Ресэмплинг и сэмплинг
Для обучения нейронной сети и проверки качества обучения часто требуется несколько выборок данных. Например, при прогнозировании стоило бы повторить процесс обучения несколько раз, каждый раз используя новые обучающие и тестовые наблюдения из генеральной совокупности. После этого можно усреднить общий результат для всех выборок и получить более реальные показатели. Но получить несколько выборок трудно, а иногда и невозможно. Например, для диагностики заболевания отбираются данных в определенном месте и в определенное время. Построить другие выборки невозможно, потому что это будут уже данные из другого места или же взятые в другое время. Поэтому возникает проблема: как, имея лишь одну единственную выборку, искусственно сформировать несколько "псевдовыборок", необходимых для обучения сети. Для формирования "псевдовыборок" используют методы ресэмплинга (resampling — повторная выборка) [34, 35] (в русской литературе используются разные термины: "ресамплинг", "ресэмплинг", "ресемплинг", "методы генерации повторных выборок"). Ресэмплинг объединяет несколько близких по сути подходов: рандомизация, или перестановочный тест (permutation), метод "складного ножа" (jackknife), бутстреп (bootstrap).
Перестановочный тест применяется, когда необходимо сравнить работу нейронной сети на двух выборках: обучающей и тестовой. Сеть обучается на обучающей выборке, а обобщающие возможности сети проверяются на тестовой выборке (подробнее этот подход будет рассмотрен в разделе, посвященном обучению сетей). При недостатке примеров можно использовать перестановочный тест: выборку разделяют на обучающую и тестовую. Сеть многократно обучается на обучающей выборке и тестируется на тесовой выборке. При каждом обучении происходит случайный обмен примерами между обучающей и тестовой выборками. Показатели качества работы сети усредняются по всем результатам обучениям. Часто применяется перекрестная проверка (Cross-validation) без случайного обмена данными [33]. При оценке модели имеющиеся в наличии данные разбиваются на 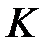 частей. Затем на
частей. Затем на 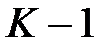 частях данных производится обучение модели, а оставшаяся часть данных используется для тестирования. Процедура повторяется
частях данных производится обучение модели, а оставшаяся часть данных используется для тестирования. Процедура повторяется 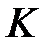 раз. При этом для тестирования используются разные части. В итоге каждая из
раз. При этом для тестирования используются разные части. В итоге каждая из 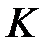 частей данных используется для тестирования.
частей данных используется для тестирования.
Метод "складного ножа" [36, 37] состоит в том, чтобы из одной выборки сделать много, исключая по одному примеру и возвращая ранее исключенные.
Бутстреп [35, 36] был предложен Б. Эфроном (B. Efron) как обобщение метода "складного ножа", чтобы не уменьшать число элементов по сравнению с исходной совокупностью. По одной из версий [35] слово "bootstrap" означает кожаную полоску в виде петли, прикрепляемую к заднику ботинка для облегчения его натягивания на ногу. Благодаря этому термину появилась английская поговорка: "Lift oneself by the bootstrap", которую можно перевести как "Пробить себе дорогу благодаря собственным усилиям". В бутстреп берется исходная выборка из 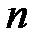 элементов, из которой за
элементов, из которой за 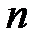 шагов формируется новая выборка, содержащая
шагов формируется новая выборка, содержащая 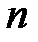 элементов. На каждом шаге с равной вероятностью из элементов исходной выборки выбирается очередной элемент новой выборки (выбранный элемент не удаляется из исходной выборки и может быть выбран на других шагах). В результате
элементов. На каждом шаге с равной вероятностью из элементов исходной выборки выбирается очередной элемент новой выборки (выбранный элемент не удаляется из исходной выборки и может быть выбран на других шагах). В результате 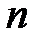 шагов формируется выборка, содержащая
шагов формируется выборка, содержащая 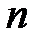 элементов, но отобранных в случайном порядке. При этом некоторые элементы исходной выборки могут оказаться многократно повторенными в новой выборке, а другие — не появиться ни разу. Таким образом, полученные с помощью бутстрэпа выборки, скорее всего, будут иметь различное распределение данных, что позволит обеспечить независимое обучение некоторого количества сетей на единственном наборе или получить более достоверные оценки качества работы сети.
элементов, но отобранных в случайном порядке. При этом некоторые элементы исходной выборки могут оказаться многократно повторенными в новой выборке, а другие — не появиться ни разу. Таким образом, полученные с помощью бутстрэпа выборки, скорее всего, будут иметь различное распределение данных, что позволит обеспечить независимое обучение некоторого количества сетей на единственном наборе или получить более достоверные оценки качества работы сети.
Известен параметрический бутстреп [35], который позволяет генерировать значения новых выборок на основе эмпирического распределения величин исходной выборки. Параметрический бутстреп, как уже указывалось, может быть применен для заполнения пропусков обучающей выборке.
Мы рассматривали ситуации, когда не хватает данных для обучения и тестирования сети. Но в аналитике [6] возможны ситуации, когда в хранилище данных накапливаются такие объемы информации, что их использование для анализа затруднено. В этой ситуации решается задача сэмплинга. Сэмплинг (sampling — выборка) — это процесс отбора из исходной совокупности данных выборки, представляющей интерес для анализа. При реализации сэмплинга используются специальные методы отбора, которые должны обеспечить репрезентативность выборки с точки зрения решаемой аналитической задачи. Различают равномерный случайный, стратификационный и другие виды сэмплинга [6].
При равномерном случайном сэмплинге (Uniform Random Sampling) все элементы исходной выборки разделяются на группы, в каждой из которых содержится одинаковое количество элементов. Из каждой группы случайным образом выбирается один элемент и помещается в результирующую выборку. Количество групп, на которые следует разбить исходную совокупность, зависит от размера исходной выборки и размера результирующей выборки. Размер результирующей выборки зависит от особенностей решаемой задачи. Возможен вариант случайного выбора элементов из всей исходной выборки без разбиения на группы. Равномерный случайный сэмплинг отличается простотой, но при неоднородной исходной совокупности результирующая выборка может оказаться не репрезентативной. Например, могут быть нарушены вероятности появления разных элементов.
В стратифицированном сэмплинге исходная выборка разбивается на несколько непересекающихся страт (слоев — от англ. Strata — слой). В качестве признака деления на страты используются значения одного или нескольких полей элементов выборки. Из каждой страты элементы извлекаются случайным образом. Размер выборки, извлекаемой из каждой страты, может выбираться двумя способами:
– пропорционально доли элементов страты в исходной выборке (из большей страты выборка больше);
– размер выборки пропорционален стандартному отклонению распределения некоторой переменной (наибольшие выборки берутся в стратах с большей вариабельностью).
Кластерный сэмплинг отличается тем, что предварительно по степени близости элементов (по некоторому расстоянию между элементами) строятся кластеры элементов, а затем так же, как и в стратифицированном сэмплинге, производится случайный выбор из кластеров.
Рассмотрим теперь, как случайным образом выбираются элементы из выборки и генерируются значения величин по эмпирическим законам распределения. Выбор с равной вероятностью одного из 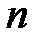 элементов выборки — это моделирование полной группы
элементов выборки — это моделирование полной группы 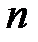 несовместных событий, происходящих с равной вероятностью
несовместных событий, происходящих с равной вероятностью 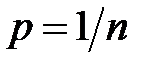 . Рассмотрим сначала моделирование одного случайного события
. Рассмотрим сначала моделирование одного случайного события 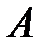 , наступающего с заданной вероятностью
, наступающего с заданной вероятностью 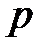 . Используем случайные числа
. Используем случайные числа 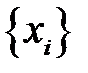 , равномерно распределенные в интервале
, равномерно распределенные в интервале 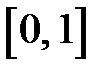 . Датчики (генераторы) таких случайных чисел хорошо известны и имеются в языках программирования. Определим событие
. Датчики (генераторы) таких случайных чисел хорошо известны и имеются в языках программирования. Определим событие 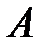 как событие, состоящее в том, что выбранное значение случайной величины
как событие, состоящее в том, что выбранное значение случайной величины 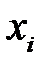 удовлетворяет неравенству
удовлетворяет неравенству
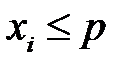
Вероятность этого события равна
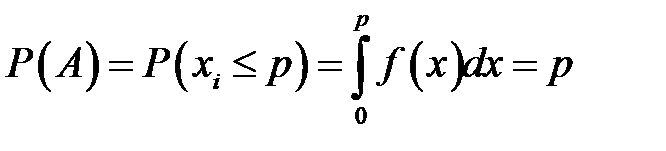 ,
,
где 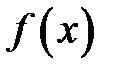 – плотность распределения равномерно распределенных в интервале
– плотность распределения равномерно распределенных в интервале 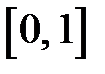 случайных чисел
случайных чисел
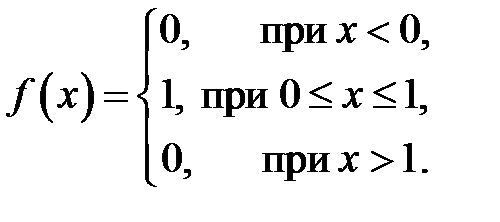
Таким образом, для моделирования случайного события, происходящего с вероятностью 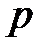 , необходимо сформировать случайное число
, необходимо сформировать случайное число 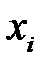 , равномерно распределенное в интервале
, равномерно распределенное в интервале 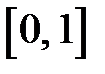 . Если условие выполнено, то считается, что событие произошло. Если условие не выполнено, то считаем, что событие не произошло.
. Если условие выполнено, то считается, что событие произошло. Если условие не выполнено, то считаем, что событие не произошло.
Рассмотрим моделирование полной группы несовместных событий 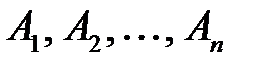 , вероятности появления которых равны
, вероятности появления которых равны 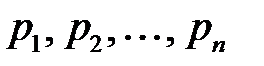 и
и 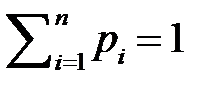 . Используем равномерно распределенные на интервале
. Используем равномерно распределенные на интервале 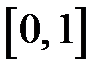 случайные числа
случайные числа 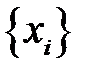 . Разобьем интервал
. Разобьем интервал 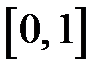 на
на 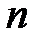 интервалов, длины которых равны
интервалов, длины которых равны 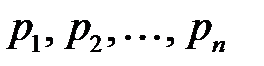 . Координаты точек деления будут равны
. Координаты точек деления будут равны 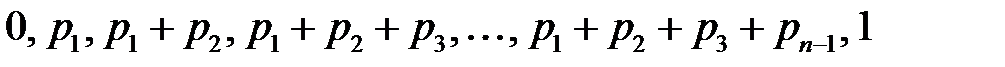 . Для моделирования события генерируется случайное число
. Для моделирования события генерируется случайное число 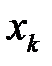 . Если число
. Если число 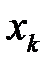 попало в
попало в 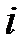 ‑й интервал, то считается, что произошло событие
‑й интервал, то считается, что произошло событие 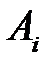 . Действительно, вероятность попадания РСЧ
. Действительно, вероятность попадания РСЧ 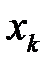 в
в 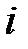 ‑й интервал равна
‑й интервал равна
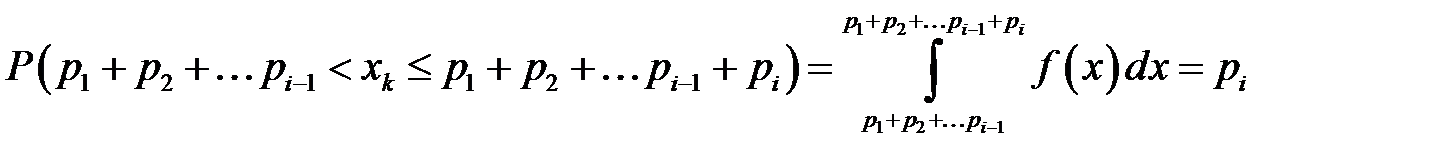 ,
,
где 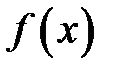 – плотность распределения равномерно распределенных в интервале
– плотность распределения равномерно распределенных в интервале 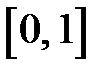 случайных чисел.
случайных чисел.
Выбор с равной вероятностью одного из элементов выборки представляет собой моделирование полной группы 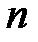 несовместных событий, происходящих с равной вероятностью
несовместных событий, происходящих с равной вероятностью 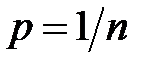 .
.
Дискретную случайную величину 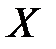 можно представить как полную группу несовместных событий: событие
можно представить как полную группу несовместных событий: событие 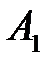 :
: 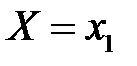 с вероятностью
с вероятностью 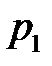 ; событие
; событие 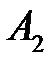 :
: 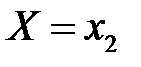 с вероятностью
с вероятностью 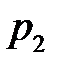 ;
;  ; событие
; событие 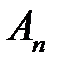 :
: 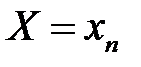 с вероятностью
с вероятностью 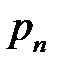 . Тогда моделирование дискретной случайной величины производится как моделирование полной группы случайных событий.
. Тогда моделирование дискретной случайной величины производится как моделирование полной группы случайных событий.
Для построения эмпирического закона распределения непрерывной случайной величины диапазон изменения величины разбивается на ряд интервалов, и подсчитывается относительная частота попадания реализаций случайной величины в каждый из интервалов. Зависимость частот от интервалов определяет эмпирическое распределение вероятностей случайной величины, графическое представление которой называется гистограммой. Для генерирования случайных величин, распределенных по эмпирическому закону можно не идентифицировать закон распределения. Генерирование сведется к генерированию дискретной случайной величины.
Дата добавления: 2015-12-08; просмотров: 2179;