RLE - байтовый рівень
Припустимо, що на вхід подається напівтонове зображення, де на значення інтенсивності пикселя приділяється 1 байт. Ясно, що в порівнянні із чорно-білим растром очікування довгого ланцюжка однакових битов істотно знижується.
Будемо розбивати вхідний потік на байти (букви) і кодувати повторювані букви парою (кількість, буква).
Т.е. AABBBCDAA кодуємо (2A) (3B) (1C) (1D) (2A). Однак можуть зустрічатися довгі відрізки даних, де нічого не повторюється, а ми кодуємо кожну букву парою (цифра, буква).
Нехай у нас є фіксоване число (буква) M (від 0 до 255). Тоді одиночну букву  можна закодувати нею самою, - вихід = S, а якщо букв трохи або
можна закодувати нею самою, - вихід = S, а якщо букв трохи або 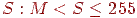 , те вихід = CS, де C > M, а C - M - кількість букв, що підряд ідуть, S. Для приклада приведемо тільки алгоритм декодування.
, те вихід = CS, де C > M, а C - M - кількість букв, що підряд ідуть, S. Для приклада приведемо тільки алгоритм декодування.
Лістинг 13.1. Алгоритм декодування RLE - байтовый рівень
Число M звичайно дорівнює 127. Частіше використовується модифікація цього алгоритму, де ознакою лічильника служить наявність одиниць в 2 старших бітах зчитувального символу. Інші 6 битов суть значення лічильника.
Така модифікація даного алгоритму використовується у форматі PCX. Однак модифікації даного алгоритму рідко використовуються самі по собі, тому що підклас послідовностей, на яких даний алгоритм ефективний, відносно вузький. Модифікації алгоритму використовуються як одна зі стадій конвеєра стиску (наприклад у форматі JPEG, див. розділ 13.4).
Дата добавления: 2015-04-03; просмотров: 1272;