Оценивание и сравнение нейросетевых моделей
При решении задач с использованием нейросетевых моделей приходится рассматривать несколько моделей или вариантов построения одной модели. Поэтому важно оценивать модели и выбирать лучшие. Рассмотрим оценки погрешностей моделей, решающих задачи классификации и аппроксимации зависимостей. Эти задачи являются типичными для нейросетевых моделей.
Эффективность модели, предназначенной для решения задачи классификации, обычно оценивается с помощью коэффициента ошибки (error rate) [6]. Если классификатор правильно определяет класс наблюдения, то имеет место успех, в противном случае — ошибка. Коэффициент ошибки — это количество ошибок, допущенных на всем множестве, отнесенное к общему числу наблюдений. Он показывает общую эффективность классификатора.
Ошибки классификатора должны определяться на данных, на которых классификатор не обучался (см. разделы 3.3 и 3.7), то есть определяется ошибка обобщения.
Ошибки классификатора удобно представлять в графической форме в виде матрицы несоответствий (Confusion Matrix) — матрицы, в которой для каждого класса наблюдений приводятся результаты отнесения наблюдений к тому или иному классу. Английское название (confusion — путаница) возникло потому, что матрица позволяет видеть, путает ли классификатор классы. Столбцы матрицы соответствуют предсказанным классам, а строки — фактическим классам. Матрицы несоответствий строятся в таких популярных инструментах, как пакет Нейронные сети STATISTICA и Neural Network Toolbox (NNT) системы MATLAB. На рис. 3.2 показан пример матриц несоответствий пакета NNT [55]. Матрицы несоответствия построены для трех множеств данных: обучающего множества (Training Set), контрольного множества (Validation Set), тестового множества (Test Set) и суммарного множества, состоящего из этих трех множеств, (см. раздел 3.7) в случае разделения этих множеств на два класса (матрицы могут быть построены для разбиения на произвольное число классов).
Из матрицы несоответствий для обучающего множества (Training Confusion Matrix) видно, что 314 объектов первого класса, что составляет 64,2% от всех 489 объектов, отнесены к первому классу. Четыре объекта первого класса ошибочно классифицированы как объекты второго класса. Правильно классифицировано 98,7% объектов первого класса, а 1,3% классифицированы неправильно. Последняя строка матрицы показывает, что из всех объектов, классифицированных как объекты первого класса, 98,4% составляют объекты первого класса, а 1,6% объекты, не относящиеся к первому классу. В целом правильно классифицировано 98,2% объектов (314+116=480 объектов из 489 объектов). Неправильно классифицировано 1,8% объектов.
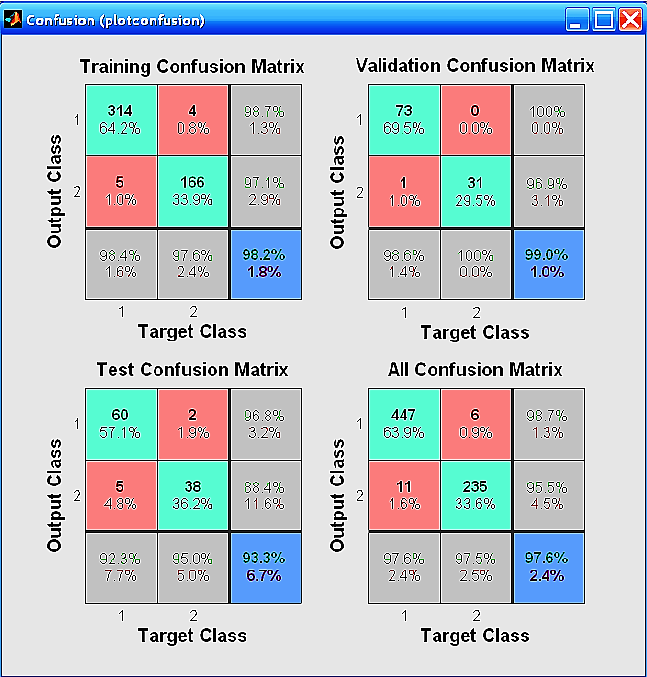
Рис. 3.2. Пример матриц несоответствий пакета NNT
Ошибки, допускаемые моделью при ее практическом применении, могут приводить к ложным выводам, что влечет за собой материальные и, следовательно, финансовые потери от неправильно принятых решений. Такие потери называются издержками ошибки классификации (Classification Cost Error, Misclassification Cost). Например, при разработке модели кредитного скоринга (оценки кредитоспособности лица) ставится цель разделить всех клиентов банка на добросовестных и недобросовестных. Возникает вопрос: "Что лучше — принять добросовестного клиента за недобросовестного или наоборот?" Ответ очевиден: в первом случае мы теряем только проценты по кредиту, который не был выдан, а во втором — всю сумму, выданную недобросовестному заемщику. То есть издержки ошибок второго вида больше. При построении модели необходимо минимизировать вероятность появления ошибок, которые вызывают наибольшие издержки классификации. Такая методика называется классификацией с учетом издержек (Cost-Sensitive Classification) [6].
В бинарной классификации (когда все объекты разделяются на два класса) каждое отдельное предсказание может иметь четыре исхода:
· истинноположительный (True Positive, 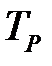 );
);
· истинноотрицательный (True Negative, 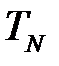 );
);
· ложноположительный (False Positive, 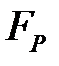 );
);
· ложноотрицательный (False Negative, 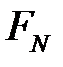 ).
).
Пусть в качестве положительного исхода выбрано значение Да, а в качестве отрицательного — Нет. Истинноположительным исход будет, когда фактический класс данного примера Да и модель на выходе выдаст Да. Истинноотрицательным исход будет, когда фактический класс наблюдения Нет и модель выдаст Нет. Ложноположительное значение имеет место, когда класс наблюдения Нет, а модель для него сформирует выход Да. При ложноотрицательном выходе целевая переменная принимает значение Да, а на выходе модель выдаст Нет.Результаты представлены на рис. 3.3 в виде матрицы классификации.
| Предсказанный класс | |||
| Да | Нет | ||
| Фактический класс | Да | 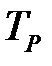
| 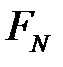
|
| нет | 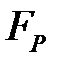
| 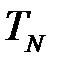
|
Рис. 3.3. Матрица классификации
Рассмотренные понятия связаны с известными в математической статистике понятиями ошибок первого и второго рода [56]. Если бинарная классификационная модель строится на основе обучающей выборки, то все входящие в нее примеры соответствуют либо положительному, либо отрицательному исходам. Тогда в процессе работы модели могут возникнуть следующие ошибки.
· Пример соответствует положительному исходу, но был распознан как отрицательный: заемщик кредитоспособен, но модель распознает его как некредитоспособного; пациент болен, но модель распознает его как здорового; радиолокационная система не смогла обнаружить цель по ее сигналу, принятому локатором (пропуск цели), и т. д. Иными словами, интересующее событие ошибочно не обнаружено. Такие ошибки называются ошибками I рода.
· Пример соответствует отрицательному исходу, но был распознан как положительный: заемщик некредитоспособен, но модель определяет его как кредитоспособного; пациент здоров, но модель определяет его как больного; радиолокационная цель отсутствует, но система определяет ее наличие (ложная тревога) и т. д. Иными словами, интересующее событие не произошло, но было обнаружено. Такие ошибки называются ошибками II рода.
Введем в рассмотрение два основных показателя, позволяющих оценить точность бинарной классификационной модели [6].
Общий показатель успеха (Overall Success Rate, OSR), или просто точность (Accuracy), — это число правильно классифицированных наблюдений, отнесенное к общему числу наблюдений
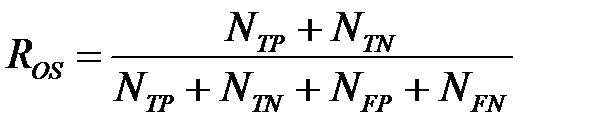 ,
,
где 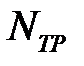 — число истинноположительных наблюдений,
— число истинноположительных наблюдений, 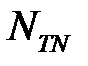 — число истинноотрицательных наблюдений,
— число истинноотрицательных наблюдений, 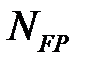 — число ложноположительных наблюдений,
— число ложноположительных наблюдений, 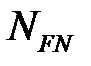 — число ложноотрицательных наблюдений.
— число ложноотрицательных наблюдений.
Иногда данную величину называют точностью классификатора. Общий показатель ошибки (Overall Error Rate, OVR) вычисляется по формуле
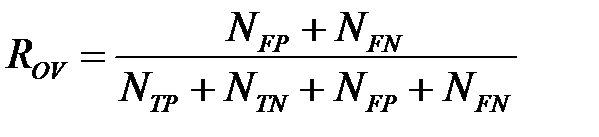 .
.
Для оценки качества любой бинарной классификационной модели используются еще два показателя — чувствительность ( 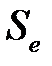 ) и специфичность (
) и специфичность ( 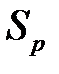 ). Чувствительность (или доля истинноположительных наблюдений) определяется как отношение числа истинноположительных наблюдений к числу фактически положительных наблюдений
). Чувствительность (или доля истинноположительных наблюдений) определяется как отношение числа истинноположительных наблюдений к числу фактически положительных наблюдений
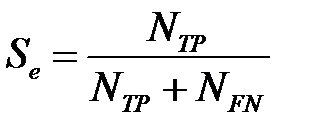 .
.
Специфичность определяется как отношение числа истинноотрицательных наблюдений к числу фактически отрицательных наблюдений
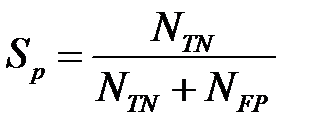 .
.
Если, например, диагностируется наличие болезни у пациентов, то чувствительность — это доля больных пациентов, для которых диагностическое правило верно диагностирует наличие болезни. А специфичность — доля здоровых пациентов, для которых диагностическое правило верно диагностирует отсутствие болезни.
Также используется понятие доля ложноположительных наблюдений.
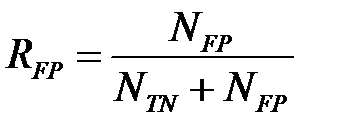 .
.
Легко проверить, что 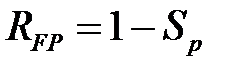 .
.
Обратим внимание: если отсутствуют ложноотрицательные исходы, чувствительность равна 1; если отсутствуют ложноположительные исходы, специфичность равна 1. Модель, которая способна идеально точно классифицировать как положительные, так и отрицательные примеры, будет иметь 100-процентную чувствительность и специфичность. Чтобы минимизировать ошибки I рода, нужно использовать модель с высокой чувствительностью. Чтобы минимизировать ошибки II рода, нужно использовать модель с высокой специфичностью.
При бинарной классификации два типа ошибок — ложноположительные и ложноотрицательные — будут иметь различные издержки, а два типа корректной классификации — истинноположительный и истинноотрицательный — будут давать различную прибыль.
Минимизировать издержки ошибок бинарной классификации классификации можно с помощью выбора точки отсечения (Cut-Off Point) — порогового значения, разделяющего классы [6]. Положительный исход в нейросетевом классификаторе обычно кодируется единицей, а отрицательный — нулем или -1 (см. рис. 2.3 — графики логистических функций активации). Но выход нейрона с сигмоидальной функцией активации никогда не будет точного значения 1 или 0 (-1). Использование точки отсечения позволяет интерпретировать результаты работы нейросетевого классификатора: если выходной сигнал нейрона превышает порог отсечения, то это означает положительный исход, в противном случае — отрицательный. Аналогично поступают и при использовании нейрон с функцией активации softmax.
При уменьшении порога отсечения увеличивается вероятность ошибочного распознавания положительных наблюдений (ложноположительных исходов), а при увеличении возрастает вероятность неправильного распознавания отрицательных наблюдений (ложноотрицательных исходов). Цель заключается в том, чтобы подобрать такое значение точки отсечения, которое дает наибольшую точность распознавания заданного класса, а какого именно — определяется постановкой задачи.
Для выбора точки отсечения в бинарной классификации применяется ROC‑анализ [6], основанный на построении характеристической кривой обнаружения — ROC‑кривой. Этот термин (Receiver Operating Characteristic — операционная характеристика приёмника) пришел из теории обработки сигналов. В радиолокации задача заключается в обнаружении некоторой цели (морской, воздушной и т. д.). При этом положительный исход — цель обнаружена, отрицательный исход — цель не обнаружена. Во время второй мировой войны термин возник в связи с задачей повышения точности распознавания целей. В настоящее время ROC-анализ широко применяется при построении классификаторов различных областях.
Чтобы построить ROC-кривую, нужно изменять порог отсечения в интервале от 0 (или от -1) до 1 с заданным шагом. В результате при каждом значении порога будет меняться количество правильно и неправильно распознанных примеров, а соответственно, чувствительность и специфичность модели. Для каждого порога рассчитывается чувствительность и специфичность, и строится график, по вертикальной оси которого откладывается чувствительность, а по горизонтальной — доля ложных положительных классификаций 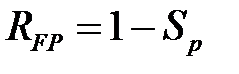 .
.
Типичный вид ROC-кривой представлен на рис. 3.4 [6]. Увеличение значения по горизонтальной оси соответствует уменьшению специфичности модели. Так как на один положительный исход может приходиться несколько отрицательных, и наоборот, то реальная ROC‑кривая будет не гладкой, а изрезанной.
Каждая точка ROC-кривой соответствует определенному значению порога отсечения. При этом оптимальным будет значение, соответствующее точке ROC-кривой с координатами, максимально близкими к (0; 100), для которой и чувствительность, и специфичность равны 100 %, то есть как положительные, так и отрицательные примеры распознаны правильно. ROC‑кривая, соответствующая идеальному классификатору показана на рис. 3.4 пунктиром. Диагональная линия на рис. 3.4 соответствует "бесполезному" классификатору, когда результат получается случайным угадыванием.
Площадь под ROC‑кривой (AUC — Area Under ROC Curve) говорит о прогностической силе модели, причем AUC=1 соответствует идеальному классификатору. Для реальных классификаторов площадь под ROC-кривой больше 0,7–0,8, соответствует достаточно высокой точности классификации.
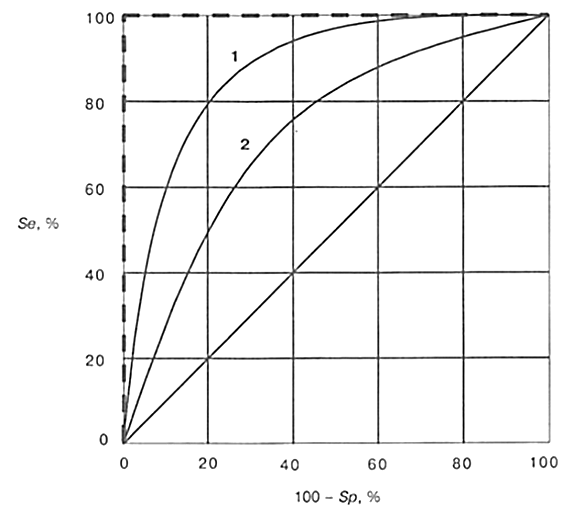
Рис. 3.4. ROC‑кривые
С помощью выбора порога отсечения добиваются оптимального соотношения между чувствительностью и специфичностью модели. Для этого применяются различные стратегии. Например, часто порог выбирают таким образом, чтобы сумма чувствительности и специфичности была максимальна (чтобы обеспечивалось максимальное количество как положительных, так и отрицательных правильно распознанных примеров). Иногда порог выбирают так, чтобы соблюдался баланс между чувствительностью и специфичностью, то есть 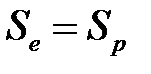 .
.
При решении задач аппроксимации зависимостей качество работы сети определяется разностями между известными значениями функции и аппроксимированными сетью. Пример представления функции аппроксимации в Neural Network Toolbox MATLAB показан на рис. 3.5.
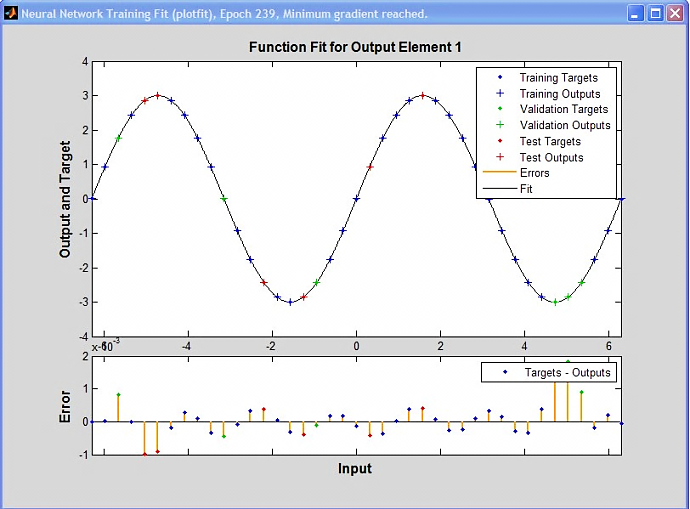
Рис. 3.5. Функция аппроксимации
Для детального анализа качества аппроксимации можно использовать регрессионный анализ выходов сети и соответствующих целей (Regression). Для этого строится линейная регрессия результатов обучения сети на трех рассмотренных подмножествах и на всем обучающем множестве. Для каждого результата рассчитывается коэффициент корреляции 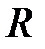 , строится график и выводится уравнение регрессии в виде
, строится график и выводится уравнение регрессии в виде 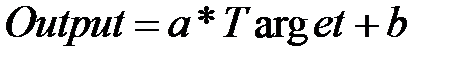 (рис. 3.6).
(рис. 3.6).
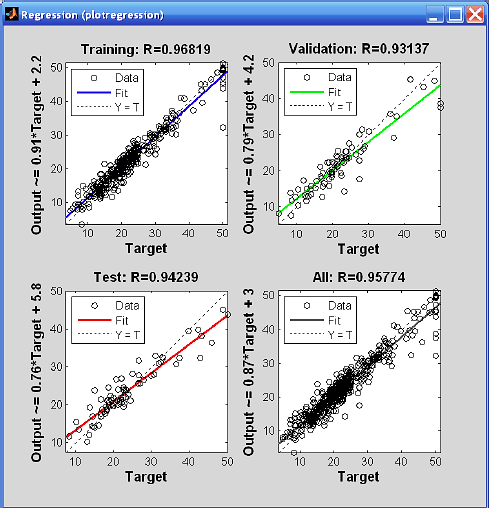
Рис. 3.6. Регрессия
При полном совпадении выходов сети с целевыми значениями 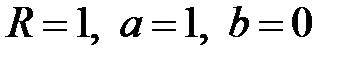 .
.
Дата добавления: 2015-12-08; просмотров: 3428;