Оптимизация структуры сети
Основной задачей проектирования нейронной сети является определение числа скрытых слоев и числа нейронов в скрытых слоях, так как число нейронов во входном и выходном слоях определяется известным числом входов и выходов сети.
Теоретические оценки показывают только качественные зависимости. Из теории Колмогорова‑Арнольда‑Хехт‑Нильсена (см. раздел 1.2) следует [32], что для аппроксимации непрерывной функции достаточно одного скрытого слоя с 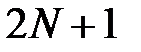 нейроном, где
нейроном, где 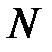 — размерность входного вектора. Для аппроксимации дискретной функции необходимо два скрытых слоя. На практике чаще всего используются сети, имеющие 1–2 скрытых слоя и число нейронов в каждом слое от
— размерность входного вектора. Для аппроксимации дискретной функции необходимо два скрытых слоя. На практике чаще всего используются сети, имеющие 1–2 скрытых слоя и число нейронов в каждом слое от 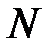 до
до 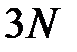 , где
, где 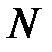 – размерность входного вектора (мы не рассматриваем сети глубокой архитектуры, содержащие большое число слоев).
– размерность входного вектора (мы не рассматриваем сети глубокой архитектуры, содержащие большое число слоев).
Существует ряд эвристических правил определения числа нейронов скрытых слоев сети. Одним из таких правил является правило геометрической пирамиды [41]. Оно утверждает, что для многих практических сетей количество нейронов имеет форму пирамиды, при этом число нейронов уменьшается от входа к выходу в геометрической прогрессии. По этому правилу число нейронов единственного скрытого слоя в трехслойной сети вычисляется по формуле 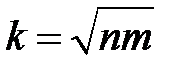 , где
, где 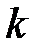 — число нейронов в скрытом слое,
— число нейронов в скрытом слое, 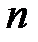 — число нейронов во входном слое,
— число нейронов во входном слое, 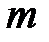 — число нейронов в выходном слое. Для четырехслойного персептрона число нейронов скрытых слоев вычисляется по формулам
— число нейронов в выходном слое. Для четырехслойного персептрона число нейронов скрытых слоев вычисляется по формулам
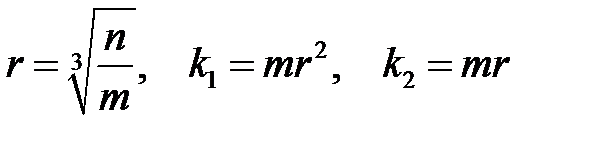 ,
,
где 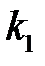 — число нейронов в первом скрытом слое,
— число нейронов в первом скрытом слое, 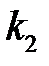 — число нейронов во втором скрытом слое.
— число нейронов во втором скрытом слое.
Для приблизительной оценки числа нейронов в скрытом слое трехслойной сети можно воспользоваться формулой для оценки минимального числа синаптических весов 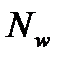 в трехслойной сети с сигмоидальными функциями [42]:
в трехслойной сети с сигмоидальными функциями [42]:
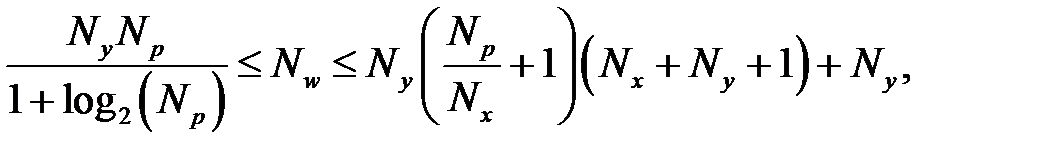
где 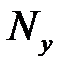 — размерность выходного сигнала,
— размерность выходного сигнала, 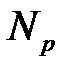 — число элементов обучающей выборки,
— число элементов обучающей выборки, 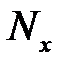 — размерность входного сигнала. Из формулы можно рассчитать нижнюю границу необходимого числа нейронов скрытого слоя. При пяти элементном входе нижняя граница необходимого числа нейронов скрытого слоя приблизительно равна пяти.
— размерность входного сигнала. Из формулы можно рассчитать нижнюю границу необходимого числа нейронов скрытого слоя. При пяти элементном входе нижняя граница необходимого числа нейронов скрытого слоя приблизительно равна пяти.
Приведенные оценки приближенный характер и требуют экспериментальной проверки.
Подбор оптимальной архитектуры сети производится экспериментально. При этом возможны два подхода [32–33]:
1. Наращивание сети (Network Growing) — постепенное наращивание сети (конструктивные методы).
2. Упрощение структуры сети (Network Pruning) — прореживание сети (редукция, контрастирование, деструктивные методы).
Для оптимизации структуры нейронных сетей применяются также генетические алгоритмы [43]. Особенности применения генетических алгоритмов для конструирования нейронных сетей можно найти в [44–47].
Наращивание сети (конструктивные методы) заключается в первоначальном включении небольшого количества скрытых нейронов. По мере обучения сети число нейронов увеличивается. Конструктивные методы более трудоемки, чем редукция и редко применяются.
Рассмотрим упрощение структуры сети. Существует два подхода к решению данной проблемы: уменьшение количества весов сети (Weight Pruning) и уменьшения количества нейронов (Unit Pruning) [48]. Второй подход применяется довольно редко. Рассмотрим подходы к удалению весов.
Простейшим способом редукции является удаление весов, значения которых существенно меньше средних значений. Удаление производится после обучения сети. После удаления производится повторное обучение. Если погрешность сети не возрастает, то удаление весов обоснованно.
Неплохой результат дают методы, основанные на регуляризации сложности сети [33]. Эти методы имеют много общего с теорией регуляризации А. Н. Тихонова [49]. В процедуре снижения весов (Weight Decay) в функционал ошибки работы сети вводится штрафное слагаемое
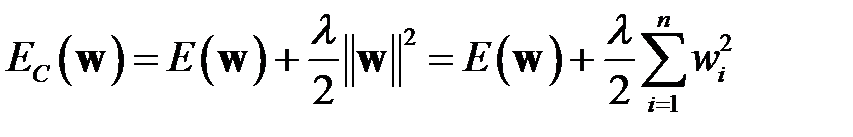 ,
,
где 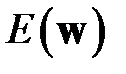 — один из функционалов ошибки, рассмотренных в разделе 3.5, например, ;
— один из функционалов ошибки, рассмотренных в разделе 3.5, например, ;  — вектор-столбец всех весов сети (чтобы построить вектор
— вектор-столбец всех весов сети (чтобы построить вектор  необходимо последовательно по слоям пронумеровать все веса сети);
необходимо последовательно по слоям пронумеровать все веса сети); 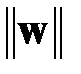 — евклидова норма вектора весов;
— евклидова норма вектора весов; 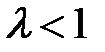 — параметр регуляризации;
— параметр регуляризации; 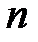 — общее число весов сети.
— общее число весов сети.
При использовании градиентных методов обучения сети (см. главу 4) коррекция веса производится по формуле
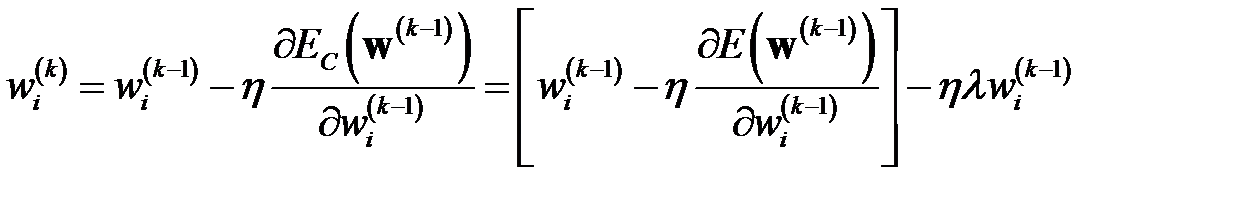 ,
,
то есть введение штрафного слагаемого дополнительно уменьшает вес на величину 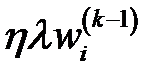 . Уменьшаются значения всех весов. Когда вес становится меньше некоторого значения, то он удаляется. Подбор уровня, на котором происходит удаление веса, производится экспериментально.
. Уменьшаются значения всех весов. Когда вес становится меньше некоторого значения, то он удаляется. Подбор уровня, на котором происходит удаление веса, производится экспериментально.
В удалении (регуляризации) весов по Вигенду (Weigend A.) [33] функционал ошибки работы сети имеет вид
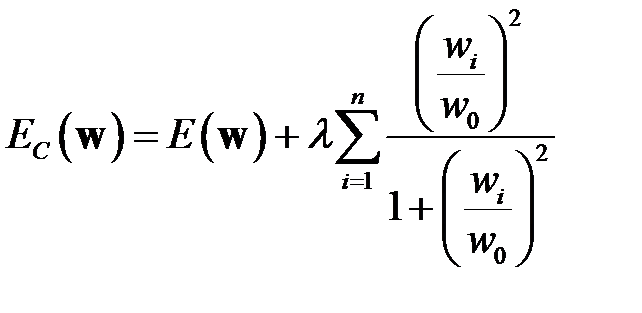 ,
,
где 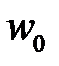 — параметр (коэффициент масштаба).
— параметр (коэффициент масштаба).
Функционал сильнее уменьшает малые веса, чем большие.
Однако в некоторых случаях малые значения весов могут оказывать существенное влияние на поведение нейрона. Более точный способ состоит в учете чувствительности функционала ошибки к изменениям весов и удалении тех весов, к которым функционал ошибки наименее чувствителен.
Обозначим вектор-столбец всех весов сети  . Изменение вектора весов обозначим
. Изменение вектора весов обозначим  , функционал ошибки работы сети, например, обозначим
, функционал ошибки работы сети, например, обозначим 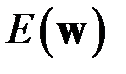 . Разложим
. Разложим 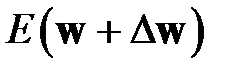 в ряд Тейлора [32–33]
в ряд Тейлора [32–33]
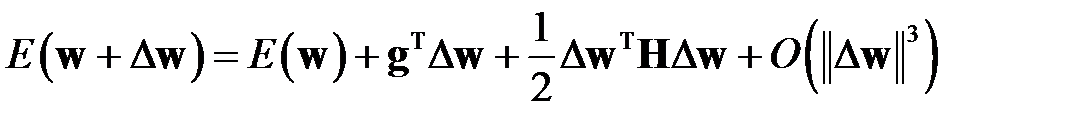 ,
,
где 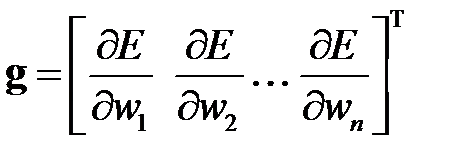 — вектор градиента функционала
— вектор градиента функционала 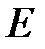 по
по  , градиент характеризует чувствительность
, градиент характеризует чувствительность 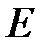 к изменениям вектора
к изменениям вектора  ;
;
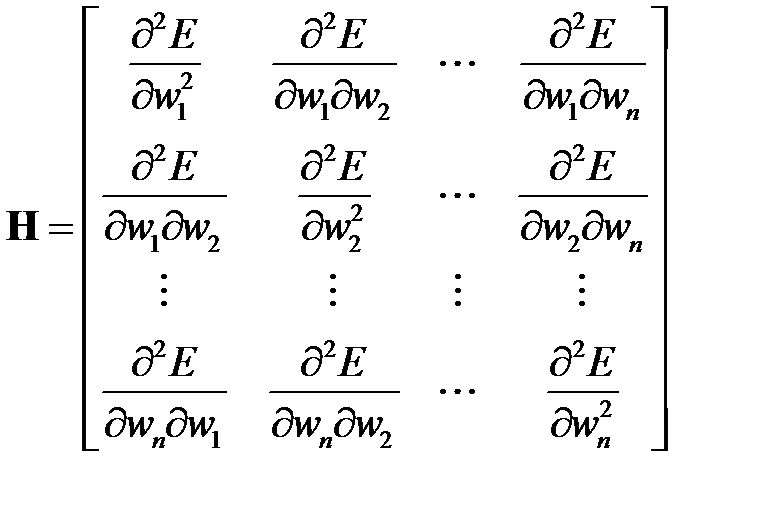
— Гессиан (Hessian), или матрица Гессе.
Выражение — это локальная аппроксимация функционала ошибки в окрестности  .
. 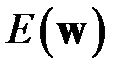 — это значение функционала до удаления весов,
— это значение функционала до удаления весов, 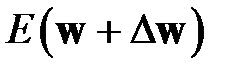 — после удаления весов. Необходимо найти такие веса, удаление которых приведет к минимальному увеличению функционала ошибки. Веса следует удалять только после завершения процесса обучения, так как замечено, что в процессе обучения низкая чувствительность сети к изменению конкретного веса может быть связана с текущим значением веса. Проведение редукции после завершения обучения не позволяет использовать градиент в качестве показателя чувствительности, так как минимуму функционала соответствует нулевой градиент (практически – малый градиент). Поэтому в качестве показателя чувствительности используются вторые производные функционала — элементы Гессиана. Так как веса удаляются после обучения сети, то компоненты вектора градиента функционала будут иметь малое значение (теоретически равны нулю). Тогда изменение функционала ошибки сети после удаления весов, как следует из имеет вид
— после удаления весов. Необходимо найти такие веса, удаление которых приведет к минимальному увеличению функционала ошибки. Веса следует удалять только после завершения процесса обучения, так как замечено, что в процессе обучения низкая чувствительность сети к изменению конкретного веса может быть связана с текущим значением веса. Проведение редукции после завершения обучения не позволяет использовать градиент в качестве показателя чувствительности, так как минимуму функционала соответствует нулевой градиент (практически – малый градиент). Поэтому в качестве показателя чувствительности используются вторые производные функционала — элементы Гессиана. Так как веса удаляются после обучения сети, то компоненты вектора градиента функционала будут иметь малое значение (теоретически равны нулю). Тогда изменение функционала ошибки сети после удаления весов, как следует из имеет вид
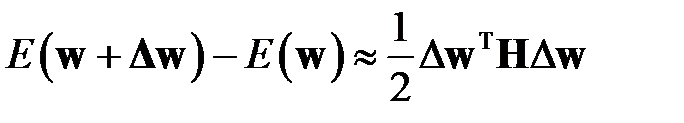 .
.
Удаление веса 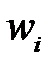 увеличивает функционал ошибки на величину
увеличивает функционал ошибки на величину 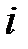 ‑го компонента вектора
‑го компонента вектора 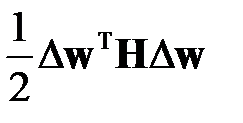 .
.
Однако вычисление Гессиана весьма трудоемко. В методе OBD (Optimal Brain Damage — "оптимальное повреждение мозга"), предложенном ЛеКуном (Y. LeCun) и соавторами [32–33], учитываются только диагональные элементы Гессиана (Гессиан является положительно определенной матрицей и с диагональным преобладанием). В качестве меры значимости (Saliency) веса 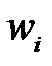 используется показатель
используется показатель
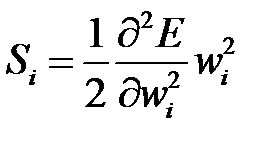 ,
,
который рассчитывается для каждого веса после обучения сети. Вычисление второй производной в довольно сложный процесс, основанный на алгоритме обратного распространения ошибки (см. раздел 4). Удаляются те веса, которым соответствуют наименьшие значения 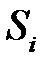 . Удалить можно несколько весов. Сеть с редуцированной структурой снова обучается, повторяется процесс редукции и т. д., пока не будут исключены все веса, оказывающие малое влияние на функционал ошибки.
. Удалить можно несколько весов. Сеть с редуцированной структурой снова обучается, повторяется процесс редукции и т. д., пока не будут исключены все веса, оказывающие малое влияние на функционал ошибки.
Развитием метода ODB является метод OBS (Optimal Brain Surgeon — "оптимальная хирургия мозга"), предложенный Б. Хассиби (Hassibi B.) и соавторами [32–33]. В этом методе учитываются все элементы Гессиана. В методе также как и в ODB используется изменение функционала ошибки сети до и после удаления весов , но обнуляется только один из весов. Пусть удаляется вес 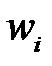 . Тогда обнуление этого веса эквивалентно выполнению условия
. Тогда обнуление этого веса эквивалентно выполнению условия 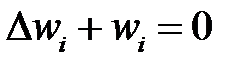 , или
, или
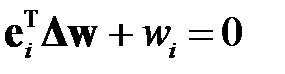 ,
,
где 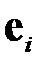 — вектор, все компоненты которого равны нулю за исключением
— вектор, все компоненты которого равны нулю за исключением 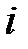 ‑го, который равен единице.
‑го, который равен единице.
Тогда задача исключения веса формулируется как задача условной минимизации: необходимо минимизировать изменение функционала ошибки, то есть квадратичную форму 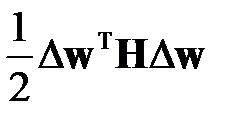 по отношению к вектору
по отношению к вектору  , учитывая условие . Для решения этой задачи применим метод множителей Лагранжа (см. книги по математическому анализу, например, [50] или специальную литературу [51]). Для этого построим Лагранжиан
, учитывая условие . Для решения этой задачи применим метод множителей Лагранжа (см. книги по математическому анализу, например, [50] или специальную литературу [51]). Для этого построим Лагранжиан
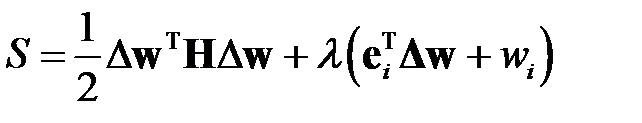 ,
,
где 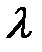 — множитель Лагранжа.
— множитель Лагранжа.
Для определения экстремума возьмем производную от по  и приравняем ее нулю. Но надо учесть, что это производная по направлению [52]. Производной от функционала
и приравняем ее нулю. Но надо учесть, что это производная по направлению [52]. Производной от функционала  в точке
в точке  по направлению
по направлению 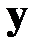 называется выражение
называется выражение
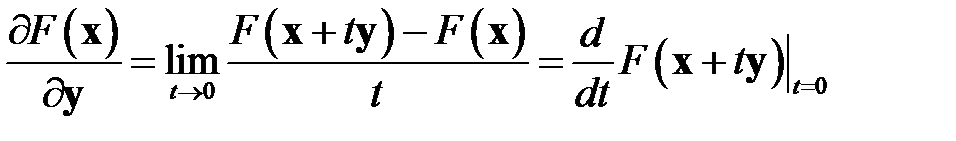 .
.
Применяя , получаем
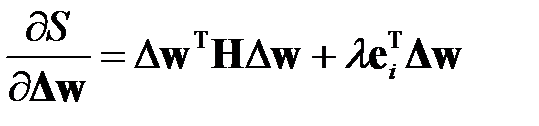 .
.
Приравнивая производную нулю, учитывая, что 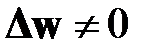 , получаем
, получаем
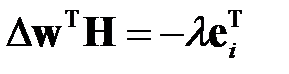 .
.
Транспонируя левую и правую части последнего равенства с учетом симметрии матрицы 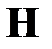 , получаем
, получаем
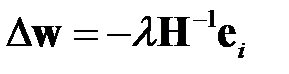 .
.
Для определения множителя Лагранжа 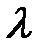 умножим обе части на
умножим обе части на 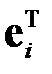 и учтем, что из получается
и учтем, что из получается 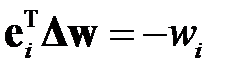 . Тогда
. Тогда
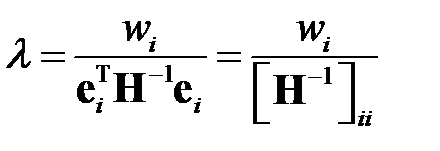 ,
,
где 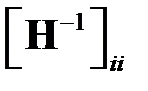 — элемент с индексами
— элемент с индексами 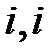 матрицы
матрицы 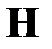 .
.
Окончательно оптимальный вектор коррекции весов имеет вид
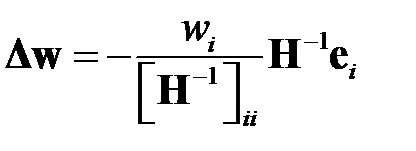 .
.
Обратите внимание, что согласно корректируются все веса. Так как мы учли равенство , после коррекции 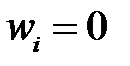 .
.
Вычислим изменение функционала ошибки после удаления веса 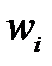
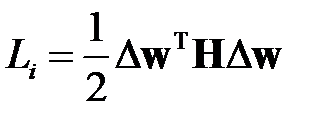 .
.
Подставляя в и учитывая симметрию матрицы 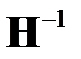 , получаем
, получаем
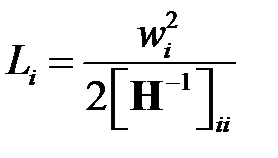 .
.
Выражение является мерой значимости при выборе удаляемого веса: необходимо удалять вес 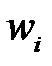 с минимальным значением
с минимальным значением 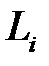 . Из видно, что изменение ошибки зависит не только от величины веса, но и от свойств Гессиана. При малом значении
. Из видно, что изменение ошибки зависит не только от величины веса, но и от свойств Гессиана. При малом значении 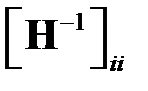 даже небольшие веса могут существенно влиять на ошибку. Поэтому метод OBS точнее метода ODB. Из сравнения и видно, что меры значимости обоих методов совпадают, если матрица
даже небольшие веса могут существенно влиять на ошибку. Поэтому метод OBS точнее метода ODB. Из сравнения и видно, что меры значимости обоих методов совпадают, если матрица 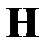 является диагональной.
является диагональной.
Метод OBS реализуется по следующему алгоритму.
1. Обучение нейронной сети до допустимого значения 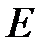 целевой функции.
целевой функции.
2. Вычисление матрицы 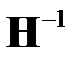 , обратной Гессиану.
, обратной Гессиану.
3. Вычисление меры значимости для всех весов. Выбор веса, для которого мера значимости минимальна. Если для выбранного веса изменение целевой функции намного меньше 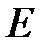 , то вес
, то вес 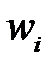 удаляется и происходит переход к следующему пункту, в противном случае редукция сети завершается.
удаляется и происходит переход к следующему пункту, в противном случае редукция сети завершается.
4. Коррекция значений весов по формуле . Переход на пункт 2.
Таким образом, метод OBS отличается от OBD не только определением меры значимости. В методе OBS веса удаляются по одному с последующей коррекцией всех весов без повторного обучения сети. Но вычисление обратной матрицы 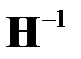 является сложной задачей. Для вычисления этой матрицы авторами метода разработана приближенная процедура. На русском языке с этой процедурой можно познакомиться в [33].
является сложной задачей. Для вычисления этой матрицы авторами метода разработана приближенная процедура. На русском языке с этой процедурой можно познакомиться в [33].
Дата добавления: 2015-12-08; просмотров: 3274;