Вероятностная оценка случайной погрешности
Характеристики статистических распределений. Вероятность 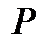 того, что случайная величина
того, что случайная величина 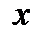 принимает значения в некотором интервале
принимает значения в некотором интервале 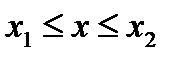 записывается в виде
записывается в виде
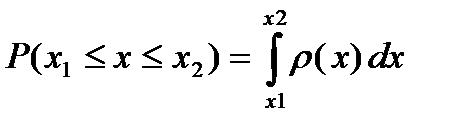 , (2.2.1)
, (2.2.1)
где 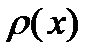 называется плотностью распределения вероятности случайной величины
называется плотностью распределения вероятности случайной величины 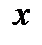 . Для краткости функцию
. Для краткости функцию 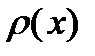 часто называют статистическим распределением. Поскольку
часто называют статистическим распределением. Поскольку 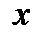 находится в интервале
находится в интервале 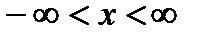 с вероятностью равной единице, функция
с вероятностью равной единице, функция 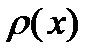 удовлетворяет условию нормировки
удовлетворяет условию нормировки
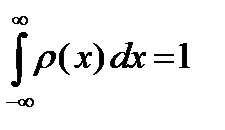 . (2.2.2)
. (2.2.2)
С учетом статистического распределения случайной величины ее среднее значение вычисляется по следующей формуле:
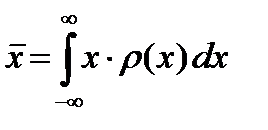 . (2.2.3)
. (2.2.3)
Если из генеральной совокупности всех возможных значений непрерывной случайной величины 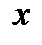 осуществляется конечная выборка дискретных значений
осуществляется конечная выборка дискретных значений 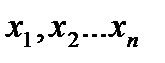 , то элементарный расчет среднего значения по формуле
, то элементарный расчет среднего значения по формуле
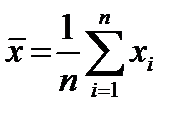 (2.2.4)
(2.2.4)
соответствует определению среднего (2.2.3) только при 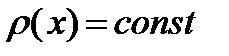 . Таким образом, даже для оценки точности вычисления средней величины
. Таким образом, даже для оценки точности вычисления средней величины 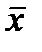 необходимо учитывать форму статистического распределения исходных данных.
необходимо учитывать форму статистического распределения исходных данных.
Статистические распределения принято оценивать по значениям их моментов. Моменты случайных величин, найденные без исключения систематических составляющих, называются начальными, а моменты для центрированных распределений — центральными.
Центральный момент 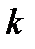 -го порядка для непрерывной случайной величины рассчитывается по формуле
-го порядка для непрерывной случайной величины рассчитывается по формуле
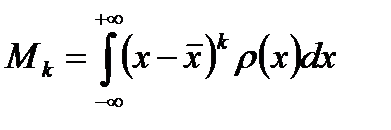 , (2.2.5)
, (2.2.5)
при этом 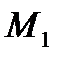 - математическое ожидание;
- математическое ожидание; 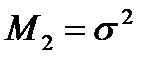 - дисперсия (для конечной выборки — среднеквадратичное отклонение (СКО));
- дисперсия (для конечной выборки — среднеквадратичное отклонение (СКО)); 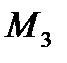 характеризует асимметрию распределения, а безразмерный коэффициент асимметрии
характеризует асимметрию распределения, а безразмерный коэффициент асимметрии 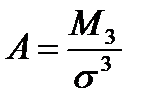 есть третий центральный момент, поделенный на СКО;
есть третий центральный момент, поделенный на СКО; 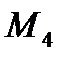 характеризует протяженность распределения, отношение
характеризует протяженность распределения, отношение 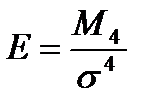 - эксцесс, -характеризует остроту вершины распределения.
- эксцесс, -характеризует остроту вершины распределения.
Наиболее широкое распространение при обработке экспериментальных данных получил центральный момент второго порядка 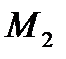 который повсеместно используют для оценки погрешностей измерений. Для конечной выборки (конкретного числа отсчетов
который повсеместно используют для оценки погрешностей измерений. Для конечной выборки (конкретного числа отсчетов 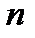 ) СКО принято рассчитывать по следующей формуле:
) СКО принято рассчитывать по следующей формуле:
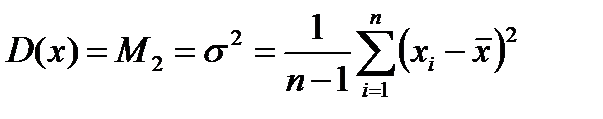 . (2.2.6)
. (2.2.6)
Эта формула, как и формула (2.2.4) для вычисления 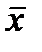 , не учитывает форму распределения и не является строгой. Ее широкое использование обусловлено двумя основными причинами:
, не учитывает форму распределения и не является строгой. Ее широкое использование обусловлено двумя основными причинами:
1. Это наиболее простая возможность оценить рассеяние случайной величины.
2. Значения случайных величин при экспериментальных измерениях имеют статистическое распределение, близкое к нормальному (гауссову), а для этого распределения среднеквадратичное отклонение 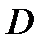 и квадрат дисперсии
и квадрат дисперсии 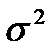 совпадают.
совпадают.
Оценку асимметрии и эксцесса при конечной выборке 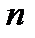 осуществляют по следующим формулам
осуществляют по следующим формулам
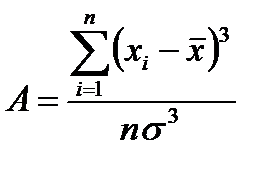 , (2.2.7)
, (2.2.7)
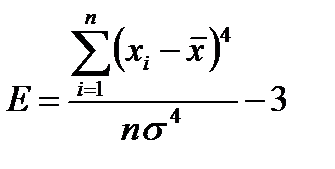 . (2.2.8)
. (2.2.8)
Число 3 в формуле (2.2.8) определяет эксцесс нормального распределения. Если эксцесс распределения отрицательный, то вершина функции распределения острее, чем у нормального распределения.
Определение этих характеристик распределений (моментов) называется точечными оценками, которые характеризуют распределение достаточно грубо.
Пусть в процессе экспериментальных измерений регистрируется сразу несколько случайных величин 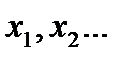 , каждая из которых имеет свое среднее значение
, каждая из которых имеет свое среднее значение 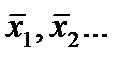 и дисперсию
и дисперсию 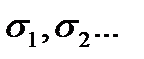 . Многомерная случайная величина
. Многомерная случайная величина 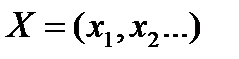 будет иметь многомерное распределение вероятностей
будет иметь многомерное распределение вероятностей 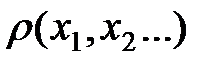 с условием нормировки
с условием нормировки
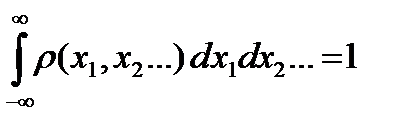 .
.
Величины 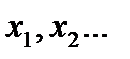 считаются статистически независимыми, если
считаются статистически независимыми, если 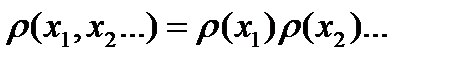 . Но эти величины могут быть статистически связаны, и для численной оценки этой связи двух случайных величин принято использовать смешанный момент второго порядка который называют корреляционным моментом или ковариацией.
. Но эти величины могут быть статистически связаны, и для численной оценки этой связи двух случайных величин принято использовать смешанный момент второго порядка который называют корреляционным моментом или ковариацией.
Для расчета корреляционного момента 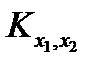 используется следующая формула:
используется следующая формула:
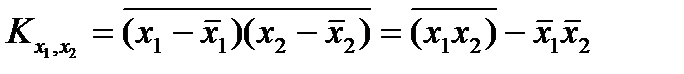 , (2.2.9)
, (2.2.9)
где черта сверху означает статистическое усреднение соответствующего выражения. Корреляционный момент есть смешанная дисперсия двух величин, поэтому для расчета коэффициента корреляции 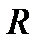 используется нормировка на дисперсию каждой из случайных величин:
используется нормировка на дисперсию каждой из случайных величин:

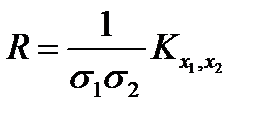 . (2.2.10)
. (2.2.10)
Коэффициент корреляции меняется в пределах от -1 до +1 и определяет степень связи случайных величин.
Правила сложения случайных погрешностей. При сложении погрешностей в сложных измерительных системах необходимо учитывать, насколько эти погрешности статистически независимы или коррелированы. Из приведенных выше формул может быть получено следующее правило сложение погрешностей двух случайных величин:
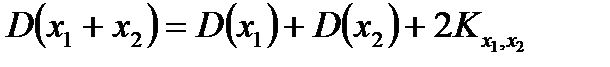 , (2.2.11)
, (2.2.11)
а дисперсия их суммы 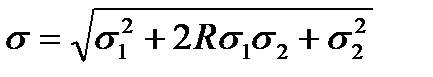 .
.
Таким образом, складывать СКО необходимо с учетом того, насколько случайные погрешности коррелированы.
Если:
1) 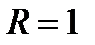 , то
, то 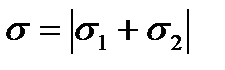 ;
;
2) 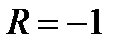 , то
, то 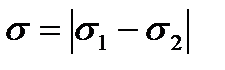 .
.
Как правило, при сложении погрешностей их делят на две группы: коррелированные и некоррелированные. Разделение на большее число групп (некоррелированные, слабо коррелированные, сильно коррелированные) слишком трудоемко. Поэтому на практике коррелированными погрешностями считаются те, у которых 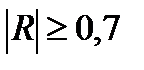 , остальные — некоррелированные.
, остальные — некоррелированные.
Рассмотрим пример коррелированных погрешностей. Пусть измеряется зависимость активного сопротивления 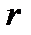 металлического проводника (длина
металлического проводника (длина 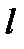 , площадь сечения
, площадь сечения 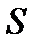 ) от температуры
) от температуры 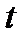 . Полученная экспериментально зависимость
. Полученная экспериментально зависимость 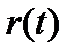 используется для проверки известной зависимости удельного сопротивления металлов
используется для проверки известной зависимости удельного сопротивления металлов 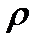 от температуры
от температуры
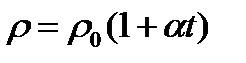 . (2.2.12)
. (2.2.12)
Для вычисления 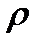 по экспериментальным данным приходится использовать размеры проводника:
по экспериментальным данным приходится использовать размеры проводника: 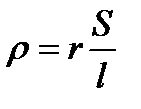 . Но размеры проводника, также как и его удельное сопротивление, зависят от температуры по законам теплового расширения. На построение зависимости (2.2.12) будут влиять погрешности измерения
. Но размеры проводника, также как и его удельное сопротивление, зависят от температуры по законам теплового расширения. На построение зависимости (2.2.12) будут влиять погрешности измерения 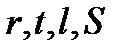 , но погрешности в измерении
, но погрешности в измерении 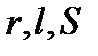 при разных значениях температуры неизбежно будут связаны (коррелированы).
при разных значениях температуры неизбежно будут связаны (коррелированы).
Центральная предельная теорема и распределение Гаусса. Как уже отмечалось, в подавляющем большинстве случаев считается, что случайные погрешности экспериментальных измерений имеют нормальное (гауссово) статистическое распределение. Этот факт имеет математическое обоснование в виде центральной предельной теоремы (ЦПТ – теорема):
Пусть случайная величина 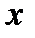 представляет собой сумму случайных величин
представляет собой сумму случайных величин 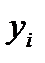 , т.е.
, т.е. 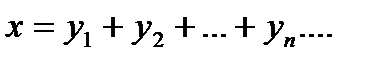 Если
Если 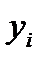 статистически независимы, то при их произвольном распределении и
статистически независимы, то при их произвольном распределении и 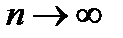 их сумма
их сумма 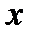 имеет нормальное распределение с плотностью вероятности
имеет нормальное распределение с плотностью вероятности
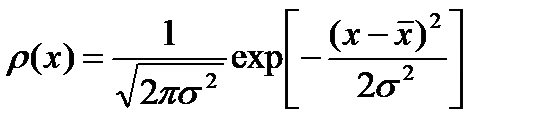 . (2.2.13)
. (2.2.13)
Зависимость 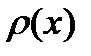 имеет колоколообразную форму с вершиной в точке
имеет колоколообразную форму с вершиной в точке 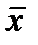 и полушириной
и полушириной  .
.
Таким образом, широкое распространение нормального статистического распределения имеет глубокую физическую природу: если случайная величина зависит от большого числа случайных факторов, то она имеет нормальное распределение вне зависимости от характеристик каждого из этих факторов.
Построение функциональных зависимостей при многократных измерениях. Пусть необходимо построить зависимость 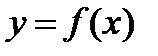 в том случае, если каждому значению
в том случае, если каждому значению 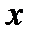 соответствует набор значений
соответствует набор значений 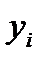 . В практических задачах в результате эксперимента имеется набор точек с координатами
. В практических задачах в результате эксперимента имеется набор точек с координатами 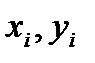 , как это показано на рис.2.3.
, как это показано на рис.2.3.
Наиболее очевидный и традиционный способ построения зависимости 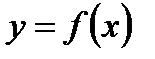 заключается в следующем: для каждого значения
заключается в следующем: для каждого значения 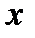 в определенном интервале находится среднее значение по
в определенном интервале находится среднее значение по 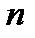 попавшим в интервал точкам
попавшим в интервал точкам
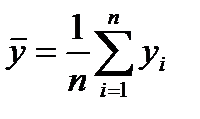
и рассчитывается среднеквадратичное отклонение 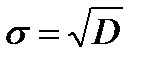 , где
, где 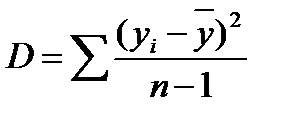 .
.
При этом возникает необходимость в расчете погрешности определения 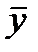 , а значение СКО не дает возможности оценить достоверность оценки. Таким образом, возникают вопросы:
, а значение СКО не дает возможности оценить достоверность оценки. Таким образом, возникают вопросы:
1) с какой вероятностью значения 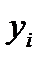 попадают в обозначенный СКО интервал?
попадают в обозначенный СКО интервал?
2) насколько точна оценка 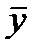 ?
?
3) Как распределены значения 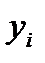 в этом интервале?
в этом интервале?
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Рис.2.3
В общем случае определение СКО не является лучшим способом оценки погрешностей. Чаще всего его используют на практике потому, что это единственная оценка, легко рассчитываемая в аналитическом виде.
Суть вероятностного описания полосы погрешностей искомой зависимости 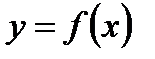 состоит в том, что необходимо сделать следующее утверждение: при данном значении
состоит в том, что необходимо сделать следующее утверждение: при данном значении 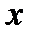
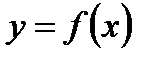 принимает значение в определенном интервале (доверительном) с необходимой вероятностью (рис.2.3).
принимает значение в определенном интервале (доверительном) с необходимой вероятностью (рис.2.3).
Основная проблема для такого заключения состоит в конечности выборки 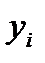 , где
, где 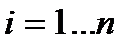 . Чаще всего в таких задачах используются квантильные оценки. Квантиль — прямая
. Чаще всего в таких задачах используются квантильные оценки. Квантиль — прямая 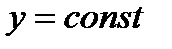 , делящая плотность вероятности
, делящая плотность вероятности 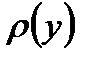 на определенные части. На рис.2.4 показаны 50-, 25- и 5-процентные квантили для нормального распределения.
на определенные части. На рис.2.4 показаны 50-, 25- и 5-процентные квантили для нормального распределения.
|
|
|
|
|
|
Рис.2.4
Грубая оценка интервала неопределенности и определение доверительного значения погрешности проводятся следующим образом: погрешности 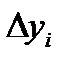 располагаются в порядке возрастания
располагаются в порядке возрастания 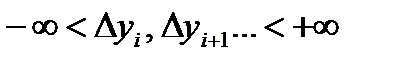 . Тогда в предположении равномерного распределения
. Тогда в предположении равномерного распределения 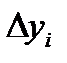
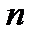 квантилей делят график плотности вероятности на
квантилей делят график плотности вероятности на 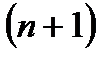 часть. Отбросив крайние значения
часть. Отбросив крайние значения 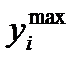 и
и 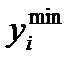 , получим, что вероятность попадания величины
, получим, что вероятность попадания величины 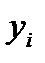 в диапазон
в диапазон 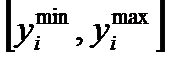 равна
равна 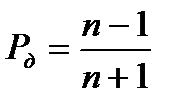 .
.
Таким образом, на основании изложенного можно утверждать, что оценка погрешности определена с доверительной вероятностью не более чем 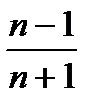 в доверительном интервале
в доверительном интервале 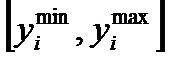 . Это самая грубая оценка.
. Это самая грубая оценка.
Описанный способ предполагает равномерное распределения 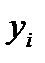 в заданном интервале, что на практике никогда не выполняется.
в заданном интервале, что на практике никогда не выполняется.
Часто кроме крайних значений величины отбрасывается определенное число 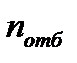 . В этом случае
. В этом случае
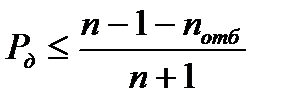 . (2.2.14)
. (2.2.14)
Неравенство (2.2.14) предполагает, что для фиксированной доверительной вероятности 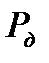 можно определить необходимое количество отсчетов
можно определить необходимое количество отсчетов
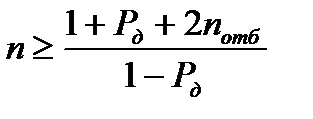 . (2.2.15)
. (2.2.15)
С увеличением выборки 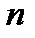 можно увеличить доверительную вероятность попадания
можно увеличить доверительную вероятность попадания 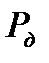 в заданный интервал. В таблице 2.1 приведен необходимый объем выборки для заданных значений
в заданный интервал. В таблице 2.1 приведен необходимый объем выборки для заданных значений 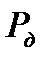 , рассчитанный по формуле (2.2.15) при
, рассчитанный по формуле (2.2.15) при 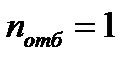 .
.
Таблица 2.1
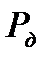
| 0,8 | 0,9 | 0,95 | 0,98 | 0,99 | 0,995 | 0,997 |
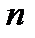
|
Поскольку для значений 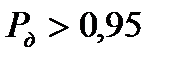 требуется слишком большая выборка
требуется слишком большая выборка 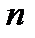 , то обычно для статистических оценок (в социально-экономических науках) используется
, то обычно для статистических оценок (в социально-экономических науках) используется 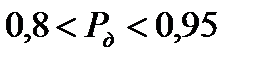 .
.
СКО при вычислении среднего зависит от числа отсчетов 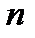 как
как
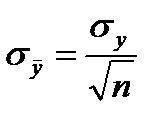 , (2.2.16)
, (2.2.16)
то есть при усреднении величины 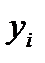 по
по 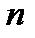 отсчетам мы уменьшаем рассеяние данных в
отсчетам мы уменьшаем рассеяние данных в 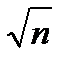 раз.
раз.
Чтобы перейти от оценки СКО к оценке доверительного интервала с учетом вероятности 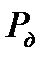 , необходимо учитывать статистическое распределение
, необходимо учитывать статистическое распределение 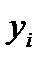 .
.
Закон распределения средней величины 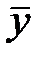 всегда близок к нормальному вне зависимости от того, как распределены исходные данные
всегда близок к нормальному вне зависимости от того, как распределены исходные данные 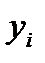 . Это следует из центральной предельной теоремы (ЦПТ) и справедливо при
. Это следует из центральной предельной теоремы (ЦПТ) и справедливо при 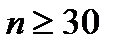 . Поэтому переход от оценки СКО
. Поэтому переход от оценки СКО 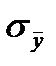 к квантильной оценке доверительного интервала
к квантильной оценке доверительного интервала  с доверительной вероятностью
с доверительной вероятностью 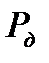 осуществляется следующим образом
осуществляется следующим образом
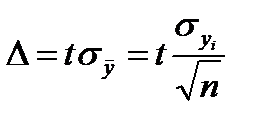 , (2.2.17)
, (2.2.17)
где 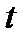 - нормированная квантиль нормального распределения, соответствующая
- нормированная квантиль нормального распределения, соответствующая 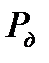 . Смысл определения величины
. Смысл определения величины 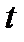 заключается в том, что в зависимости от размеров выборки
заключается в том, что в зависимости от размеров выборки 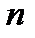 доверительный интервал может изменяться по отношению к оценке СКО. Доверительному интервалу
доверительный интервал может изменяться по отношению к оценке СКО. Доверительному интервалу  всегда необходимо поставить в соответствие
всегда необходимо поставить в соответствие 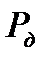 или уровень значимости
или уровень значимости 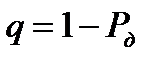 . Значения
. Значения 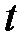 , соответствующие разным уровням значимости для нормального распределения (выборка
, соответствующие разным уровням значимости для нормального распределения (выборка 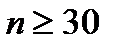 ) приведены в таблице 2.2.
) приведены в таблице 2.2.
Таблица 2.2
|
| 0,8 | 0,9 | 0,95 | 0,98 | 0,99 | 0,995 | 0,998 |
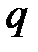
| 0,2 | 0,1 | 0,05 | 0,02 | 0,01 | 0,005 | 0,002 |
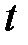
| 1,28 | 1,64 | 1,96 | 2,33 | 2,58 | 2,81 | 3,09 |
Величина 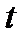 определяется следующим выражением:
определяется следующим выражением:
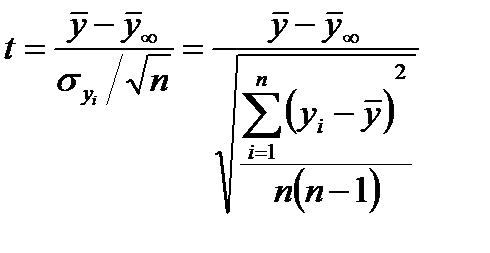 , (2.2.18)
, (2.2.18)
где 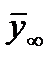 - среднее значение для генеральной совокупности с нормальным распределением.
- среднее значение для генеральной совокупности с нормальным распределением.
Статистическое распределение 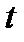 - известное распределение Стьюдента (рис.2.5).
- известное распределение Стьюдента (рис.2.5).
Распределение Стьюдента. Его плотность вероятности описывается через специальные функции:
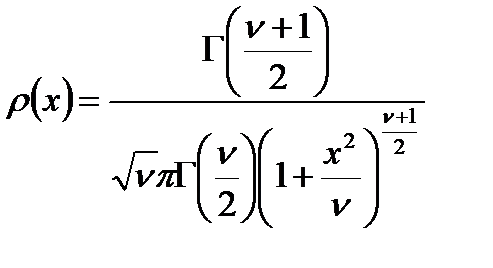 , (2.2.19)
, (2.2.19)
где параметр 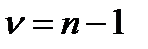 определяется числом степеней свободы
определяется числом степеней свободы 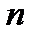 . Гамма-функция
. Гамма-функция 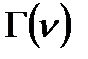 обладает следующими свойствами:
обладает следующими свойствами:
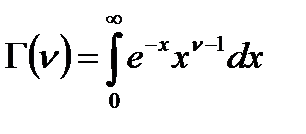 ;
; 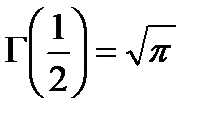 ;
; 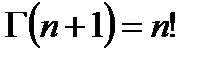 .
.
На рис.2.5 приведено распределение Стъюдента при 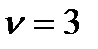 (кривая 2) и нормальное распределение (кривая 1). Как видно из рисунка, распределение Стъюдента симметрично и несколько шире нормального распределения, и совпадает с ним при
(кривая 2) и нормальное распределение (кривая 1). Как видно из рисунка, распределение Стъюдента симметрично и несколько шире нормального распределения, и совпадает с ним при 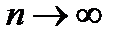 . Основной смысл этого распределения состоит в том, что оно описывает отклонения среднего значения
. Основной смысл этого распределения состоит в том, что оно описывает отклонения среднего значения 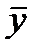 , рассчитанного по малой конечной выборке (
, рассчитанного по малой конечной выборке ( 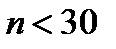 ) от среднего значения генеральной совокупности
) от среднего значения генеральной совокупности 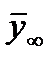 .
.
|
|
|
|
|
Рис.2.5
Это распределение широко табулировано и значение 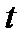 при вычислении доверительного интервала по формуле (2.2.17) для конкретной выборки
при вычислении доверительного интервала по формуле (2.2.17) для конкретной выборки 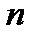 всегда можно найти в справочной литературе. Величины
всегда можно найти в справочной литературе. Величины 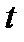 для двух значений уровня значимости
для двух значений уровня значимости 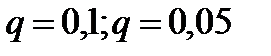 приведены в таблице 2.3.
приведены в таблице 2.3.
Таблица 2.3
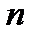
| 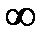
| |||||||||
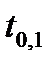
| 6,31 | 2,92 | 2,35 | 2,13 | 1,94 | 1,83 | 1,76 | 1,73 | 1,70 | 1,64 |
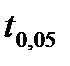
| 12,7 | 4,30 | 3,18 | 2,78 | 2,45 | 2,26 | 2,14 | 2,09 | 2,04 | 1,96 |
Как видно из таблицы, при 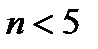 значения
значения 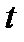 сильно возрастают и доверительный интервал в несколько раз превышает СКО (см. 2.2.17), что делает оценку практически бессмысленной. Однако при
сильно возрастают и доверительный интервал в несколько раз превышает СКО (см. 2.2.17), что делает оценку практически бессмысленной. Однако при 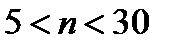 отличие квантили от ее значения для нормального распределения не превышает 30% . Распределение Стъюдента используется именно для такого объема выборки из генеральной совокупности, распределенной по нормальному закону.
отличие квантили от ее значения для нормального распределения не превышает 30% . Распределение Стъюдента используется именно для такого объема выборки из генеральной совокупности, распределенной по нормальному закону.
Построение статистических распределений и критерии оценивания. Таким образом, для построения вероятностной модели эксперимента необходимо знать, по какому закону распределены экспериментальные данные. Для оценки закона распределения служат различные критерии, позволяющие с определенной вероятностью по конечной выборке оценить распределение генеральной совокупности данных.
В общем случае для оценки статистического распределения необходимо действовать по следующему алгоритму:
1. Построение гистограммы.
1.1. Нахождение центра.
1.2. Симметрирование гистограммы.
1.3. Сглаживание.
2. Аппроксимация полученной гистограммы к распределению.
3. Проверка построенного распределения по критериям согласия.
При построении гистограммы (рис.2.6) важно выбрать необходимое число интервалов 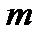 в которые попадает случайная величина
в которые попадает случайная величина 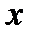 (обычно
(обычно 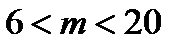 ). Затем по вертикальной оси гистограммы откладывается количество отсчетов
). Затем по вертикальной оси гистограммы откладывается количество отсчетов 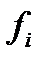 или нормированная частота
или нормированная частота 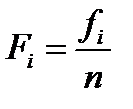 , попадающих в
, попадающих в 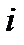 -й интервал (
-й интервал ( 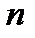 - общий объем случайной выборки). Если при малой выборке
- общий объем случайной выборки). Если при малой выборке 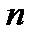 выбрано слишком большое число столбцов
выбрано слишком большое число столбцов 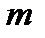 , то гистограмма может оказаться очень неравномерной (см. рис. 2.6,а) и судить о форме статистического распределения невозможно. Если исходить из того, что генеральная совокупность имеет гладкую форму распределения, то выбросы и провалы в гистограмме можно считать случайным шумом вызванным попаданием
, то гистограмма может оказаться очень неравномерной (см. рис. 2.6,а) и судить о форме статистического распределения невозможно. Если исходить из того, что генеральная совокупность имеет гладкую форму распределения, то выбросы и провалы в гистограмме можно считать случайным шумом вызванным попаданием 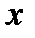 в тот или иной столбец. Тогда задачу выбора числа
в тот или иной столбец. Тогда задачу выбора числа 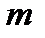 можно считать задачей оптимальной фильтрации.
можно считать задачей оптимальной фильтрации. 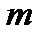 должно быть таким, чтобы максимально сглаживать но при этом минимально искажать случайную зависимость, описывающую распределение.
должно быть таким, чтобы максимально сглаживать но при этом минимально искажать случайную зависимость, описывающую распределение.
|
|
|
|
а б
Рис.2.6
Для выбора числа 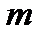 в литературе предлагается большое количество формул, мы приведем лишь три из них:
в литературе предлагается большое количество формул, мы приведем лишь три из них:
1)формула Старджеса: 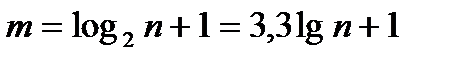 ;
;
2) 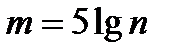 ;
;
3) 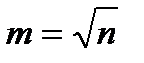 .
.
В предположении симметричности распределения число столбцов должно быть нечетным для однозначного определения центра распределения. Для его нахождения рассчитывают медиану или 50% - квантиль (половина выборки – больше, а половина – меньше этого числа). Медиана может не совпадать со средним значением 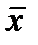 .
.
Симметрирование гистограммы состоит в переносе некоторого числа отсчетов 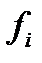 из данного столбца в симметричный с ним столбец для их выравнивания.
из данного столбца в симметричный с ним столбец для их выравнивания.
Построение сглаженной гистограммы и методы ее аппроксимации функциональной зависимостью 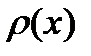 будут рассмотрены в следующей главе.
будут рассмотрены в следующей главе.
Для идентификации распределения 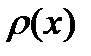 используются критерии согласия. Наиболее распространен критерий
используются критерии согласия. Наиболее распространен критерий 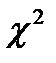 (критерий Пирсона). Он используется при проверке гипотез о принадлежности выборки к определенной генеральной совокупности.
(критерий Пирсона). Он используется при проверке гипотез о принадлежности выборки к определенной генеральной совокупности.
Для этого выбирается 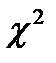 по формуле
по формуле
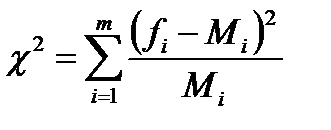 ,
,
где 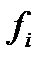 - число значений случайной величины, попавшей в
- число значений случайной величины, попавшей в 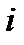 -й интервал (высота столбца в гистограмме на рис.2.7);
-й интервал (высота столбца в гистограмме на рис.2.7); 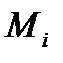 - значение частоты в выбранной модели распределения.
- значение частоты в выбранной модели распределения.
|
|
|
|
|
|
|
|
|
|
Рис.2.7
Критерий Пирсона дает 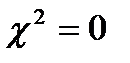 , если в центрах всех столбцов гистограммы выполняется равенство
, если в центрах всех столбцов гистограммы выполняется равенство 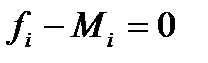 .
.
Критерий 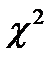 , кроме того, позволяет произвести сравнение двух моделей распределений в том случае, если для них используется разное число столбцов.
, кроме того, позволяет произвести сравнение двух моделей распределений в том случае, если для них используется разное число столбцов.
В общем случае  существенно возрастает с увеличением числа столбцов, но для квантилей распределения
существенно возрастает с увеличением числа столбцов, но для квантилей распределения 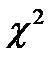 имеются специальные таблицы, в которых используется число степеней свободы
имеются специальные таблицы, в которых используется число степеней свободы
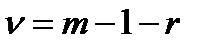 ,
,
где 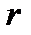 - число параметров, необходимых для описания распределения.
- число параметров, необходимых для описания распределения.
Для нормального распределения достаточно определить первые два момента, поэтому 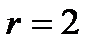 . В отличие от распределения Стьюдента, рассчитанного для нормальной генеральной совокупности, критерий
. В отличие от распределения Стьюдента, рассчитанного для нормальной генеральной совокупности, критерий 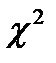 может использоваться для любых распределений.
может использоваться для любых распределений.
Второй пример широко используемого критерия - критерий Колмогорова-Смирнова. Он позволяет сравнить две независимые выборки и ответить на вопрос, относятся ли они к одной генеральной совокупности. Его удобство состоит в том, что для использования нет необходимости строить гистограмму.
В качестве статистики служит наибольшая по модулю разница между нормированными частотами в двух выборках
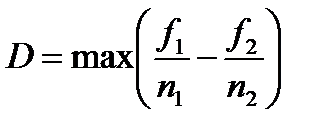 .
.
При 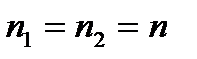 (рис.2.8)
(рис.2.8) 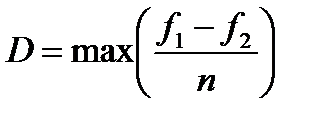 .
.
Величина 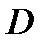 табулирована и для
табулирована и для 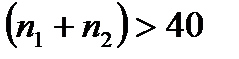 можно задать граничное значение
можно задать граничное значение
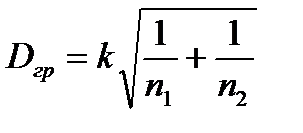 ,
,
где 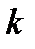 - постоянная, зависящая от уровня значимости
- постоянная, зависящая от уровня значимости 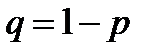 (вероятность ошибки при идентификации распределения). Для этой величины имеется приближенная аналитическая формула
(вероятность ошибки при идентификации распределения). Для этой величины имеется приближенная аналитическая формула 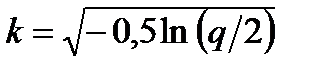 . Если выборка объемом
. Если выборка объемом 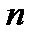 сопоставляется с аналитической моделью распределения
сопоставляется с аналитической моделью распределения 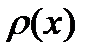 (
( 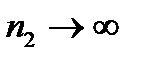 ), то
), то 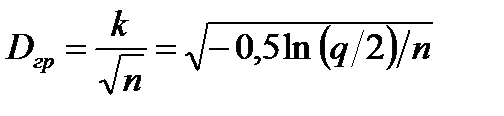 . Отсюда может быть оценена вероятность ошибки идентификации распределения по выборке объемом
. Отсюда может быть оценена вероятность ошибки идентификации распределения по выборке объемом 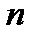 :
:
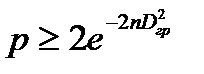 .
.
|
|
|
Рис.2.8
Для оценки разницы между дисперсиями двух конечных выборок из нормальной совокупности используется критерий Фишера. В качестве значения критерия берут отношение большей дисперсии к меньшей
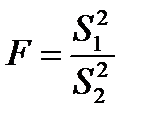 ,
,
где 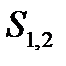 — среднеквадратичные отклонения.
— среднеквадратичные отклонения.
Вычисленное таким образом значение критерия сравнивается с табулированным значением в соответствии с уровнем значимости 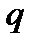 для степеней свободы
для степеней свободы 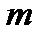 и
и 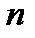 распределений (
распределений ( 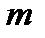 и
и 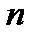 — величины выборок).
— величины выборок).
Дата добавления: 2015-12-11; просмотров: 2439;