Выбор информативных признаков
Сильной стороной нейронных сетей является возможность получения результатов при минимуме априорных знаний. Поскольку заранее обычно неизвестно насколько полезны те или иные входные переменные (это компоненты входных векторов) для предсказания значений выходов, возникает соблазн увеличивать число входных переменных в надежде на то, что сеть сама определит, какие из них наиболее значимы. Однако с ростом числа входов (размерности входных векторов) сложность обучения нейронной сети, как правило, быстро возрастает, а точность предсказания падает [3]. Следует также учитывать, что входные данные сети формируется в результате различных измерений, зачастую достаточно сложных и дорогих. Например, в диагностике заболеваний входными данными являются значения различных анализов, получение которых является зачастую дорогостоящей процедурой. Поэтому необходимо уменьшать количество входов. Эта процедура уменьшения количества входов называется понижением размерности, так как в результате этой процедуры уменьшается размерность входных векторов.
Размерность данных может быть понижена двумя способами:
– удалением тех переменных, которые несут наименьшее количество информации и обладают наименьшей прогнозирующей способностью;
– проектированием данных с высокой размерностью в пространство с меньшей размерностью. Этот метод включает преобразование набора данных в меньшее количество новых переменных, которые как можно полнее описывают исходный набор данных.
Проблема выбора информативных признаков является самостоятельной проблемой в машинном обучении и не решена до конца. Причем информативность признаков является относительным понятием. Один набор признаков может быть информативным для решения одной задачи и не информативным для решения другой задачи.
Содержательный анализ информативных признаков является сложной задачей, так как бесполезная на первый взгляд переменная в совокупности с другими переменными может нести полезную информацию. Некоторые переменные, обычно не используемые в конкретном анализе, позволяют выявить интересные зависимости. Поэтому целесообразно применять формализованные методы.
Для отбора информативных признаков можно применить к обучающей выборке методы математической статистики, не экспериментируя с нейронной сетью. Например, имеет смысл удалить те переменные, которые статистически связаны с другими входными переменными. Для этого вычисляется ковариационная матрица, содержащая ковариации между всеми парами входных переменных. Пары переменных с высокими значениями ковариации являются статистически зависимыми, поэтому одна переменная из пары может быть исключена из входных данных. Можно удалить входные переменные, которые не оказывают существенного влияния на выход сети. Допустим, что сеть имеет единственную выходную переменную. Построив ковариационную матрицу между входными переменными и выходной переменной, можно попытаться удалить переменные, слабо коррелированные с выходом. Можно использовать дисперсионный анализ [26, 27] для исследования влияния признаков на изменчивость выходов сети. Если изменения признака статистически не влияют на средние значения выходов сети, то такой признак можно исключить. Но статистические методы используют линейные модели. Распространять результаты, полученные на линейных моделях, на нейронные сети, представляющие собой нелинейные модели, нужно с большой осторожностью. Поэтому невозможно исключить эксперименты с нейронной сетью. Кроме того, статистические методы отбора информативных признаков довольно сложны и, как правило, выдвигают требования к законам распределения входных данных.
Поэтому основным подходом является отбор информативных признаков в процессе обучения сети [28]. Сеть обучается на полном и сокращенных наборах признаков. При этом необходимо подбирать структуру сети (она может быть разной при разных наборах обучающих признаков) и обучать разные сети. Если сокращенный набор несущественно снижает показатель качества работы сети (например, вероятность правильного распознавания образа), то можно применить сокращенный набор. Такой подход достаточно трудоемок, так как приходится многократно обучать сеть и подбирать структуру сети. При обучении на сокращенном наборе возможно усложнение сети (увеличение числа нейронов) [28]. Достоинством подхода является отсутствие сложных математических процедур.
Открытым остается вопрос, как выбирать сокращенные наборы входных данных. На практике часто используют такой прием. Весовые коэффициенты сети инициализируют малыми случайными значениями. Считается, что на весовые коэффициенты первого слоя, мало изменившиеся по сравнению с исходными значениями, подаются "бесполезные" входные переменные, которые можно исключить. Строго говоря, это не всегда справедливо. Поэтому необходимо испытать сеть на сокращенном таким способом наборе данных (возможно, придется подбирать структуру сети).
В анализе данных [8] известны методы выбора информативных признаков, которые могут быть применены для нейронных сетей. Алгоритм последовательного сокращения признаков (алгоритм Del) использует исключение наименее информативных признаков. Пусть из 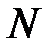 признаков необходимо выбрать наиболее информативный набор признаков, состоящий из
признаков необходимо выбрать наиболее информативный набор признаков, состоящий из 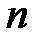 признаков (
признаков ( 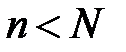 ). Сначала из набора исключается первый признак, строится и обучается сеть, находится показатель качества работы сети (например, ошибка распознавания образов)
). Сначала из набора исключается первый признак, строится и обучается сеть, находится показатель качества работы сети (например, ошибка распознавания образов) 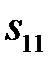 , который дают оставшиеся
, который дают оставшиеся 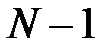 признаков. Далее первый признак возвращается в набор, исключается второй признак и оценивается показатель
признаков. Далее первый признак возвращается в набор, исключается второй признак и оценивается показатель 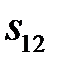 . Это поочередное исключение одного признака повторяется
. Это поочередное исключение одного признака повторяется 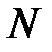 раз. Среди величин
раз. Среди величин 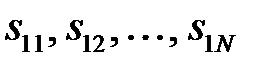 находится величина, соответствующая самому высокому показателю качества работы сети. Она указывает на признак, исключение которого было бы наименее ощутимым. Этот признак исключается из набора. Далее аналогично испытываются оставшиеся признаков. Процесс исключения продолжается
находится величина, соответствующая самому высокому показателю качества работы сети. Она указывает на признак, исключение которого было бы наименее ощутимым. Этот признак исключается из набора. Далее аналогично испытываются оставшиеся признаков. Процесс исключения продолжается 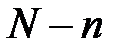 раз, пока не останется
раз, пока не останется 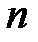 признаков. Можно не задавать заранее количество допустимых признаков, а остановиться на наборе, обеспечивающем приемлемый показатель качества работы сети.
признаков. Можно не задавать заранее количество допустимых признаков, а остановиться на наборе, обеспечивающем приемлемый показатель качества работы сети.
В алгоритме последовательного добавления признаков (алгоритм Add) сначала строится и обучается сеть по каждому из 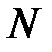 исходных признаков. В сокращенный набор включается признак, обеспечивший наилучший показатель качества работы сети. Затем к нему по очереди добавляются по одному из
исходных признаков. В сокращенный набор включается признак, обеспечивший наилучший показатель качества работы сети. Затем к нему по очереди добавляются по одному из 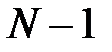 оставшихся признаков, и выбирается самая информативная пара признаков. К ней таким же путем подбирается наилучший третий признак из оставшихся
оставшихся признаков, и выбирается самая информативная пара признаков. К ней таким же путем подбирается наилучший третий признак из оставшихся 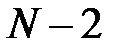 и так продолжается до получения системы из
и так продолжается до получения системы из 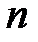 признаков.
признаков.
Трудоемкость этого алгоритма приблизительно такая же, как и алгоритма Del, однако результаты, получаемые алгоритмом Add, обычно лучше, чем у Del. Объясняется это тем, что в алгоритме Del обучение начинается с выборки большой размерности, а на выборках большой размерности сеть обычно обучается хуже, чем на выборках малой размерности.
Алгоритмы Add и Del относятся к так называемым "жадным" алгоритмам, в которых находится оптимальное решение на каждом шаге, но не гарантируется получение оптимального решения на всех шагах.
Известны алгоритмы, объединяющие алгоритмы Add и Del. Так в алгоритме AddDel сначала по алгоритму Add выбирается некоторое количество признаков. Затем часть из них исключается алгоритмом Del. То есть алгоритм Del исключает наименее информативные из отобранных признаков. Затем алгоритм Add добавляет признаки, а алгоритм Del исключает часть признаков. Такое чередование алгоритмов Add и Del продолжается до достижения заданного количества признаков 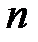 .
.
Известен алгоритм DelAdd, использующий обратную стратегию: поочередную работу алгоритма Del и Add. Сначала работает алгоритм Del. После сокращения некоторого количества признаков включается алгоритм Add, который возвращает в набор ошибочно исключенные из него признаки. В [8] указано, что алгоритм AddDel приводит к лучшим результатам, чем алгоритмы Add, Del и DelAdd.
Следует отметить, что в регрессионном анализе рассмотренные алгоритмы известны как шаговая регрессия (Stepwise Regression) [29]. Известны и другие методы отбора признаков [8, 30, 31].
Дата добавления: 2015-12-08; просмотров: 2355;