Виды трансформации данных
Трансформация данных — это преобразование данных к определенному представлению, формату или виду, оптимальному с точки зрения конкретного метода анализа [6]. Для разных задач анализа могут потребоваться разные методы трансформации. Типичными средствами трансформации данных являются следующие.
Преобразование временны́х данных. Оптимизация представления данных с целью обеспечения эффективного анализа во всех возможных интервалах даты и времени.
Квантование — разбиение диапазона возможных значений числового признака на заданное количество интервалов и отнесение значения признака к одному из интервалов. В результате квантования числовые значения становятся качественными (не числовыми). Например, для среднего балла учащегося можно ввести интервалы: низкий балл, средний балл, высокий балл. И вместо числового значения балла рассматривать качественное значение, например, "высокий балл". Использование квантования бывает полезным при решении задач классификации. Недостатком квантования является отнесение близких числовых значений, лежащих по разные стороны от границы интервала, к разным качественным признакам.
Сортировка. Изменение порядка следования записей исходной выборки данных.
Слияние. Объединение двух таблиц по одноименным полям или дополнение одной таблицы записями из другой, которые отсутствуют в дополняемой таблице. Слияние применяется в тех случаях, когда информацию в анализируемой выборке данных необходимо дополнить информацией из другой выборки. Операция слияния является одним из способов обогащения данных: если выборка содержит недостаточно данных для анализа, то ее можно дополнить недостающей информацией из другой выборки.
Группировка. Очень часто информация, интересующая аналитика, в таблице разобщена, разбросана по отдельным полям и записям. Используя группировку, можно объединить ее в минимально необходимое количество полей и значений. Обычно предусматривают возможность выполнения и обратной операции – разгруппировки.
Настройка набора данных. Изменение имен, типов и назначения полей исходной выборки данных. Например, поле, содержащее числовую информацию, в источнике данных по какой-либо причине имеет строковый тип. Для работы с числовыми данными этого поля их следует преобразовать к числовому типу.
Табличная подстановка значений. Замена значений в исходной выборке данных на основе таблицы подстановки. Таблица подстановки содержит пары "исходное значение – новое значение". Каждое значение выборки данных проверяется на соответствие исходному значению таблицы подстановки, и если такое соответствие найдено, то значение выборки изменяется на соответствующее новое значение из таблицы подстановки. Это удобный способ для автоматической корректировки значений.
Вычисляемые значения. Получение информации, которая отсутствует в явном виде в исходных данных, но может быть получена на основе вычислений над имеющимися значениями. Например, если известны цена и количество товара, то сумма может быть рассчитана как их произведение.
Кодирование данных — представление всех данных в виде чисел.
Нормализация (масштабирование). Преобразование диапазона изменения значений числового признака в другой диапазон, более удобный для применения аналитических алгоритмов, а также согласование диапазонов изменений различных признаков. Часто используется приведение к единице, когда весь имеющийся диапазон данных нормализуется в интервал [0; 1] или [-1; 1]. Нормализация широко используется в нейронных сетях.
Кодирование данных
Нейронные сети работают только с числами, так как их работа основана на арифметических операциях суммирования произведений входных сигналов на синаптические веса. Поэтому все входные и выходные данные нейронной сети должны быть закодированы в виде чисел. Можно выделить три основных типа переменных на входах и выходах нейронной сети (мы не рассматриваем кодирование изображений, текстов и звуков) [22]:
1. Бинарные переменные (возможен только один из вариантов — истина или ложь).
2. Качественные переменные.
3. Числа.
Переменные качественного типа — это переменные с конечным числом значений. Причем нельзя ввести расстояние между значениями. Примером может служить состояние больного — тяжелое, среднее, легкое. Нельзя сказать, что расстояние от легкого состояния больного до среднего больше, меньше или равно расстоянию от среднего состояния до тяжелого. Все качественные признаки можно в свою очередь разбить на два класса [3]:
1. Упорядоченные переменные (ординальные переменные — от англ. order — порядок).
2. Неупорядоченные переменные (категориальные).
Для любых двух значений упорядоченной переменной можно сказать, что одно из них предшествует другому. Тот факт, что значение 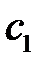 предшествует значению
предшествует значению 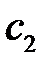 , обозначается следующим образом:
, обозначается следующим образом: 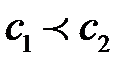 . Примером упорядоченной переменной может служить состояние больного. Действительно, все состояния можно упорядочить по тяжести заболевания:
. Примером упорядоченной переменной может служить состояние больного. Действительно, все состояния можно упорядочить по тяжести заболевания:
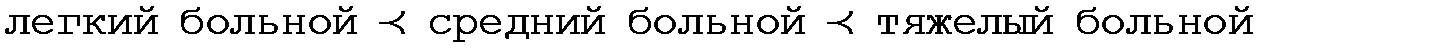
Переменные называются неупорядоченными, если никакие два её значения нельзя связать естественным в контексте задачи отношением порядка. Примером неупорядоченного признака может служить ответ на вопрос "Ваш любимый цвет?". Неупорядоченные переменные обозначают один из классов, являются именами категорий. В нашем примере — это названия цветов.
При использовании пороговых или сигмоидальных функций активации при кодировании бинарных признаков "ложь" кодируется как "-1" или "0", а "истина" – как "1".
Никакие два состояния неупорядоченной качественной переменной не связаны отношением порядка, поэтому их нельзя кодировать разными величинами одного входного сигнала нейронной сети (при кодировании значений неупорядоченной переменной числами будет введено расстояние между значениями). Для кодирования неупорядоченной качественной переменной рекомендуется [22] использовать вектор, содержащий столько компонентов, сколько значений может принимать этот качественная переменная. Пусть 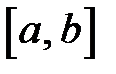 — интервал изменения входных данных. Как правило, этот интервал равен
— интервал изменения входных данных. Как правило, этот интервал равен 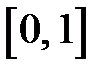 или
или 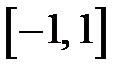 . Тогда первое значение неупорядоченной переменной кодируется вектором
. Тогда первое значение неупорядоченной переменной кодируется вектором 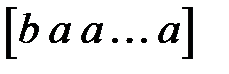 , второе значение — вектором
, второе значение — вектором 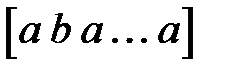 , третье — вектором
, третье — вектором 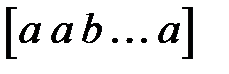 и так далее.
и так далее.
Упорядоченные качественные переменные имеют отношение порядка между значениями. Однако кодирование их разными значениями одного входного сигнала неразумно из-за того, что расстояние между значениями переменной не определено, а такое кодирование эти расстояния задает явным образом. Поэтому, упорядоченную качественную переменную рекомендуется кодировать в виде векторов, имеющих стольких компонентов, сколько значений у переменной [22]. Но, в отличие от неупорядоченных переменных необходимо накапливать число максимальных компонентов. Например, если значения качественной переменной упорядочены следующим образом: 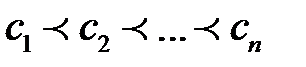 , то значению
, то значению 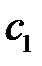 соответствует вектор
соответствует вектор 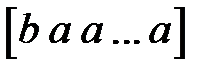 , значению
, значению 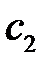 соответствует вектор
соответствует вектор 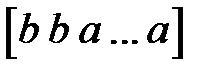 , значению
, значению 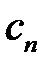 соответствует вектор
соответствует вектор 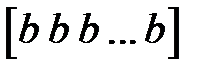
В [3] показано, что предпочтительно использовать функции активации нейронов, изменяющиеся в диапазоне от 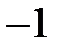 до
до 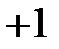 , например, гиперболический тангенс. Соответственно, бинарные значения будут кодироваться как и . Это объясняется тем, что при использовании градиентных методов обучения сетей нулевые входные значения не дают никакого вклада в градиент ошибки (см. (2.29) и (4.13)).
, например, гиперболический тангенс. Соответственно, бинарные значения будут кодироваться как и . Это объясняется тем, что при использовании градиентных методов обучения сетей нулевые входные значения не дают никакого вклада в градиент ошибки (см. (2.29) и (4.13)).
Числовые данные, казалось бы, не надо кодировать. Но в ряде случаев целесообразно кодировать и числовые данные [22]. При кодировании числовых данных необходимо учитывать содержательное значение данных, расположение значений в интервале значений, точность измерения данных. Продемонстрируем это на примерах. Например, кодирование позволяет учесть содержательное значение данных. Если входными данными сети является угол между двумя направлениями, например, направление ветра, то ни в коем случае не следует подавать на вход сети значение угла (не важно, в градусах или радианах). Такая подача приведет к необходимости "уяснения" сетью того факта, что 0 градусов и 360 градусов одно и тоже. Разумнее выглядит подача в качестве входных данных синуса и косинуса этого угла. Число входных сигналов сети увеличивается, но зато близкие значения входа кодируются близкими входными сигналами. Зачастую целесообразно применить квантование данных. Так в метеорологии используется всего восемь направлений ветра. Значит, при подаче входного сигнала сети необходимо подавать не угол, а всего лишь информацию о том, в какой из восьми секторов этот угол попадает. Но тогда имеет смысл рассматривать направление ветра не как числовой параметр, а как неупорядоченный качественный признак с восемью состояниями. Последний пример иллюстрирует особенности кодирования целых чисел [4]. Например, переменную, описывающую количество детей целесообразно представить как качественный признак (диапазон возможного изменения количества детей должен быть заранее известен). Кодирование позволяет учесть расположение значений признака в интервале значений. Для этого следует рассмотреть вопрос о равнозначности изменения значения признака на некоторую величину в разных частях интервала значений признака. Как правило, это связано с косвенными измерениями (вместо одной величины измеряется другая). Например, сила притяжения двух небесных тел при условии постоянства массы однозначно характеризуется расстоянием между ними. Пусть рассматриваются расстояния от 1 до 100 метров. Легко понять, что при изменении расстояния с 1 до 2 метров, сила притяжения изменится в четыре раза, а при изменении с 99 до 100 метров – в 1.02 раза. Следовательно, вместо подачи расстояния  следует подавать обратный квадрат расстояния
следует подавать обратный квадрат расстояния 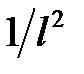 .
.
Даты и время можно представить как число некоторых единиц времени (дней, часов, минут и т. п., прошедших с некоторой начальной даты).
Кодирование изображений, звуков, текстов представляет самостоятельную задачу и в данном курсе не рассматриваются.
Дата добавления: 2015-12-08; просмотров: 12339;