица 2)
Таблица 2- Матрица преобразованных данных Х[n·k]
| X 11 | X12 | … | X1i | … | X1k |
| X 21 | X22 | … | X2i | … | X2k |
| … | … | … | … | … | … |
| X j1 | Xj2 | … | Xji | … | Xjk |
| … | … | … | … | … | … |
| X n1 | Xn2 | … | Xni | … | Xnk |
Отметим, что все элементы новой матрицы X[n·k] окажутся безразмерными, нормированными величинами и, если некоторое значение Xijсоставит, к примеру,+2, то это будет означать только одно - в строке j наблюдается отклонение от среднего по столбцу i на два среднеквадратичных отклонения (в большую сторону).
Выполнимтеперь следующие операции.
1) Просуммируем квадраты всех значений столбца 1 и разделим результат на (n - 1) — мы получим дисперсию (меру разброса) случайной величины X1, т.е. D1.Повторяя эту операцию, мы найдем таким же образом дисперсии всех наблюдаемых (но уже нормированных) величин.
2) Просуммируем произведения элементов соответствующих строк (от i=1 до i= n) для столбцов 1, 2 и также разделим на (n -1), то теперь мы получим коэффициент ковариации C12случайных величин X1 , X2, который служит мерой их статистической связи.
3) Если мы повторим предыдущую процедуру для всех пар столбцов, то в результате получим еще одну, квадратную матрицу C[k·k], которую принято называть ковариационной (таблица 3).
Этаматрица имеет на главной диагонали дисперсии случайных величин Xi, а в качестве остальных элементов — ковариации этих величин (i =1…k).
Таблица 3 - Ковариационная матрица C[k·k]
| D1 | C12 | C13 | … | … | C1k |
| C21 | D2 | C23 | … | … | C2k |
| … | … | … | … | … | … |
| Cj1 | Cj2 | … | Dj | … | Cjk |
| … | … | … | … | … | … |
| Ck1 | Ck2 | … | Cki | … | Dk |
Если вспомнить, что связи случайных величин можно описывать не только ковариациями, но и коэффициентами корреляции, то в соответствие матрице табл.3 можно поставить матрицу парных коэффициентов корреляции или корреляционную матрицу (таблица 4), в которой на диагонали находятся 1, а недиагональными элементами являются коэффициенты парной корреляции.
Таблица 4- Корреляционная матрица R [k·k]
| R12 | R13 | … | … | R1k | |
| R21 | R23 | … | … | R2k | |
| … | … | … | … | … | … |
| Rj1 | Rj2 | … | Rji | … | Rjk |
| … | … | … | … | … | … |
| Rk1 | Rk2 | … | Rki | … |
Так, если мы полагали наблюдаемые переменные Ei независящими друг от друга, то ожидалиувидеть матрицуR[k·k]диагональной, с единицамина главной диагонали и нулями в остальных местах. Если это не так, то наши догадки о наличии латентных факторов в какой-то мере получают подтверждение.
Но как убедиться в своей правоте, оценить достоверность нашей гипотезы — о наличии хотя бы одного латентного фактора, как оценить степень его влияния на основные (наблюдаемые) переменные? А если, тем более, таких факторов несколько — то как их проранжировать по степени влияния?
Ответы на такие практические вопросы призван давать факторный анализ. В его основе лежит все тот же “вездесущий” метод статистического моделирования (по образному выражению В.В. Налимова — модель вместо теории).
Дальнейший ход анализа при выяснении таких вопросов зависит от того, какой из матриц мы будем пользоваться. Если матрицей ковариаций C[k·k], то мы имеем дело с методом главных компонент, если же мы пользуемся только матрицей R[k·k],то мы используем метод факторного анализа в его “чистом” виде.
Остается разобраться в главном — что позволяют оба эти метода, в чем их различие и как ими пользоваться. Назначение обоих методов одно и то же — установить сам факт наличия латентных переменных (факторов), и если они обнаружены, то получить количественное описание их влияния на основные переменные Ei.
Дата добавления: 2017-09-19; просмотров: 686;