Способность нейронной сети к обобщению
Основная задача построения нейронной сети — это выбор оптимального уровня сложности, то есть выбор оптимального числа слоев и числа нейронов в каждом слое. В настоящее время отсутствуют общепризнанные теоретические основы построения нейронных сетей. Многочисленные частные результаты можно найти, например, в [2, 28, 32–33]. При построении нейронной сети необходимо учитывать два противоречивых фактора. Сеть с малым числом нейронов может оказаться неспособной к обучению. С другой стороны, с увеличением числа нейронов уменьшается обобщающая способность сети.
Рассмотрим способность нейронной сети к обобщению [32–33]. Предполагается, что имеется некоторое исходное множество примеров, представляющих собой данные о некоторых объектах, явлениях и т. п., и ответы (целевые значения) — результаты, которые должны быть на выходе сети. Например, результаты анализов и состояние пациента (болен или здоров), соответствующее этим анализам. Из этого множества выбирается обучающее множество. Способность к обобщению означает, что сеть, обученная на обучающем множестве, выдает правильные результаты при подаче на вход сети данных, относящихся к исходному множеству, но на которых сеть не обучалась. Например, сеть обучают диагностировать определенные заболевания на множестве примеров, представляющих результаты медицинских анализов с известным состоянием пациента. После обучения сеть должна правильно диагностировать это заболевание по анализам, на которых она не обучалась.
Пусть имеется множество 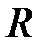 примеров, на котором действует некоторое правило. На множестве
примеров, на котором действует некоторое правило. На множестве 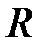 известны целевые значения. Выделим обучающее множество (Learning/Training Set)
известны целевые значения. Выделим обучающее множество (Learning/Training Set) 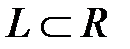 , на котором обучается сеть, контрольное (проверочное) множество (Validation Set)
, на котором обучается сеть, контрольное (проверочное) множество (Validation Set) 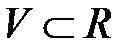 ,
, 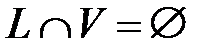 на котором в процессе обучения проверяется степень обученности сети, и тестовое множество (Test Set)
на котором в процессе обучения проверяется степень обученности сети, и тестовое множество (Test Set) 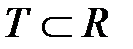 ,
, 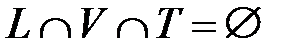 , которое не участвует в обучении и на котором после обучения проверяется качество обучения. Способность сети распознавать данные из множества
, которое не участвует в обучении и на котором после обучения проверяется качество обучения. Способность сети распознавать данные из множества 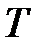 характеризует способность сети к обобщению данных.
характеризует способность сети к обобщению данных.
Используя статистическую теорию машинного обучения [40] под ошибкой сети будем понимать вероятность ошибки нейронной сети для определенного вектора  весов. Истинная цель обучения состоит в минимизации ошибки обобщения
весов. Истинная цель обучения состоит в минимизации ошибки обобщения 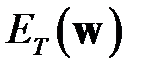 , возникающей при распознавании множества
, возникающей при распознавании множества 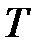 тестовых данных. Со статистической точки зрения погрешность обобщения зависит от погрешности обучения
тестовых данных. Со статистической точки зрения погрешность обобщения зависит от погрешности обучения 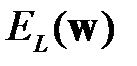 на множестве примеров
на множестве примеров 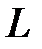 , и некоторой функции
, и некоторой функции 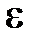 (доверительного интервала [32-33]), зависящей от
(доверительного интервала [32-33]), зависящей от 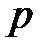 — количества обучающих выборок, погрешности обучения и
— количества обучающих выборок, погрешности обучения и 
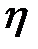 — параметра, называемого мерой Ва́пника-Червоне́нкиса[3]
— параметра, называемого мерой Ва́пника-Червоне́нкиса[3]
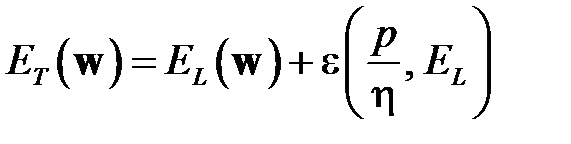 .
.
Мера Вапника-Червоне́нкиса (часто обозначается VCdim) отражает уровень сложности сети, прежде всего, количество весов сети. Значение доверительного интервала 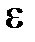 уменьшается по мере роста отношения
уменьшается по мере роста отношения 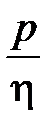 . Чтобы построить сеть с хорошей способностью к обобщению необходимо определить меру Вапника-Червоненкиса. Способ точного определения VCdim отсутствует. Известно лишь, что значение VCdim зависит от количества весов сети. Существует оценка для VCdim [32]
. Чтобы построить сеть с хорошей способностью к обобщению необходимо определить меру Вапника-Червоненкиса. Способ точного определения VCdim отсутствует. Известно лишь, что значение VCdim зависит от количества весов сети. Существует оценка для VCdim [32]
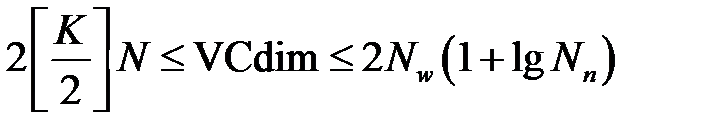 ,
,
где 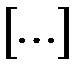 — целая часть числа,
— целая часть числа, 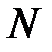 — размерность входного вектора,
— размерность входного вектора, 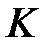 — количество нейронов скрытых слоев,
— количество нейронов скрытых слоев, 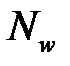 — общее количество весов сети,
— общее количество весов сети, 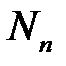 — общее количество нейронов сети.
— общее количество нейронов сети.
Обычно в качестве приближенного значения VCdim используется общее количество весов сети [32]. Таким образом, на погрешность обобщения оказывает влияние отношение количества обучающих примеров к количеству весов сети. Экспериментально установлено [32], что хорошие показатели обобщения достигаются, когда количество обучающих примеров в несколько раз превышает количество весов сети. Известно [33], что для фиксированного числа 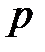 обучающих примеров ошибка обучения
обучающих примеров ошибка обучения 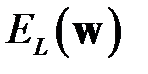 монотонно уменьшается при увеличении VCdim, а доверительный интервал
монотонно уменьшается при увеличении VCdim, а доверительный интервал 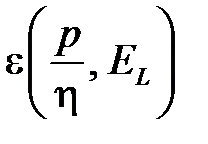 монотонно увеличивается. Следовательно, ошибка обобщение имеет минимум. До точки минимума отношение
монотонно увеличивается. Следовательно, ошибка обобщение имеет минимум. До точки минимума отношение 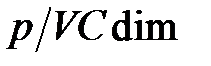 велико. Это значит, что нейронов слишком мало. Сеть плохо обучается. Погрешность обобщения большая за счет погрешности обучения. После прохождения точки минимума отношение
велико. Это значит, что нейронов слишком мало. Сеть плохо обучается. Погрешность обобщения большая за счет погрешности обучения. После прохождения точки минимума отношение 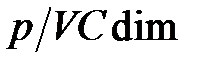 становится малым (слишком много весов для данного количества обучающих примеров). Ошибка обобщения растет за счет роста доверительного интервала. Возникает явление переобучения, или переподгонки (Overtraining, Overfitting). Параметры сети адаптируются к значениям обучающих выборок с их случайными отклонениями и ошибками. Сеть хорошо распознает только те примеры, на которых обучалась, и плохо распознает примеры из тестового множества. Выход состоит в уменьшении числа нейронов и связей (следовательно, и числа весов). Можно увеличивать объем обучающей выборки, но это не всегда возможно.
становится малым (слишком много весов для данного количества обучающих примеров). Ошибка обобщения растет за счет роста доверительного интервала. Возникает явление переобучения, или переподгонки (Overtraining, Overfitting). Параметры сети адаптируются к значениям обучающих выборок с их случайными отклонениями и ошибками. Сеть хорошо распознает только те примеры, на которых обучалась, и плохо распознает примеры из тестового множества. Выход состоит в уменьшении числа нейронов и связей (следовательно, и числа весов). Можно увеличивать объем обучающей выборки, но это не всегда возможно.
Дата добавления: 2015-12-08; просмотров: 1359;