Алгоритм LZ77
Даний алгоритм (алгоритм LZ774))був одним з перших, що використовують словник [55]. Як словник використовуються N останніх уже закодованих елементів послідовності. У процесі стиску словник-підпослідовність переміщається ("сковзає") по вхідній послідовності. Ланцюжок елементів на виході кодується в такий спосіб: положення співпадаючої частини оброблюваного ланцюжка елементів у словнику - зсув (щодо поточної позиції), довжина, перший елемент, що випливає за частиною, що збіглася, ланцюжка. Довжина ланцюжка збігу обмежується зверху числом n. Відповідно, завдання полягає в знаходженні найбільшого ланцюжка зі словника, що збігає з оброблюваною послідовністю. Якщо ж збігів ні, то записується нульовий зсув, одинична довжина й тільки перший елемент незакодованої послідовності - {0, 1, e}.
Описана вище схема кодування приводить до поняття ковзного вікна (англ. sliding window), що складає із двох частин:
1. підпослідовність уже закодованих елементів довжини N - словник - буфер пошуку (англ. search buffer );
2. підпослідовність довжини n з ланцюжка елементів, для якої буде зроблена спроба пошуку збігу - буфер попереднього перегляду (англ. look-ahead buffer).
У термінах ковзного вікна алгоритм стиску описується так: якщо e1, . . . , ei - уже закодована підпослідовність, те ei-N+1, . . . , ei - суть словник або буфер пошуку, а ei+1, . . . , ei+n - буфер попереднього перегляду. Аналогічно, завдання полягає в пошуку найбільшого ланцюжка елементів з буфера попереднього перегляду, починаючи з елемента ei+1, що збігає з ланцюжком з буфера пошуку - цей ланцюжок може починатися з будь-якого елемента  й закінчуватися будь-яким елементом
й закінчуватися будь-яким елементом 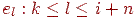 , тобто виходити за межі буфера пошуку, вторгаючись у буфер попереднього перегляду. Природно, що виходити за межі ковзного вікна не можна. Нехай у ковзному вікні знайдена максимальна по довжині ланцюжок, що збігся, елементів ei-p, . . , ei+q, тоді вона буде закодована в такий спосіб: {p+1, q+p+1, ei+p+q+2} - зсув відносно початку буфера попереднього перегляду (ei+1), довжина ланцюжка, що збіглося, елемент, що випливає за ланцюжком, що збігся, з буфера попереднього перегляду. Якщо в результаті пошуку знайдено два збіги з однаковою довжиною, то вибирається найближче до початку буфера попереднього перегляду. Після цього ковзне вікно зміщається на p + q + 2 елементів уперед, і процедура пошуку повторюється.
, тобто виходити за межі буфера пошуку, вторгаючись у буфер попереднього перегляду. Природно, що виходити за межі ковзного вікна не можна. Нехай у ковзному вікні знайдена максимальна по довжині ланцюжок, що збігся, елементів ei-p, . . , ei+q, тоді вона буде закодована в такий спосіб: {p+1, q+p+1, ei+p+q+2} - зсув відносно початку буфера попереднього перегляду (ei+1), довжина ланцюжка, що збіглося, елемент, що випливає за ланцюжком, що збігся, з буфера попереднього перегляду. Якщо в результаті пошуку знайдено два збіги з однаковою довжиною, то вибирається найближче до початку буфера попереднього перегляду. Після цього ковзне вікно зміщається на p + q + 2 елементів уперед, і процедура пошуку повторюється.
Вибір чисел N і n є окремою важливою проблемою, тому що чим більше N і n, тим більше місця потрібно для зберігання значень зсуву й довжини. Природно, що час роботи алгоритму також зростає з ростом N і n. Відзначимо, що звичайно N і n розрізняються на порядок.
Приведемо приклад стиску даним алгоритмом. Стиснемо рядок "TOBEORNOTTOBE" з параметрами N = 10 і n = 3:
| крок | ковзне вікно | макс. ланцюжок, що збігся | вихід |
| ""+"TOB" | T | 0,1,T | |
| "T"+"OBE" | O | 0,1,O | |
| "TO"+"BEO" | B | 0,1,B | |
| "TOB"+"EOR" | E | 0,1,E | |
| "TOBE"+"ORN" | O | 3,1,R | |
| "TOBEOR"+"NOT" | N | 0,1,N | |
| "TOBEORN"+"OTT" | O | 3,1,T | |
| "TOBEORNOT"+"TOBE" | TOB | 9,3,E |
Якщо виділити для зберігання зсуву 4 біти, довжини - 2 біти, а елементів - 8 біт, то довжина закодованої послідовності (без обліку позначення кінця послідовності) складе 4 × 8 + 2 × 8 + 8 × 8 = 112 біт, а вихідної - 102 біта. У цьому випадку ми не стисли послідовність, а, навпаки, збільшили надмірність подання. Це пов'язане з тим, що довжина послідовності занадто мала для такого алгоритму. Але, наприклад, малюнок кодового дерева Хаффмена на мал. 13.1, що займає 420 кілобайт дискового простору, після стиску має розмір близько 310 кілобайт.
Нижче наведений псевдокод алгоритму стиску.
// M - фіксована границя// зчитуємо символи послідовно із вхідного потоку// in - вхід - стисла послідовність// n - максимальна довжина ланцюжка// pos - положення в словнику, len - довжина ланцюжка// nelem - елемент за ланцюжком, str - знайдений ланцюжок// in - вхід, out - вихід// SlideWindow - буфер пошукуwhile( !in.EOF() ) //поки є дані{ // шукаємо максимальний збіг і його параметри SlideWindow.FindBestMatch( in, n, pos, len, nelem ); // пишемо вихід: зсув, довжина, елемент out.Write( pos ); out.Write( len ); out.Write( nelem ); // зрушимо ковзне вікно на len + 1 елементів SlideWindow.Move( in, len + 1 );}Лістинг 13.2. Алгоритм стиску методом LZ77
Декодування стислої послідовності є прямою розшифровкою записаних кодів: кожного запису зіставляється ланцюжок зі словника і явно записаного елемента, після чого виробляється зрушення словника. Очевидно, що словник відтвориться в міру роботи алгоритму декодування.
Видно, що процес декодування значно простіше з обчислювальної точки зору.
// n - максимальна довжина ланцюжка// pos - положення в словнику, len - довжина ланцюжка// nelem - елемент за ланцюжком, str - знайдений ланцюжок// in - вхід, out - вихід// Dict - словник while( !in.EOF() ) //поки є дані{ in.Read( pos ); in.Read( len ); in.Read( nelem ); if( pos == 0 ) { //новий окремий символ //видаляємо зі словника перший (далекий) один елемент Dict.Remove( 1 ); //додаємо в словник елемент Dict.Add( nelem ); out.Write( nelem ); } else { //скопіюємо відповідний рядок зі словника str = Dict.Get( pos, len ); //видалимо зі словника len + 1 елементів Dict.Remove( len + 1 ); //Додаємо в словник ланцюжок Dict.Add( str + nelem ); out.Write( str + nelem ); }}Лістинг 13.3. Алгоритм
Даний алгоритм є родоначальником цілого сімейства алгоритмів, і сам по собі в споконвічному виді практично не використовується. До його достоїнств можна віднести пристойний ступінь стиску на досить більших послідовностях, швидке розпакування, а також відсутність патенту5)на алгоритм. До недоліків відносять повільну швидкість стиску, а також меншу, чим в альтернативних алгоритмів, ступінь стиску (модифікації алгоритму борються із цим недоліком). Сполучення алгоритмів Хаффмена (Huffman) (див. розділ 13.5) і LZ77 називають методом DEFLATE6).Метод DEFLATE використовується в графічному форматі PNG, а також в універсальному форматі стиску даних ZIP.
Дата добавления: 2015-04-03; просмотров: 2458;