Экспертные методы оценивания качества товаров и услуг
При оценивании качества товаров как совокупности трудно измеряемых свойств очень часто прибегают к экспертным методам. На численном примере (данные взяты из источника [10]) рассматривается методика и последовательность проведения опроса и обработки полученных данных.
Для выявления узлов автомобилей КамАЗ с низкой надежностью свойством, которое является главным показателем качества механических систем, осуществлен опрос экспертов (табл. 19). Они присваивали ранг, равный единице, самому надежному по их мнению узлу и ранг, равный числу объектов, – девяти, наименее надежным. Промежуточные ранги присваивались узлам также в порядке снижения надежности: численное значение ранга увеличивалось по мере снижения надежности. Некоторым объектам присваивались одинаковые ранги, если эксперты считали их надежность одинаковой, соответствующей одному уровню. В принципе, можно было бы присваивать и дробные ранги. Для простоты обработки результатов нужно, чтобы сумма рангов в каждой строке
s = 0,5k(k + 1), (3.1)
где k – число оцениваемых объектов, в данном случае узлов автомобиля.
По результатам ранжирования вычисляется сумма рангов xj для каждого объекта, которая и является оценкой исследуемого показателя качества.
Для оценки согласованности мнений экспертов вычисляется коэффициент конкордации. Он представляет собой дробь, в числителе которой сумма квадратов отклонений суммарных рангов xj от общей средней их величины.
а = 0,5m(k + 1), (3.2)
где m – число экспертов; k – число ранжируемых узлов.
Сумма квадратов отклонений
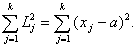 (3.3)
(3.3)
В знаменателе дроби максимально возможная сумма квадратов отклонений, которая могла бы быть при полном совпадении мнений экспертов и отсутствии одинаковых и дробных рангов по строкам, представлена выражением:
 (3.4)
(3.4)
Производим вычисления (см. табл. 19):
a = 0,5m(k+1) = 0,5·9(9 + 1) = 45.
Пример 1.
Таблица 19
Результаты экспертного опроса специалистов о надежности узлов автомобилей семейства КамАЗ
| № п/п | Эксперты, специалисты, проработавшие в сфере эксплуатации, технического обслуживания и ремонта автомобилей КамАЗ не менее десяти лет | Узлы автомобилей КамАЗ | ||||||||
| Двигатель | Сцепление, делитель, КП | Мосты | Задняя подвеска | Пневмопривод тормозной системы | Узлы электрооборудования | Передняя подвеска | Рулевое управление | Другие механизмы и системы управления | ||
| Главный инженер | ||||||||||
| Заместитель директора | ||||||||||
| Механик-эксплуатационник | ||||||||||
| Технолог-ремонтник | ||||||||||
| Механик-ремонтник | ||||||||||
| Водитель | ||||||||||
| Водитель | ||||||||||
| Водитель | ||||||||||
| Водитель | ||||||||||
| xj | ||||||||||
| xj – a | –26 | –24 | –28 | –4 | –1 | |||||
| Lj2 |
Максимально возможная величина суммы квадратов отклонений, которая может иметь место при полном совпадении мнений экспертов с учетом наличия связанных рангов,
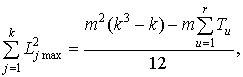 (3.5)
(3.5)
где r – число строк, имеющих связанные ранги; Tu – величина, учитывающая число типов связанных рангов в строке,
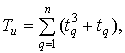
где t – число q-х типов равных рангов в u-й строке; n – число типов связанных рангов в строке.
Первая строка табл. 19 имеет два связанных ранга одного типа (связанных по два ранга): 1, 1 и 4, 4, поэтому
Т1 = (23 – 2) + (23 – 2) = 12.
Вторая строка не имеет связанных рангов, Т2 = 0, третья строка имеет два связанных ранга одного типа: 2, 2 и 6, 6, поэтому
Т3= (23 – 2) + (23 – 2) = 12.
Четвертая, пятая и шестая строки связанных рангов не имеют и Т4 = Т5 = Т6 = 0, седьмая срока имеет один тип связанных рангов, но отличный от предыдущих (здесь тройная связка 4,4,4), поэтому
Т7 = (33 – 3) = 24.
Восьмая строка имеет один трижды связанный ранг: 5,5,5 и Т8= (33 – 3) = 24, а для девятой строки, имеющей связанные ранги 2, 2 и 6, 6 Т9 = (23 – 2) + (23 – 2) = 12, поэтому суммарное значение
Тu = 12 + 12 + 24 + 24 + 12 = 84.
Коэффициент конкордации
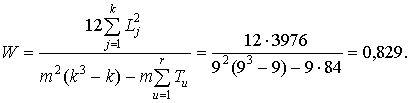
Проверка согласованности мнений экспертов осуществляется с использованием 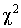 – мощного критерия (табл. 9 приложения), минимизирующего ошибку второго рода (принятие неверной гипотезы), при уровне значимости α – вероятности забраковать справедливую гипотезу (ошибка первого рода) и числе степеней свободы f.
– мощного критерия (табл. 9 приложения), минимизирующего ошибку второго рода (принятие неверной гипотезы), при уровне значимости α – вероятности забраковать справедливую гипотезу (ошибка первого рода) и числе степеней свободы f.
Значение – статистики вычисляется по формуле
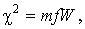
где m – число экспертов; f – число степеней свободы f =k – 1, W – коэффициент конкордации.
При условии, что величина -статистики превышает критическое значение при уровне значимости α и числе степеней свободы f,т. е.  гипотеза о согласованности мнений экспертов не отвергается.
гипотеза о согласованности мнений экспертов не отвергается.
В рассматриваемом примере при m = 9, f = 8, α = 0,05, поэтому
χ2 = 9(9 – 1)0,829 = 59,688 > χ2кр(0,05; 8) = 15,507
(по табл. 9 приложения), следовательно, гипотеза о согласованности мнений экспертов не отвергается.
Пример 2. Проранжировать основные виды транспорта (табл. 20) в свете эффективности их использования для крупных отправителей по шести критериям (m = 6). Данные взяты из источника [7].
Таблица 20
Оценки видов транспорта по критериям крупных отправителей
| № п/п | Критерии эффективности видов транспорта | Железнодорожный | Водный | Автомобильный | Трубопроводный | Воздушный |
| Скорость (время доставки франко склад) | ||||||
| Частота отправок в сутки | ||||||
| Надежность (соблюдение графиков доставки) | ||||||
| Перевозочная способность перевозить широкую номенклатуру грузов | ||||||
| Доступность (число обслуживаемых точек) | ||||||
| Стоимость за тонно-милю | ||||||
| хj | ||||||
| xj – a | –1 | –4 | ||||
| Lj2 |
Решение. Сумма рангов по строкам:
S = 0,5k(k + 1) = 0,5·5(5 + 1) = 15.
Общая средняя а = 0,5m(k + 1) = 0,5·6(5 + 1) = 18,
где m – число показателей ранжирования; k – число ранжируемых объектов.
Сумма квадратов отклонений
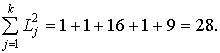
Максимально возможная сумма квадратов отклонений при отсутствии связанных рангов
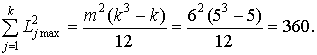
Значение коэффициента конкордации
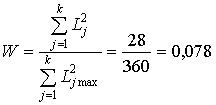 .
.
Для оценки существенности коэффициента конкордации при числе критериев оценки эффективности транспорта m = 6 и числе степеней свободы, равном числу ранжируемых объектов минус единица (f = k – 1 = 5 – 1 = 4) вычисляется значение -ста-тистики:
= mfW = 6·4·0,078 = 1,872 < кр(0,05; 4) = 9,488.
Критическое значение (табл. 9 приложения) превышает найденную величину 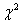 , гипотеза о справедливости присвоенных рангов видам транспорта, представленным в табл. 20, отклоняется, поскольку ранги, образующие совокупность, неразличимы, отличия между ними несущественны, количество использованной информации для их определения мало. По смыслу задачи можно увеличить число критериев оценки эффективности транспорта и тогда из однородной совокупности оценок можно было бы выделить существенные отличия между ними, если они есть в действительности, в смысле эффективности перевозок в сложившихся условиях.
, гипотеза о справедливости присвоенных рангов видам транспорта, представленным в табл. 20, отклоняется, поскольку ранги, образующие совокупность, неразличимы, отличия между ними несущественны, количество использованной информации для их определения мало. По смыслу задачи можно увеличить число критериев оценки эффективности транспорта и тогда из однородной совокупности оценок можно было бы выделить существенные отличия между ними, если они есть в действительности, в смысле эффективности перевозок в сложившихся условиях.
С другой стороны, данная методика не позволяет использовать всю информацию табл. 20: в формулу оценки существенности W вошли m и f, но не сами ранги, имеющиеся в табл. 20, а это существенная информация, так как количество рангов равно тридцати. Методика также позволяет оценивать согласованность сразу всех суммарных рангов в совокупности, но может оказаться, что некоторые ранги определены экспертами четко и однозначно, а остальные практически не различимые суммарные ранги размывают, затушевывают картину. Поэтому для выделения из совокупности отличного от остальных суммарного ранга применяется способ исключения резко выделяющихся наблюдений, позволяющий использовать большую информацию, чем рассматриваемый способ Кендалла.
Суть заключается в том, что последовательно в вариационном ряду суммарных рангов: 14, 17, 19, 19, 21, определяются резко выделяющиеся значения с помощью специального ζ-критерия (табл. 21). И если таковые окажутся, то они и есть ярко выраженные, по праву занимающие свое место в исследуемом ранжире суммарные ранги. Формула, применяемая для этой процедуры, включает оценку среднего квадратического отклонения, вычисляемого по всем тридцати рангам шестерых экспертов (табл. 4 приложения).
Таблица 21
Параметры для вычисления ζ-статистики
| Средние значения рангов по столбцам | 17/6 = = 2,83 | 19/6 = = 3,17 | 14/6 = = 2,33 | 19/6 = = 3,17 | 21/ = = 3,5 |
| Оценки дисперсий по столбцам | 0,57 | 2,97 | 1,07 | 4,17 | 2,3 |
| Сумма оценок дисперсий | 11,07/5 = 2,21 | ||||
| Среднее квадратическое отклонение | 2,210,5 = 1,49 | ||||
| Среднее значение членов вариационного ряда | 
|
Значение ζ-статистики вычисляется по формуле
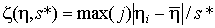 ,
,
где ηj – j-й член вариационного ряда; 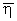 – среднее значение членов вариационного ряда; s* – среднее квадратическое отклонение членов вариационного ряда.
– среднее значение членов вариационного ряда; s* – среднее квадратическое отклонение членов вариационного ряда.
При ζ(η, s*) > ζкр (η, s*) гипотеза о принадлежности ηj к исследуемому вариационному ряду отвергается. Поскольку в данном ряду больше всех выделяется суммарный ранг 14, то значение
ζ-статистики
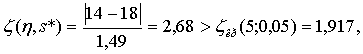
т. е. гипотеза о принадлежности ранга 14 вариационному ряду отвергается (табл. 4 приложения).
Вторым по величине отклонения от среднего значения  является суммарный ранг 21, для него значение ζ-статистики, вычисленное по той же формуле,
является суммарный ранг 21, для него значение ζ-статистики, вычисленное по той же формуле,
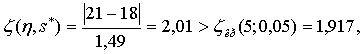
т. е. гипотеза о принадлежности суммарного ранга 21 к исследуемому вариационному ряду также отвергается (табл. 4 приложения) и может быть принята конкурирующая гипотеза о том, что суммарный ранг 21 так же, как и ранг 14, резко выделяется из членов вариационного ряда.
Значение ζ-статистики для остальных членов вариационного ряда (17, 19, 19), имеющих абсолютное отклонение от среднего значения равное 1,
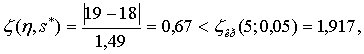
т. е. гипотеза о принадлежности этих трех членов к исследуемому вариационному ряду не отвергается (табл. 4 приложения).
Следовательно, автомобильный транспорт для перевозок грузов крупными отправителями в создавшихся условиях наиболее эффективен, воздушный – самый неэффективный, водный, железнодорожный и трубопроводный по эффективности однородны (безразлично, каким пользоваться) и делят второе, третье и четвертое места.
3.2. Оценивание существенности влияния
рейтинга марки товара на прибыль фирм
От 50 до 90 % статистических данных, используемых в экономике, социологии, медицине, технике, имеют нечисловую природу и могут быть оценены только качественно [8]. Для количественной оценки качественных признаков используются ранги – числа, определяемые эвристическими методами. Ранги приближенно указывают на уровень качества (как совокупности свойств) объекта. Чаще всего при решении практических задач для нахождения их величин используется метод экспертных оценок. В некоторых случаях, когда часть данных – результат маркетинговых измерений, для преобразования натуральных значений экспериментальных данных в соответствующие ранги применяют интервальный метод. Он предусматривает вычисление длины интервала путем деления величины размаха выборки на количество интервалов, принимаемое исследователем, исходя из точности измерений, удобства обработки и представления результатов и т. п., установление соответствия каждого значения данных наблюдений найденным интервалам и присвоение им рангов, соответствующих уровням качества.
Пример. С целью оценки существенности влияния рейтинга марки товара на долю прибыли в объеме продаж [6] для фирм США и Великобритании проведены расчеты, представленные в табл. 22. Для установления согласованности расчетных данных с фактическими значениями рейтинга с позиций доли прибыли в объеме продаж необходимо заменить данные строки 2 соответствующими рангами.
Таблица 22
Соотношение предварительных оценок >рейтинга марок товаров и долей прибыли в объеме продаж, %
| Предварительный рейтинг марки | ||||
| Доля прибыли в объеме продаж, % | 17,9 | 2,8 | –0,9 | –5,9 |
Решение. Учитывая, что количество интервалов k = 4; максимальное значение показателя Хmax в строке 2 равно 17,9, а минимальное Хmin = – 5,9 и размах выборки
R = Xmax – Xmin,; R = 17,9 – (– 5,9) = 23,8,
получим длину интервала:
d = R/k; d = 23,8/4 = 5,95.
Это позволяет вычислить границы интервалов (табл. 23), например, для первого интервала верхняя граница 17,9, нижняя 17,9 – 5,95 = 11,95 и т. д.
Таблица 23
Номера и границы интервалов фактических значений долей прибыли в объеме продаж
| Номер интервала | |||
| Граница интервала | |||
| 17,9–11,95 | 11,95–6,00 | 6,00–0,05 | 0,05–(–5,90) |
Из табл. 22 и 23 видно, что значение 17,9 попадает в первый интервал, значение 2,8 – в третий интервал, а (–0,9) и (–5,9) – в четвертый. Следовательно, значению 17,9 соответствует ранг 1, значению 2,8 – ранг 3, значению (–0,9) – ранг, равный 4, и, наконец, значению (–5,9) – тоже ранг 4. Поскольку предварительные рейтинги марок, по сути, и есть их ранги, то для дальнейшей обработки данных табл. 22 их следует преобразовать, заменив количественные показатели второй строки соответствующими рангами (табл. 24).
Таблица 24
Ранги предварительных рейтингов марок и соответствующих долей прибыли в объеме продаж товара
| Предварительный рейтинг марки | ||||
| Ранг доли прибыли в объеме продаж |
Для оценки согласованности предварительного рейтинга марки и долей прибыли в объеме продаж товара в данном случае может быть использован коэффициент множественной качественной конкордации [8]:
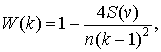 (3.6)
(3.6)
где n – объем выборки или число объектов; k – число качественных уровней k = 2, 3, …, q; S(v) – сумма вариаций качественных оценок; m – количество признаков.
Параметр m в формулу (3.6) входит неявно, по нему осуществляется суммирование для каждого из признаков, определяющих в конечном счете S(v):
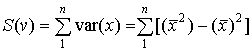 , (3.7)
, (3.7)
где 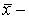 средние значения рангов по столбцам;
средние значения рангов по столбцам; 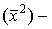 средние квадратов рангов по столбцам.
средние квадратов рангов по столбцам.
В соответствии с табл. 24 для первого столбца 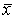 = (1 + 1)/2 = 1, для второго оно равно 2,5, для третьего – 3,5, для четвертого – 4.
= (1 + 1)/2 = 1, для второго оно равно 2,5, для третьего – 3,5, для четвертого – 4.
Средняя квадратов по столбцам: для первого столбца 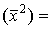 = (12 + 12)/2 = 1, для второго – 6,5, для третьего – 12,5, для четвертого – 16.
= (12 + 12)/2 = 1, для второго – 6,5, для третьего – 12,5, для четвертого – 16.
Вариации по столбцам: для первого столбца – var1(x) = 1 – 12 = = 0; для второго var2(x) = 6,5 – 2,52 = 0,25; для третьего var3(x) = 12,5 – 3,52 =
= 0,25; для четвертого var4(x) =16 – 42 = 0.
Сумма вариаций (табл. 25): S(v) = 0 + 0,25 + 0,25 + 0 = 0,5.
Таблица 25
Результаты вычислений
| Показатель | Ранг | Сумма | |||
| Предварительный рейтинг марки | |||||
| Доля прибыли в объеме продаж | |||||
| Средние значения рангов по столбцам | 2,5 | 3,5 | |||
| Средняя квадратов по столбцам | 6,5 | 12,5 | |||
| Var (x) по столбцам | 0,25 | 0,25 | S(v) = 0,5 |
Коэффициент множественной качественной конкордации в соответствии с формулой (3.6) при n = 4, k = 4:
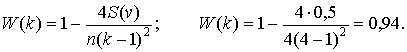
Учитывая, что степень согласованности при W(k) < 0,75 – «слабая», при 0,75 < W(k) < 0,85 – «средняя», при 0,85 < W(k) < 0,95 – «выше средней», при W(k) > 0,95 – «сильная», уровни качества товаров с рейтингами 3 и 4 практически не различимы.
Кластер – некоторая совокупность «родственных» объектов, объединенных по набору общих для этих объектов признаков.
В сравнительной характеристике различных видов транспорта (табл. 26) каждому из них присвоены ранги в зависимости от эффективности, определяемой показателями качества перевозок [7]. Ранг 1 присвоен показателям с очень низкой эффективностью, ранг 2 – с низкой эффективностью, 3 – со средней эффективностью, 4 – с хорошей, 5 – с очень хорошей. Анализируются пять видов транспорта по пяти их существенным показателям с целью выявления кластеров для выбора эффективного способа перевозок.
Таблица 26
Показатели качества перевозок различных видов транспорта
| Вид транспорта | Стоимость за милю А1 | Скорость поставки А2 | Стабильность графика поставок А3 | Гибкость обработки груза А4 | Месторасположение А5 |
| Воздушный | |||||
| Водный | |||||
| Жел. дор. | |||||
| Автомобильный | |||||
| Трубопроводный |
Вычисляется (табл. 27) коэффициент сходства для всей совокупности объектов (для всех пяти видов транспорта) по формуле (3.6):
Таблица 27
Параметры вариации уровней качества объектов
| Средние | 2,8 | 3,2 | 3,6 | 3,2 | 3,0 | Сумма |
| Средние квадратов | 9,6 | 12,4 | 12,8 | 11,0 | ||
| Var(x) | 1,76 | 2,16 | 1,04 | 2,56 | 2,0 | S(v) = 9,52 |
Коэффициент при n = 5 и k = 5:
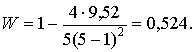
Для формирования матрицы парных свойств рассчитываются коэффициенты сходства для каждой пары объектов.
Например, расчет коэффициента сходства качественных оценок для воздушного и водного транспорта представлен в табл. 28.
Таблица 28
Расчет параметров для вычисления коэффициента сходства оценок эффективности воздушного и водного транспорта
| Воздушный транспорт | |||||
| Водный транспорт | |||||
| Средние значения оценок | 2,5 | 3,5 | 2,5 | ||
| Средние квадратов | 6,5 | 14,5 | 6,5 | ||
| Var (x) | 0,25 | 2,25 | 0,25 |
Сумма вариаций качественных оценок
S(v) = 4 + 4 + 0,25 + 2,25 + 0,25 = 10,75,
коэффициент сходства в соответствии с формулой (3.6)
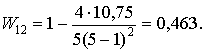
Вычислив коэффициенты сходства для всех пар, получим матрицу парных сходств в виде табл. 29.
Из табл. 29 следует, что первый кластер (А3, А4) состоит из элементов с парным коэффициентом сходства, соответствующим «выше средней» плотности оценок. Второй кластер (А1, А4, А5) содержит элементы с парными коэффициентами сходства, соответствующими «средней» плотности.
Таблица 29
Матрица парных сходств качественных оценок эффективности видов транспорта
| А1 | А2 | А3 | А4 | А5 | |
| А1 | 0,463 | 0,763 | 0,838 | 0,763 | |
| А2 | 0,775 | 0,625 | 0,575 | ||
| А3 | 0,925 | 0,625 | |||
| А4 | 0,675 | ||||
| А5 |
Коэффициент сходства между кластерами вычисляется по формуле (3.6), элементами расчетной матрицы служат все элементы, образующие эти кластеры: А1, А2, А3, А4, А5 (табл. 30).
Таблица 30
Данные для расчета коэффициента сходства между кластерами
| Вид транспорта | А1 | А2 | А3 | А4 | А5 |
| Воздушный | |||||
| Жел. дор. | |||||
| Автомобильный | |||||
| Трубопроводный | |||||
| Средние | 2,25 | 3,75 | 2,75 | ||
| Средние квадратов | 5,75 | 15,25 | 16,5 | 9,75 | 11,5 |
| Var(x) | 0,69 | 1,19 | 0,5 | 2,19 | 2,5 |
Вычисляем S(v) = 0,69 + 1,19 + 0,5 + 2,19 + 2,5 = 7,07.
Коэффициент сходства,
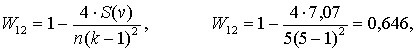
т. е. первый и второй кластеры практически не имеют сходства, являясь независимыми скоплениями сходных между собой оценок.
Центр кластера [8] – некоторый условный объект, координаты которого есть средние значения соответствующих координат всех объектов, входящих в кластер. Например, для кластера (А3, А4) средние значения координат составят:
1) (3 + 2 )/2 = 2,5; 2) (4 + 4)/2 = 4; 3) (4 + 4)/2 = 4; 4) (5 + 3)/2 = 4;
5) (4 + 5)/2 = 4,5, т. е. центр кластера будет иметь координаты, приведенные в табл. 31.
Таблица 31
Координаты центра кластера (А3, А4)
| А1 | А2 | А3 | А4 | А5 |
| 2,5 | 4,5 |
Для нахождения центра второго кластера (А1, А4, А5) необходимо вычислить координаты пар (табл. 9) А1, А4, А1, А5, а затем подсчитать их средние значения. Координаты пар находят так же, как и координаты центра кластера (А3, А4). Координаты центра второго кластера – средние по столбцам табл. 32.
Таблица 32
Координаты пар и центра кластера
| Координаты пары А1, А4 | 1,5 | 4,5 | 3,5 | 2,5 | 3,5 |
| Координаты пары А1, А5 | 2,0 | 3,5 | 4,0 | 1,5 | 1,5 |
Данные для расчета коэффициента сходства между кластерами (А3, А4) и (А1, А4, А5) представлены в табл. 33.
Таблица 33
Параметры для расчета коэффициента сходства между кластерами
| Параметры | А1 | А2 | А3 | А4 | А5 |
| Центр кластера (A3, A4) | 2,5 | 4,0 | 4,0 | 4,0 | 4,5 |
| Центр кластера (A1, A4, A5) | 1,75 | 3,75 | 2,5 | ||
| Средние значения координат | 2,13 | 3,88 | 3,0 | 3,5 | |
| Средние квадратов координат | 4,66 | 13,3 | |||
| Var (x) | 0,14 | 0,02 |
Вычисляем S(v) = 0,14 + 0,02 + 1 + 1 = 2,16.
Коэффициент сходства между центрами первого и второго кластеров
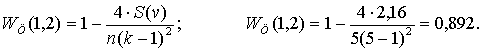
Расстояние между кластерами 1 и 2 вычисляется по формуле
R = 1 – WЦ.
В данном случае R(1,2) = 1 – 0,892 = 0,108.
Расстояние между кластерами, «сгустками» довольно точно согласующихся ранговых оценок, невелико, тем более, что области с низкой плотностью согласования рангов также невелики.
Вычисления показывают, что рейтинговые оценки и на их основании присвоенные ранги достоверны. Показатели по железнодорожному и автомобильному транспорту наиболее точны. В предположении, что уровень квалификации всех экспертов, оценивающих эффективность данных видов транспорта, достаточно высок, результатами расчета можно руководствоваться при выборе вариантов доставки товаров.
Дата добавления: 2016-03-27; просмотров: 797;