Арифметичне кодування
Класичні статистичні алгоритми зіставляють елементу кодируемой послідовності якийсь код. Алгоритми арифметичного кодування кодують відразу ланцюжок елементів у число-дріб 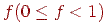 [40]. При цьому враховується розподіл імовірностей появи елементів у послідовності.
[40]. При цьому враховується розподіл імовірностей появи елементів у послідовності.
Нехай a1, . . . , an - алфавіт, всі можливі одноелементні ланцюжки; p1, . . . , pn - імовірності появи елементів (ваг) (pj = Prob(aj)). Розіб'ємо напівінтервал [0, 1) на n непересічних напівінтервалів I1, . . . , In, що відповідають елементам a1, . . . , an, причому довжина Ij пропорційна pj .
Далі будується дріб, що кодує: виробляється побудова системи вкладених напівінтервалів так, що кожний наступний напівінтервал займає в попереднє місце, що відповідає положенню елемента у вихідній розбивці напівінтервалу [0, 1).
Коротко процес виглядає так:
- зчитування чергового елемента;
- вибір відповідного напівінтервалу з розбивки поточного напівінтервалу (на першому кроці - [0, 1)).
По закінченні цього процесу можна взяти будь-яке число з напівінтервалу, що вийшов. Звичайне число вибирають так, щоб його запис у двійковому виді була самої короткою. Також часто накладають обмеження на довжину двійкового дробу, що вийшло. При перевищенні цього обмеження поточний дріб виводиться, і починається спочатку формування нової, що доповнює попередню(ие).
// elem - елемент// in - вхід, out - вихід// cleft - поточна ліва границя напівінтервалу// cright - поточна права границя напівінтервалу// interv - масив границь у вихідній розбивці cleft = 0;cright = 1;while( in.Read( elem ) ) // поки є дані{ // довжина поточного напівінтервалу d = cright - cleft; // обчислимо границі нового напівінтервалу cright = cleft + d*interv[elem].right; cleft = cleft + d*interv[elem].left;}// шукаємо дріб усередині [left, right)frac = Between( left, right );out.Write( frac );Лістинг 13.6. Алгоритм арифметичного кодування
Стиснемо наступну послідовність "TOBEORNOTTOBE".
Складемо таблицю ваг:
| елемент алфавіту | B | E | N | O | R | T |
| вага |
Побудуємо розбивку напівінтервалу [0, 1):

- На вході T, тоді права границя напівінтервалу буде 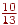 , ліва - 1, довжина -
, ліва - 1, довжина - 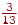 ;
;
- На вході O, тоді права границя напівінтервалу буде 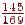 , ліва -
, ліва - 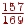 , довжина -
, довжина - 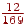 ;
;
- На вході B, тоді права границя напівінтервалу буде 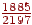 , ліва -
, ліва - 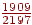 , довжина -
, довжина - 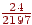 ;
;
- На вході E, тоді права границя напівінтервалу буде 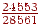 , ліва -
, ліва - 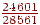 , довжина -
, довжина - 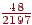 ;
;
- ...
- На вході E, тоді права границя напівінтервалу буде 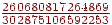 , ліва -
, ліва - 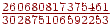 , довжина -
, довжина -  .
.
Двійковий дріб можна взяти таку: 0.1101110001010110000001000000101, тому що двійковий запис границь підсумкового напівінтервалу наступна: ліва - 0.1101110001010110000001000000100111010011000101101, права - 0.1101110001010110000001000000101101100100100100001.
Закодована послідовність має довжину 31 біт. Вихідна, якщо вважати алфавітом набір ASCII - 104 біта, якщо вважати алфавітом тільки набір "TOBERN" - 39 біт.
Декодування полягає в розшифровці дробу по відомому розподілі ймовірностей появи елементів у послідовності. Отже, потрібно зберігати або передавати інформацію про розподіл імовірностей появи елементів. Для того щоб обійти ця вимога, а також для того щоб позбутися від необхідності робити два проходи по послідовності, були запропоновані адаптивні модифікації алгоритму.
// elem - елемент, in - вхід, out - вихід// interv - масив границь у вихідній розбивці// frac - дріб, що кодує// cleft - поточна ліва границя напівінтервалу// cright - поточна права границя напівінтервалу// nelem - кількість елементів, закодована дробом i = nelem;in.Read( frac );while( i > 0 ) // поки треба декодировать{ // шукаємо елемент по дробі й розбивці напівінтервалу elem = GetElem( interv, frac ); out.Write( elem ); // обчислимо границі напівінтервалу cright = interv[elem].right; cleft = interv[elem].left; // довжина напівінтервалу d = cright - cleft; // перетворимо дріб x = (x - cleft) / d; // відзначимо обробку чергового елемента i-i--;}Лістинг 13.7. Алгоритм арифметичного декодування
Опишемо ідею адаптивної модифікації. Споконвічно передбачається, що поява всіх елементів равновероятно. У міру надходження нових елементів ваги й розбивка напівінтервалу коректуються. При декодуванні також здійснюється корекція після обробки чергового елемента.
Арифметичне кодування є майже оптимальним видом кодування, тобто дає коди, майже рівні довжинам оптимальних кодів з теореми Шеннона. Однак така ефективність досягається за рахунок більших обчислювальних витрат. Існують модифікації алгоритму, що використовують тільки операції зрушення й додавання без розподілу й множення для прискорення процесу кодування. На жаль, практично всі такі модифікації захищені патентами. Частина цих патентів уже мають термін, що закінчився, дії, інша частина - немає. Таким чином, у міру витікання строків патентів ефективні реалізації модифікацій алгоритму арифметичного кодування будуть витісняти алгоритм Хаффмена в сферах, де продуктивність не є критичною вимогою.
1) Загалом кажучи, даний формат також підтримує стиск із втратами.
2) У літературі часто зустрічається й інша назва - групове кодування.
3) англ. Run Length Encoding
4) Названий по іменах авторів Абрахама Лемпеля (Abraham Lempel) і Якоба Зива (Jacob Ziv). Опублікований в 1977 році.
5) документ, що забезпечує виключне право експлуатувати винахід протягом відомого часу (звичайно 15-20 років)
6) Так називається стиск, а разжатие називається INFLATE (англ. DEFLATE - здувати, INFLATE - надувати).
7) Алгоритм названий по ім'ю автора Терри Уэлч (Terry Welch) і назви вихідного алгоритму LZ78 (також від імен Лемпеля й Зива). Він був опублікований в 1984 році.
8) Huffman coding. Автор алгоритму - Давид Хаффмен (David A. Huffman). Опублікований в 1952 році.
Дата добавления: 2015-04-03; просмотров: 2272;