Представление знаний в системах ИИ
С разработкой и использованием вычислительной техники традиционно связаны такие понятия, как программы и данные. При этом первые предназначены для обработки вторых. Программист разрабатывал программу, и сам вводил в нее необходимые данные.
Затем произошло крупное изменение - данные были отделены от программ, появились базы данных различной структуры (реляционные(табличные), иерархические, сетевые) и системы управления базами данных (СУБД).
Для отделения данных от программ использовались средства описания данных, содержащиеся в языках программирования. Такие языки, как ФОРТРАН и АЛГОЛ, содержат средства описания относительно простых структур данных в памяти ЭВМ. Более сложные средства описания иерархических структур данных имеются в языках КОБОЛ, СИ, ПАСКАЛЬ. В языках ПАСКАЛЬ, МОДУЛА-2, АДА также есть средства для конструирования структур данных самим пользователем.
Параллельно, с некоторым временным сдвигом, развивались представления данных во внешней памяти ЭВМ. Здесь фундаментальным понятием стало понятие информационного массива- файла, имеющего имя и содержащего все необходимые структурированные записи данных о различных объектах, с которыми ведет работу система. Файл можно трактовать как информационную модель объекта.
Представление данных во внешней памяти ЭВМ прошло через три этапа:
1) Способы формирования записей данных в файлах, ведение файлов и организация доступа к ним полностью определялись в конкретных программах пользователя;
2) Управление файлами и организацию доступа к ним стали осуществлять операционные системы ЭВМ;
3) Создание баз данных и развитых систем управления ими, когда стала возможной эффективная работа с большими базами данных (в частности, с интегрированными, содержащими разнородные данные), обрабатываемыми в интересах целого предприятия, отрасли и т.п., и предназначенными для использования в прикладных задачах.
На первом этапе создание, поддержание, организация доступа к данным, как на логическом, так и на физическом уровнях целиком возлагались на разработчика и пользователя каждой программы. Работа с данными программы и тем более их использование в других программах были крайне трудоемки и малоэффективны.
Однако работа с интегрированными данными стала реальностью лишь на третьем этапе, когда появилась возможность эффективно организовывать базы данных со сложной структурой, а в рамках СУБД появились мощные средства для работы с данными. Это сделало оправданным и эффективным существование в системе данных, независимых от прикладных программ, в которых эти данные создаются и используются, позволило технологически отделить друг от друга различные программы (создающие, поддерживающие и использующие данные). Появилась возможность эффективно связывать программы для обработки данных с самими этими данными и вызывать уже программы исходя изданных, а не наоборот, как было ранее.
На втором этапе часть забот по работе с данными во внешней памяти ЭВМ (в основном на физическом уровне) взяла на себя операционная система.
Наконец, СУБД дали средства для создания в каждом программном комплексе промежуточного слоя математического обеспечения, отделяющего собственно прикладные программы от используемых данных, эффективно реализующего поиск, размещение и прочие операции над данными и тем самым освобождающего от этой деятельности прикладных программистов. Этот слой частично состоит из системных программ СУБД, частично достраивается пользователем, средства для чего предоставляются специализированными языками описания данных и языками манипулирования данными, включаемыми в СУБД.
Эти языки дополняют традиционные языки программирования средствами для организации больших групп данных. Чтобы обеспечить возможность прямого использования этих средств в прикладных программах на традиционных языках, язык описания данных и язык манипулирования данными зачастую оформляются как расширение развитого языка программирования – включающего языка.
В настоящее время можно говорить о новом этапе представления данных в памяти ЭВМ - о создании информационно- вычислительных сетей и на их основе – распределенных баз данных коллективного пользования. Это приводит как к снижению затрат на создание и введение баз данных, так и к повышению качества хранимой информации, поскольку для ведения баз данных возможно привлечение более квалифицированных специалистов. Одновременно резко возрастает доступность этой информации для пользователей.
С появлением систем ИИ появилось новое понятие – «база знаний»
(БЗ) [1]. Следует как-то соотнести ставшие привычными понятия «данные и БД» с понятиями «знания и БЗ». Несомненно, что данные и структура базы данных в определенной степени отражают знания о предметной области и ее структуре. Тем не менее, имеются специфические признаки, отличающие знания от данных. В качестве таких специфических признаков знаний в связи с представлением их в ЭМВ можно выделить следующие четыре признака:
Ø внутренняя интерпретируемость;
Ø структурированность;
Ø связность;
Ø активность.
Если обратиться к структурированным данным, то некоторые из указанных признаков, свойственных знаниям, будут справедливы и для структур данных. Например, первый признак –интерпретируемость– явно просматривается в реляционной базе данных, где имена столбцов являются атрибутами отношений, имена которых указаны в строках. Внутренняя интерпретируемость предусматривает возможность установки для элемента данных связанной с ним системы имен. Система имен включает в себя индивидуальное имя, которое присвоено данной информационной единице. Наличие системы «избыточных» имен позволяет системе ИИ знать, что хранится в ее базе знаний, и, следовательно, уметь отвечать на нечеткие вопросы о содержимом базы знаний.
Второй признак – структурированность – можно рассматривать как свойство декомпозиции сложных объектов на более простые и установление связей между простыми объектами, что означает использование отношений «часть-целое», «класс-подкласс», «род-вид» и т.п. Отношения подобного рода встречаются и в иерархических и сетевых базах банных. Эти же отношения могут быть реализованы и в табличных базах данных.
Для третьего признака знаний – связность – практически нельзя найти аналогов в упоминавшихся базах данных. Знания наши связаны не только в смысле структуры. Они отражают закономерности относительно фактов, процессов, явлений и причинно-следственные отношения между ними. Связность характеризует возможность установления между информационными единицами самых разнообразных отношений (четких, нечетких, бинарных, составных), которые определяют семантику и прагматику связей явлений и фактов, а также отношений, определяющих смысл системы в целом.
Что касается четвертого признака – активность, то сложилось так, что при использовании ЭВМ порождающими новые знания являются программы, а данные пассивно хранятся в памяти ЭВМ. Человеку свойственна познавательная активность, другими словами, знания человека активны. И это принципиально отличает знания от данных. Например, обнаружение противоречий в знаниях становится побудительной причиной их преодоления и появления новых знаний, таким же стимулом активности является неполнота знаний, выражающаяся в необходимости их пополнения.
Знания, используемые для создания системы ИИ, ее работы, хранящиеся и вырабатываемые в ней, могут быть определены различным образом. В настоящее время используют три определения. Знания - это:
¨ результат, полученный познанием;
¨ система суждений с принципиальной и единой организацией, основанная на объективной закономерности;
¨ формализованная информация, на которую ссылаются или используют в процессе логического вывода.
Процесс решения задач с помощью простейшей модели системы ИИ представлен на рис 2.1.

Рис 2.1. Связь между знаниями и выводом при решении ин-
теллектуальной проблемы.
В данном случае знания – это информация, на которую ссылаются, когда делают различные заключения на основании имеющихся данных с помощью логических выводов. Если эта работа выполнятся программным путем, то знания – это обязательно информация, представленная в опре-деленной форме.
Постановка и решение любой задачи, связанной с обработкой данных и знаний, всегда связаны с ее «погружением» в подходящую предметную область.
Предметная область – это все предметы и события, которые составляют основу общего понимания необходимой для решения задачи информации. Мысленно предметная область представляется состоящей из реальных или абстрактных объектов, называемых сущностями. Так, решая задачу составления расписания обработки деталей на металлорежущих станках, мы вовлекаем в предметную область такие сущности, как конкретные станки, детали, интервалы времени, так и общие понятия «станок», «деталь», «тип станка».
При решении задач в некоторой предметной области знания удобно разделить на две большие категории – факты и эвристику. Первая категория указывает обычно на хорошо известные в данной предметной области обстоятельства, поэтому знания этой категории иногда называют текстовыми, имея в виду достаточную их освещенность в специальной литературе или учебниках. Вторая категория знаний основывается на собственном опыте специалиста в данной предметной области – эксперта, накопленном в результате многолетней практики. В так называемых экспертных системах эвристические знания играют решающую роль в повышении эффективности систем. Иными словами, в эту категорию входят такие знания, как «способы сосредоточения», «способы удаления бесполезных идей», «способы использования нечеткой информации» и т.п., позволяющие с большей эффективностью решать задачи. Тем не менее, из-за недостаточной научной обоснованности и отсутствия исчерпывающих сведений пользоваться такими знаниями нужно осмотрительно.
Знания, кроме того, можно разделить на факты(фактические знания) и правила (знания для принятия решения). Под фактами подразумеваются знания типа «А это А», они характерны для баз данных и сетевых моделей. Под правилами подразумеваются знания вида «ЕСЛИ – ТО». Кроме них существуют так называемые метазнания (знания о знаниях). Понятие «метазнания» указывает на знания, касающиеся способов использования знаний, и знания, касающиеся свойств знаний. Это понятие необходимо для управления базой знаний, логическим выводом, отождествления, обучения и т.п.
Совокупность предметной области и задач, решаемых в этой области, определяется понятием «проблемная область».
Данные и структуры данных далеко не в полной мере отражают особенности предметных областей. Хотя, вообще говоря, четкую грань между данными и знаниями провести можно не всегда, тем не менее, отличия между данными и знаниями существуют, и эти отличия привели к появлению специальных формализмов в виде моделей представления знаний в ЭВМ, отражающих в той или иной степени все четыре признака, характеризующих знания. Вернуться
Сейчас известны, по меньшей мере, четыре вида моделей и соответственно языков представления знаний[8,10,13]:
1) языки (модели) семантических сетей;
2) системы фреймов;
3) логические языки (модели);
4) продукционные системы.
Перейдем к описанию известных моделей представления знаний в ЭВМ.
Семантические сети
Первые сетевые модели появились в 60-е годы. Примерами их могут служить RX-коды, синтагматические цепи, семантические сети. В основе наиболее известной семантической модели лежит понятие сети, образованной помеченными вершинами и дугами. Вершины сети представляют некоторые сущности (объекты, события, процессы, явления), а дуги – отношения между сущностями, которые они связывают. По этой причине язык семантических сетей иногда называют реляционным. Наложив ограничения на описания вершин и дуг, можно получить сети различного вида. Если вершины не имеют собственной внутренней структуры, то соответствующие сети называют простыми сетями. Если вершины обладают некоторой структурой, то такие сети называются иерархическими сетями. На начальном этапе разработки систем ИИ использовались только простые сети, сейчас в большинстве приложений, использующих семантические сети, они являются иерархическими.
Отношения в сетях могут быть самого различного типа, что позволяет в достаточной мере обеспечить в семантической сети такой признак знаний, как связность. В общем случае это означает, что в виде семантической сети можно отобразить знания, заключенные в текстах на естественном языке.
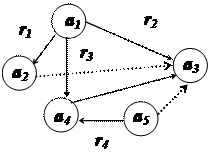 Возьмем, например, следующую фразу[1]: «Рыбак (a1) сел на плот (a2), переехал на другой берег (a3) и взял корзину (a4) с рыбой (a5). Эти объекты связаны отношениями: сел на (r1), переехал (r2), взял (r3) и находиться (r4). Сеть, соответствующая этому тексту, показана на рис 2.2.
Возьмем, например, следующую фразу[1]: «Рыбак (a1) сел на плот (a2), переехал на другой берег (a3) и взял корзину (a4) с рыбой (a5). Эти объекты связаны отношениями: сел на (r1), переехал (r2), взял (r3) и находиться (r4). Сеть, соответствующая этому тексту, показана на рис 2.2.
|
Исходя из логики реального мира и принятого способа описаний ситуаций в этом мире, можно считать данными и некоторые другие отношения, явно не присутствующие в исходном тексте. Эти дополнительные отношения показаны на рис.2.2 пунктиром. Пополненный текст:” Рыбак сел на плот и на плоту переехал на другой берег. На другом берегу находилась рыба. Рыба была в корзине. Рыбак взял корзину с рыбой”.
Следует подчеркнуть одно важное обстоятельство. Как показали исследования, в языках индоевропейской группы имеется не более 200 различных не сводимых друг к другу отношений. Комбинации этих базовых отношений позволяют выразить остальные отношения, фиксируемые в текстах на естественном языке. Это обстоятельство лежит в основе так называемого ситуационного управления. Кроме того, конечное множество базовых отношений позволяет надеяться, что в базах знаний можно представить любую предметную область и, более того, осуществить автоматическое построение семантических сетей непосредственно из текста.
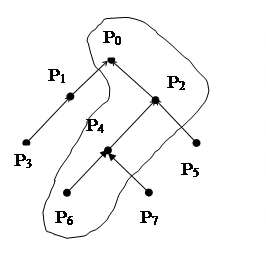
Основное отличие иерархических семантических сетей от простых состоит в возможности разделить сеть на подсети-пространства и устанавливать соотношение не только между вершинами, но и между пространствами. Все вершины и дуги являются элементами, по крайней мере, одного пространства. Отметим, что понятие пространства аналогично понятию скобок в математической нотации. Различные пространства, существующие в сети, могут быть упорядочены в виде дерева пространств, вершинам которого соответствуют пространства, а дугам – отношения «видимости». На рис 2.3 приведен пример дерева пространств, в соответствии с которым, например, из пространства-потомка P6 видимы все вершины и дуги, лежащие в пространствах-предках P4, P2 и P0, а остальные пространства «невидимы».
Отношение «видимости» позволяет группировать пространства в упорядоченные множества- «перспективы».Перспектива обычно используется для ограничения сетевых сущностей, «видимых» некоторой процедурой, работающей с сетью.
Рис. 2.3. Дерево пространств.
 |
Частным случаем семантических сетей являются сценарии или однородные семантические сети[7,10]. Это сети, объекты которых связаны единственным отношением строгого или нестрогого порядка с различной семантикой. Если, например, объектами-понятиями будут работы (или отдельные операции), а единственным отношением строгого порядка будет отношение следования, то мы придем к хорошо известному сетевому графику комплекса работ с так называемым французским представлением. Очевидно, что сценарии являются удобным средством составления планов.
Рис. 2.4. Связь БД и БЗ
На примере семантической сети общего вида можно установить различие между базой банных и базой знаний (см. рис.2.4). Предметная область есть множество допустимых состояний своих компонентов. Представленное чрез общие понятия и отношения между ними, это множество образует базу знаний – в виде так называемой интенсиональной семантической сети. С другой стороны, в зависимости от ситуации компоненты предметной области будут иметь конкретные значения, свойства, характеристики. Все эти конкретные данные о предметной области будут отображаться в так называемой экстенсиональной семантической сети или базе данных сетевой структуры.
Несколько слов о терминах «интенсиональный» и «экстенсиональный», заим-ствованных из семантики- науки о знаковых системах.
|
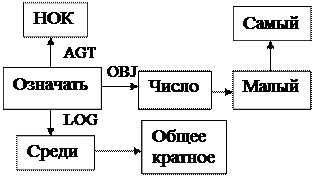
Рис 2.5. Семантическая сеть предложения (слева) и
структура данных семантической сети (справа).
В ЭВМ семантическая сеть реализуется в виде внутримашинной структуры данных, которая используется для представления отдельных слов и семантики. Например, семантическую сеть «НОК – это наименьшее общее кратное» на основе результатов структурного анализа можно переписать в виде структуры данных семантической сети[10], как показано на рис 2.5. Здесь С1, С2,…, С8 – узлы семантической сети, которые являются указателями списковой структуры; ТОК – печать соответствующей семантики, причем некоторое активное слово записывается в исходной форме; MODAL – время (оценка) и спряжение глагола; MOD – модифицированные слова; POST c помощью союза показывает модифицированное слово.
Положительная сторона представления знаний семантическими сетями заключается в том, что это весьма простой и понятный способ описания на основании отношений между элементами (узлами и дугами). Однако с увеличением размеров сети существенно увеличивается время поиска по сравнению со способами, не имеющими стратегии. Кроме того, им присуща проблема гарантии пригодности результатов вывода, включающая также проблему наследования свойств. Вернуться
Фреймовые модели
Семантические сети, несмотря на большие возможности, связанные с богатством средств для отображения отношений между понятиями и объектами, обладают некоторыми недостатками. Произвольная структура и различные типы вершин требуют большого разнообразия процедур обработки информации, что усложняет программное обеспечение ЭВМ. Это обусловило появление особых типов семантических сетей: синтагматические цепи, сценарии, фреймы и т.п. Остановимся на фреймовых представлениях.
Термин «фрейм» (frame – рамка) был предложен Минским [14]. Любое представление о предмете, объекте, стереотипной ситуации у человека как бы обрамлено характеристиками и свойствами объекта или ситуации, которые размещаются в так называемых слотах фрейма.
Формально под фреймом обычно понимают структуру следующего вида:
[ < f > , < V1 , g1 > , < V2 , g2 > , , < V3 , g3 > ,….., < Vn , g3 > ] .
Здесь f – имя фрейма, пара < Vi , gi > - это i – ый слот, где VI – имя слота, а gI – его значение. Значением слота может быть практически все что угодно (числа или математические соотношения, тексты на естественном языке, программы, правила вывода или ссылки на другие слоты данного фрейма или других фреймов и т.п.).
Фреймы иногда делят на две группы: фреймы-описания и ролевые фреймы. Рассмотрим примеры.
Фрейм-описание:
[ < фрукты > , < виноград, болгарский 20 т > , < яблоки, Джонатан 10 т > , < вишня, владимирская 200 кг > ] .
Ролевой фрейм:
[ < перевезти > , < что, прокат 300 т > , < откуда, Кривой Рог> , < куда, Одессу > , < чем, железнодорожным транспортом > , < когда, в декабре 1998 года > ] .
В ролевом фрейме в качестве имен слотов выступают вопросительные слова, ответы на которые являются значениями слотов. Если в примерах в общем выражении для фрейма убрать все значения слотов, оставив только имена, то получим конструкцию, называемую протофреймом (прототипом фрейма). Фреймы с конкретными значениями называются фреймами-экземплярами. Рассмотрим примеры.
Протофрейм:
[ < Cписок сотрудников > , < фамилия ( значение слота 1) > , < год рождения ( значение слота 2) > , < специальность ( значение слота 3) > , < стаж ( значение слота 4) > ] .
Фрейм – экземпляр:
[ < Cписок сотрудников > , < фамилия (Попов-Сидоров-Иванов-Петров) > , < год рождения (1965-1968-1947-1958) > , < специальность (слесарь-токарь-токарь-сантехник) > , < стаж (5-21-32-23) > ] .
Фреймы обладают свойством вложенности , то есть в качестве значения слота может выступать система имен слотов более глубокого уровня. Свойство вложенности, возможность иметь в качестве значений слотов ссылки на другие фреймы и на другие слоты того же самого фрейма обеспечивают фреймовым языкам удовлетворение требованиям структурированности и связности знаний[10]. С учетом возможности наследования структура данных фрейма может выглядеть так: (см. рис.2.6).
|
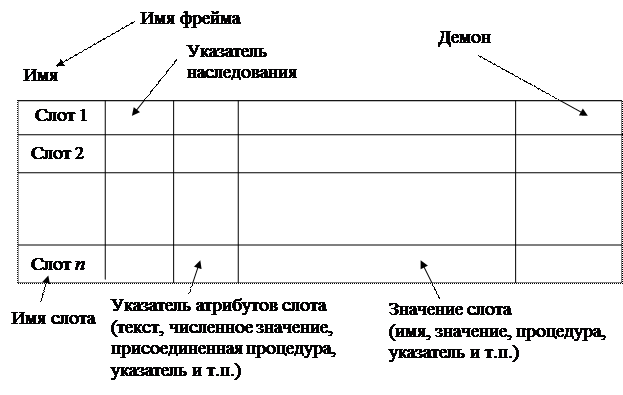
Имя фрейма – это идентификатор, присваиваемый фрейму. Фрейм должен иметь уникальное имя в системе. Слотов во фрейме может быть произвольное число. Некоторые из них определяются самой системой для выполнения специфических функций, а остальные определяются пользо-вателем. В их число входят слот IS-A, показывающий фрейм-родитель данного фрейма, слот указателей дочерних фреймов, который является списком указателей этих фреймов, слот для ввода имени пользователя, даты изменения, текста комментария и другие слоты. Каждый слот, в свою очередь, также представлен определенной структурой данных.
Имя слота - это идентификатор, присваиваемый слоту; слот должен иметь уникальное имя во фрейме. Некоторые слоты называются системными и используются при редактировании базы знаний и управлении выводом.
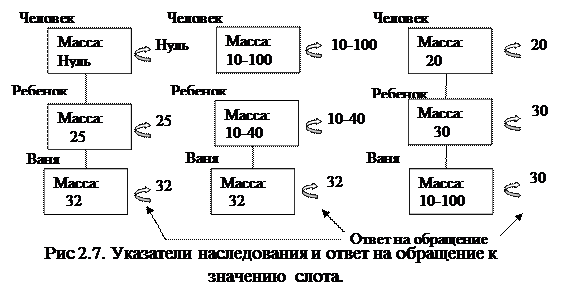
Указатели наследования касаются только фреймовых систем иерар-хического типа, основанных на отношениях «абстрактное - конкретное». Они показывают, какую информацию об атрибутах слотов во фрейме верхнего уровня наследуют слоты с такими же именами во фреймах нижнего уровня. Типичные указатели наследования:
Ø U (первая буква слова Unique - уникальный) – каждый фрейм может иметь различные слоты с различными значениями;
Ø S – все слоты должны иметь одинаковые значения;
Ø R – значения слотов фрейма нижнего уровня должны находиться в пределах, указанных значениями слотов верхнего уровня;
Ø О – при отсутствии указания значение слота фрейма верхнего уровня становится значением слота фрейма нижнего уровня, но в случае определения нового значения слотов фреймов нижних уровней указываются в качестве значений слотов.
Указатель О выполняет одновременно функции указателей U и S . Несмотря на то, что в большинстве систем допускается несколько вариантов указания наследования, существует немало и таких, где допускается только один вариант. В данном случае можно считать, что используется указатель О значения по умолчанию.
U –уникальный R –установление границ О – игнорировать
 |
Наличие имен фреймов и имен слотов означает, что значения, хранимые во фреймах, имеют характер отсылок и тем самым внутренне интерпретированы. Возможность размещения в качестве слотов приказов вызова тех или иных процедур для исполнения позволяет активизировать программы на основе имеющихся знаний. Таким образом, фреймовые языки удовлетворяют четырем основным признакам знаний – интерпретируемости, структурированности, связности и активности. Использование фреймов в фундаментальных науках дает возможность формирования более строгого понятийного аппарата и комплексирования обычных моделей с фреймовыми формализмами. Для описательных наук фреймы – это один из немногих способов формализации, создания понятийного аппарата. Вернуться
Дата добавления: 2016-03-27; просмотров: 1813;