Масштабирование (шкалирование) данных
Входные переменные должны масштабироваться (шкалироваться), то есть приводиться к единому диапазону изменения. Необходимость масштабирования объясняется несколькими причинами. После кодирования информации входами и выходами нейронной сети могут быть разнородные величины, изменяющиеся в различных диапазонах. Все входные переменные желательно привести к единому диапазону и нормировать (максимальное абсолютное значение входных переменных не должно превышать единицу). В противном случае ошибки, обусловленные переменными, изменяющимися в широком диапазоне, будут сильнее влиять на обучение сети, чем ошибки переменных, изменяющихся в узком диапазоне. Обеспечив изменение каждой входной переменной в пределах одного диапазона, мы обеспечим равное влияние каждой переменной на изменение весов в процессе обучения. При использовании сигмоидальных функций активации большие входные сигналы могут привести к насыщению выхода нейрона, что практически не позволит обучать данный нейрон. В процессе обучения за счет уменьшения весов зачастую удается исключить насыщение нейронов, но описанное выше различное влияние входных переменных, от этого только усиливается. Поэтому входные переменные, как правило, масштабируют (шкалируют), так чтобы переменные изменялись в диапазоне изменения функции активации нейронов: [0, 1] [-1, 1]. В [4] предлагается для нейронов с сигмоидальными функциями активации масштабировать входные данные к диапазону 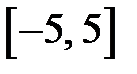 . Из рис. 2.3 видно, что этот диапазон соответствует диапазону, в котором функция активации не входит в насыщение. На практике можно строго не выдерживать единый диапазон входных данных, но масштабирование входных данных упрощает работу с сетью. Каждая входная переменная масштабируется независимо от других переменных.
. Из рис. 2.3 видно, что этот диапазон соответствует диапазону, в котором функция активации не входит в насыщение. На практике можно строго не выдерживать единый диапазон входных данных, но масштабирование входных данных упрощает работу с сетью. Каждая входная переменная масштабируется независимо от других переменных.
Выходные переменные обязательно должны быть масштабированы в диапазоне изменения функции активации нейронов выходного слоя [0, 1] или [-1, 1]. Масштабы входных и выходных переменных не связаны. Если выход сети представляет величину, значение которой необходимо анализировать, например, прогнозируемый курс валюты, обратным шкалированием выходную величину приводят к исходному диапазону значений.
При известном диапазоне изменения переменной целесообразно использовать линейное шкалирование. Например, для каждой входной переменной линейное шкалирование имеет вид
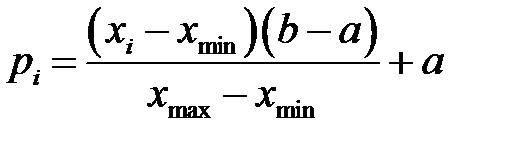 ,
,
где 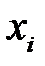 – входная переменная;
– входная переменная; 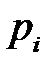 – преобразованная входная переменная, подаваемая на вход сети;
– преобразованная входная переменная, подаваемая на вход сети; 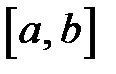 – допустимый диапазон входных переменных, например, [-1, 1];
– допустимый диапазон входных переменных, например, [-1, 1]; 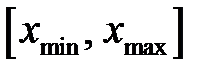 – диапазон изменения входной переменной.
– диапазон изменения входной переменной.
Аналогично масштабируются выходные переменные.
Обратное шкалирование при необходимости производится по формуле
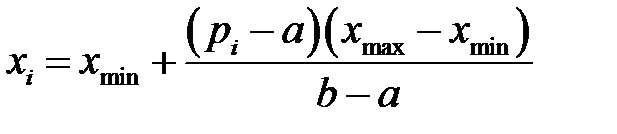 .
.
Если нейронная сеть обучена с использованием шкалированных данных, то при моделировании работы сети, то есть при подаче на вход данных, на которых сеть не обучалась, необходимо для каждой переменной использовать тот же масштаб, что и при обучении сети. То есть для входных переменных следует применять формулу . При этом переменные могут выходить за допустимый диапазон изменения переменных, например, [-1, 1]. Для входных переменных это не представляет серьезной опасности. Однако такая ситуация означает несоответствие между диапазонами изменения обучающих и реальных данных и может потребовать ограничения диапазона изменения переменных или изменения диапазона 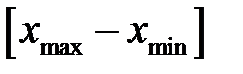 .
.
Линейное шкалирование целесообразно применять, когда значения переменной 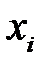 относительно равномерно заполняют определенный интервал. Но если имеется большой разброс данных, которые нельзя исключить как выбросы, то основная масса шкалированных значений
относительно равномерно заполняют определенный интервал. Но если имеется большой разброс данных, которые нельзя исключить как выбросы, то основная масса шкалированных значений 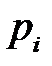 сосредоточится вблизи нуля, что затруднит обучение сети. В этом случае переменные, рассматриваемые как случайные величины, целесообразно центрировать и нормировать — приводить к нулевому среднему значению и единичному стандартному отклонению [3]
сосредоточится вблизи нуля, что затруднит обучение сети. В этом случае переменные, рассматриваемые как случайные величины, целесообразно центрировать и нормировать — приводить к нулевому среднему значению и единичному стандартному отклонению [3]
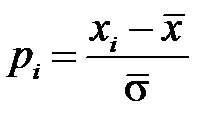 ,
,
где 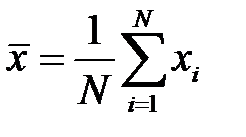 – выборочная оценка математического ожидания,
– выборочная оценка математического ожидания, 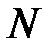 – количество переменных
– количество переменных 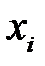 ,
, 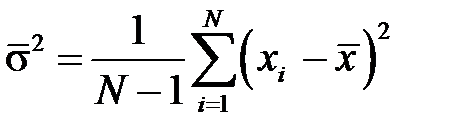 – выборочная оценка дисперсии.
– выборочная оценка дисперсии.
При таком шкалировании основная масса данных будет группироваться около нулевого значения. При этом переменные могут выходить за допустимый диапазон переменных и возникают описанные выше проблемы.
Линейное шкалирование не способно нормировать основную массу данных и одновременно ограничить диапазон возможных значений этих данных. При нормально распределенных данных выходом из этой ситуации является использование мягкого (Softmax) шкалирования [3–4]. Такое шкалирование использует функцию, аналогичную функции активации нейронов и производится по формуле
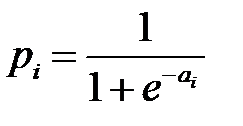
где 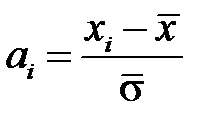 ,
, 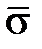 – оценка стандартного отклонения,
– оценка стандартного отклонения, 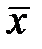 – оценка математического ожидания.
– оценка математического ожидания.
Мягкое шкалирование нормирует основную массу данных, гарантируя, что все данные попадут в допустимый диапазон переменных. Такое шкалирование сильнее сжимает переменные, далекие от среднего значения. Причем, чем больше стандартное отклонение, тем больше степень сжатия.
Для некоторых данных характерно логарифмическое распределение: большая часть значений сосредоточена вблизи среднего значения, но имеется небольшое количество больших значений. Логарифмическая функция шкалирования [4] позволяет избежать потерь больших значений
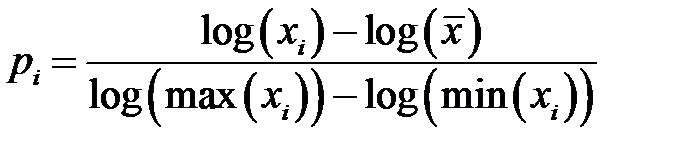 .
.
Следует отметить, что нелинейные методы шкалирования следует применять осторожно, так как они вносят в данные свойства, которых не было в исходных данных, например, неравномерно распределенные данные становятся равномерно распределенными, редко встречающиеся значения становятся равноправными с часто встречающимися значениями.
Дата добавления: 2015-12-08; просмотров: 8026;