Обработка аномалий, противоречий и дубликатов
Дубликаты — это данные с одинаковыми, а точнее, с близкими значениями. Противоречивые данные содержат одинаковые исходные (входные) данные, но различные значения выходных данных. Аномальные значения (выбросы) — данные, сильно отличающиеся от окружающих данных или несовместимые с ними. Дубликаты кроме увеличения объема выборки могут привести к ухудшению обучения сети, так как снижают энтропию входных данных. Противоречия нарушают общие закономерности в данных и затрудняют обучение сети.
Дубликаты — одинаковые данные. Они могут дублировать информацию об одном и том же событии, а могут содержать идентичную информацию о двух различных, но похожих событиях. В первом случае дубликаты должны быть удалены, а во втором требуется более тонкая обработка.
Особенно сложным является вопрос выявления аномалий (выбросов). Резко отличающиеся значения могут нести полезную информацию. Некоторые методы анализа данных основаны на обнаружении аномальных значений. Например, аномально большая сумма, снимаемая со счета, может рассматриваться как признак мошенничества с кредитной картой.
Для обнаружения выбросов, дубликатов и противоречий данных удобно использовать представление данных в многомерном пространстве признаков. Рассмотрим такое представление на примере обучающей выборки для задачи классификации. Обучающая выборка представляет собой множество примеров 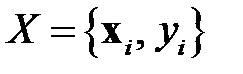 ,
, 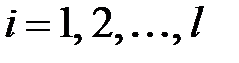 где
где 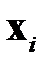 — вектор признаков объекта
— вектор признаков объекта 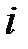 ;
; 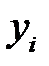 — метка (обозначение) класса, к которому принадлежит
— метка (обозначение) класса, к которому принадлежит 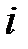 ‑й объект. На множестве векторов признаков объектов задана метрика, такая, что выполняется гипотеза компактности. В качестве метрики можно рассматривать, например, евклидово расстояние
‑й объект. На множестве векторов признаков объектов задана метрика, такая, что выполняется гипотеза компактности. В качестве метрики можно рассматривать, например, евклидово расстояние
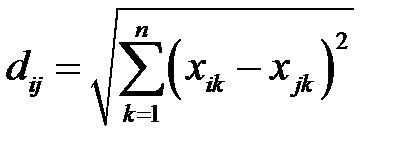 ,
,
где 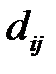 — расстояние между векторами
— расстояние между векторами 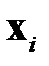 и
и 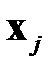 , соответственно, между объектами
, соответственно, между объектами 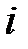 и
и  ;
;  — размерность пространства (число компонентов векторов);
— размерность пространства (число компонентов векторов); 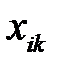 и
и 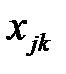 — компоненты векторов.
— компоненты векторов.
Гипотеза компактности — в задачах классификации предположение о том, что схожие объекты гораздо чаще лежат в одном классе, чем в разных классах.
Пример 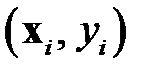 является выбросом, если расстояние от
является выбросом, если расстояние от 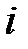 ‑го объекта до ближайшего к нему объекта из "своего" класса значительно превышает максимальное расстояние между остальными объектами данного класса. Два объекта, принадлежащих одному классу, можно считать близкими (дубликатами), если расстояние между ними мало. Противоречивые примеры близки по векторам входных данных, но принадлежат разным классам.
‑го объекта до ближайшего к нему объекта из "своего" класса значительно превышает максимальное расстояние между остальными объектами данного класса. Два объекта, принадлежащих одному классу, можно считать близкими (дубликатами), если расстояние между ними мало. Противоречивые примеры близки по векторам входных данных, но принадлежат разным классам.
В теории распознавания образов разработаны методы цензурирования выборки [8-10] — исключения выбросов, близких примеров и противоречий. Методы цензурирования можно применять и при обучении нейронных сетей. Например, в алгоритме СТОЛП (STOLP) [8] объект считается выбросом, если степень риска 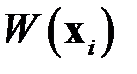 неправильно классифицировать объект превышает заданную величину. В простейшем виде степень риска рассчитывается по формуле
неправильно классифицировать объект превышает заданную величину. В простейшем виде степень риска рассчитывается по формуле 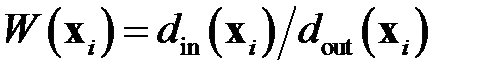 , где
, где 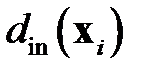 — расстояние от объекта
— расстояние от объекта 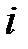 до ближайшего к нему объекта из "своего" класса,
до ближайшего к нему объекта из "своего" класса, 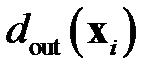 — расстояние от объекта
— расстояние от объекта 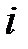 до ближайшего к нему объекта "чужого" класса.
до ближайшего к нему объекта "чужого" класса.
Аномальные значения в обучающей выборке могут быть заменены на некоторые значения, полученные теми же методами, что и при восстановлении пропущенных данных (фактически считаем, что аномальные значения пропущены). Ещё раз напомним, что удаление или замена аномальных значений могут исказить результаты анализа.
Дата добавления: 2015-12-08; просмотров: 1635;