Актуальность технического обслуживания 13 страница
Таблица 14.3
Таблица косинусов для графического изображения корреляции между переменными
| Угол (в градусах) | Косинус угла |
| 1,000 | |
| 0,966 | |
| 0,867 | |
| 0,707 | |
| 0,500 | |
| 0,259 | |
| 0,000 | |
| -0,500 | |
| -0,867 | |
| -1,000 | |
| -0,867 | |
| -0,500 | |
| 0,000 | |
| 0,500 | |
| 0,867 |
гих векторов равной длины, причем все они исходят из той же точки, что и первый вектор. Углы между переменными, по договоренности, измеряются в направлении, задаваемом направлением движения часовой стрелки. Переменные, между которыми имеются большие положительные корреляции, располагаются близко друг к другу, поскольку табл. 14.3 показывает, что большие корреляции (или косинусы) соответствуют маленьким углам между векторами. Векторы высоко коррелирующих переменных имеют одно и то же направление; переменные, имеющие высокие отрицательные корреляции друг с другом, обращены в противоположные стороны, а векторы переменных, которые не коррелируют между собой, указывают на совершенно разные направления. На рис. 14.1 приводится простой пример. Корреляции между переменными VI и V2 должны быть равны 0, и это выражается двумя векторами равной длины, выходящими из одной точки, но под прямым углом друг к другу (90°), как изображено в табл. 14.3. Корреляция между VI и V3 равна 0,5, а корреляция между V2 и V3 составляет 0,867, поэтому переменная V3 располагается, как показано на рисунке.
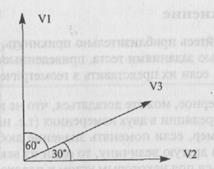
Рис. 14.1. Корреляции между тремя переменными и их геометрическое выражение.
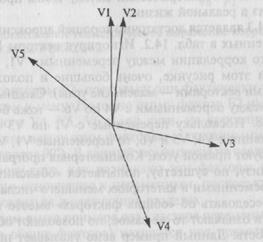
Рис. 14.2. Геометрическое выражение корреляций между пятью переменными.
Задание для самопроверки 14.1
На рис. 14.2 изображено геометрическое выражение корреляций между пятью переменными. Используя табл. 14.3, попытайтесь ответить на следующие вопросы:
(а) Какие две переменные имеют самую высокую положительную корреляцию?
(б) Какая переменная образует корреляцию, равную 0, с V3?
(в) Какая переменная имеет самую большую отрицательную корреляцию с V3?
Упражнение
Попытайтесь приблизительно прикинуть, как корреляции между шестью заданиями теста, приведенные в табл. 14.2, будут выглядеть, если их представить в геометрическом выражении.
Вы, наверное, можете догадаться, что не всегда возможно представить корреляции в двух измерениях (т.е. на плоском листе бумаги). Например, если поменять значение любой из корреляций на рис. 14.1 на другую величину, то один из векторов должен был бы располагаться под некоторым углом к плоскости страницы. Последнее не является проблемой для собственно математических процедур факторного анализа, однако оно означает, что нельзя использовать этот геометрический метод, чтобы проводить факторной анализ в реальной жизни.
Рис. 14.3 является достаточно хорошей апроксимацией данных, представленных в табл. 14.2. Игнорируя векторы F1 и F2, можно видеть, что корреляции между переменными VI, V2 и V3, показанные на этом рисунке, очень большие и положительные (т.е. между этими векторами — маленькие углы). Сходным образом корреляции между переменными с V4 по V6 — тоже большие и положительные. Поскольку переменные с VI по V3 имеют близкие к 0 корреляции с V4, V5 и V6, то переменные VI, V2 и V3 с V4, V5 и V6 образуют прямой угол. Компьютерная программа по факторному анализу, по существу, попытается «объяснить» корреляции между переменными в категориях меньшего числа факторов. Полезно побеседовать об «общих факторах» вместо просто «факторов» — они означают то же самое, но позволяют обеспечить большую точность. Данный пример ясно указывает на то, что существует два кластера корреляций, поэтому информация, полученная из табл. 14.2, может быть апроксимирована двумя общими факторами, каждый из которых проходит через группу больших корреляций. Общие факторы на рис. 14.3 изображены в виде более длинных векторов, обозначенных F1 и F2.
Должно быть ясно, что измеряя угол между каждым общим фактором и каждой переменной, можно вычислить корреляции между каждой переменной и каждым общим фактором. Переменные VI, V2 и V3 будут иметь большие корреляции с фактором Fl (V2 фактически будет иметь корреляцию, близкую к 1,0, с фактором F1, поскольку фактор FI, по сути, находится на вершине этой переменной). Переменные VI, V2 и V3 будут иметь корреляции,
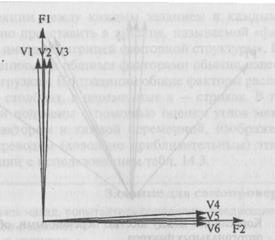
Рис. 14,3. Приблизительное геометрическое выражение корреляций, которые даны в табл. 14.2.
близкие к 0, с фактором F2, поскольку они фактически находятся под прямым углом к нему. Подобно этому фактор F2 имеет высокую корреляцию с V4, V5, V6 и, по сути, не коррелирует с VI, V2, V3 (потому что между этим фактором и указанными переменными угол составляет 90°). В данный момент вам не следует беспокоиться по поводу того, как возникают эти факторы и как они располагаются по отношению к переменным, поскольку эти вопросы будут обсуждаться в следующих разделах.
В приведенном выше примере два кластера переменных (и следовательно, два общих фактора) находятся под прямыми углами друг к другу. Методика этого варианта известна как «ортогональное решение» — термин, который вам следует взять на заметку. Однако это не значит, что оно применяется всегда. Рассмотрим корреляции, представленные в графической форме на рис. 14.4. Очевидно, что здесь имеются два отдельных кластера переменных, но точно так же ясно и то, что нет способа, с помощью которого два ортогональных (т.е. некоррелирующих) общих фактора, изображенных векторами F1 и F2, могут быть проведены через центр каждого кластера. Очевидно, что имело бы смысл создать условия для факторов, чтобы они могли коррелировать, и провести один общий фактор через середину каждого кластера переменных. Разновидности факторного анализа, в которых вычисляются корре-
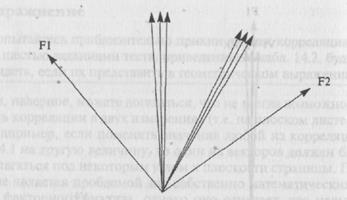
Рис. 14.4. Корреляции между шестью переменными, образующими два ортогональных фактора.
ляции между самими факторами (расположенными не под прямыми углами), известны как «облические решения». Корреляции между факторами формируют так называемую «матрицу взаимных корреляций факторов». Постарайтесь запомнить этот термин, он окажется полезным, когда вы подойдете к интерпретации распечаток, полученных в результате факторного анализа. Когда осуществляется ортогональное решение, все корреляции между различными факторами равны 0. (Корреляция, равная 0, предполагает наличие угла в 90° между каждой парой факторов, что представляет, по существу, другой способ констатировать независимость факторов.)
Таблица 14.4
Приблизительная матрица факторной структуры, полученная на основе рис. 14.3.
| Переменная | Фактор 1 | Фактор 2 |
| VI | 0,90 | 0,10 |
| V2 | 0,98 | 0,00 |
| V3 | 0,90 | -0,10 |
| V4 | 0,10 | 0,85 |
| V5 | 0,00 | 0,98 |
| V6 | -0,10 | 0,85 |
Все корреляции - между каждым заданием и каждым общим фактором можно представить в таблице, называемой «факторной матрицей» или иногда «матрицей факторной структуры». Корреляции между заданиями и общими факторами обычно известны как «факторные нагрузки». По традиции общие факторы располагаются в таблице в столбцах, а переменные в — строках. В табл. 14.4 величины были получены с помощью оценки углов между каждым общим фактором и каждой переменной, изображенных на рис. 14.3, и переводом (довольно приблизительным) этих значений в корреляции с использованием табл. 14.3.
Задание для самопроверки 14.2
Не возвращаясь назад, попытайтесь определить следующие понятия:
(а) облическое решение;
(б) факторные нагрузки;
(в) матрица факторной структуры;
(г) ортогональное решение;
(д) матрица взаимных корреляций факторов.
Факторная матрица крайне важна. Прежде всего, она показывает, какие переменные образуют каждый общий фактор. Это может быть выявлено путем выбора произвольной точки отсчета и выделения тех переменных, которые имеют нагрузки намного большие, чем эта величина (положительная и отрицательная). По традиции точка отсчета составляет 0,4 или 0,3, что соответствует углу от 60 до 75" между переменной и общим фактором. Следовательно, самый легкий способ увидеть, какие переменные «принадлежат» фактору, — это подчеркнуть те, которые имеют нагрузки выше чем 0,4 (или меньше чем —0,4). Итак, из табл. 14.4 следует вывод, что фактор F1 — это сочетание переменных VI, V2 и V3 (но не V4, V5 и V6, поскольку их факторные нагрузки меньше чем 0,4). Подобно этому фактор F2 представляет собой сочетание переменных V4, V5 и V6. Таким образом, факторная матрица может быть использована для того, чтобы дать пробное наименование общему фактору. Например, представим себе, что факторизации подвергались 100 заданий, оценивающих способности, и было установлено, что переменные, которые имеют существенные нагрузки (больше 0,4) по первому общему фактору, были связаны с правописанием, словарем, знанием пословиц и вербальным пониманием, в то время как ни одно из других заданий (математические задачи, головоломки, требующие визуализации объектов, тесты памяти и
т.д.) не обнаружили больших нагрузок по этому фактору. Поскольку все задания, имеющие высокую нагрузку, включали использование языка, можно назвать общий фактор фактором «вербальных способностей», «языковых способностей» или чем-нибудь подобным. Однако имейте в виду, что нет никакой гарантии правильности наименований, данных таким образом. Необходимо точно ва-лидизировать фактор, как описано в главе 13, чтобы убедиться, что наименование полностью ему соответствует. Однако если задания, определяющие общий фактор, образуют надежную шкалу, которая позволяет прогнозировать данные учителями оценки языковых способностей, значимо коррелируют с другими хорошо проверенными тестами вербальных способностей и практически совсем не коррелируют с другими показателями личности или способностей, можно с высокой вероятностью утверждать, что фактор был идентифицирован правильно.
Вы, должно быть, помните, что квадрат коэффициента корреляции (т.е. коэффициент корреляции, помноженный сам на себя) показывает, какая часть «вариативности» является общей для двух переменных, или, говоря проще, он показывает, насколько сильно они перекрываются. Две переменные с корреляцией 0,8 перекрываются со степенью 0,8 х 0,8 = 0,64. (Обратитесь к приложению А, если эта тема вам не знакома.) Поскольку факторные нагрузки представляют просто корреляции между общими факторами и заданиями, подразумевается, что возведенная в квадрат каждая факторная нагрузка показывает долю перекрытия между каждой переменной и каждым общим фактором. Этот простой факт формирует основу для двух других главных направлений использования факторной матрицы.
Факторная матрица может выявить долю перекрытия между каждой переменной и всеми общими факторами. Если общие факторы образуют прямые углы («ортогональное» решение), то вычислить, какая часть вариативности каждой переменной измеряется ими, не составит труда: это делается просто суммированием квадратов факторных нагрузок по всем факторам. (Когда общие факторы не образуют прямых углов, ситуация становится более сложной.) Из табл. 14.4 можно увидеть, что 0,92 + 0,102 = (0,82) вариативности VI «объясняется» двумя факторами. Эта доля называется общностью данной переменной.
Переменная с высокой общностью имеет большую степень перекрытия с одним или более общими факторами. Низкая общность подразумевает, что все корреляции между переменными и
общими факторами невелики, другими словами, ни один из общих факторов не имеет большого перекрытия с этой переменной. Это может означать, что переменная измеряет нечто концептуально отличающееся от других переменных, включенных в анализ. Например, одно задание, связанное с оценкой личности, среди ста заданий, оценивающих способности, будет иметь общность, близкую к нулю. Это может также означать, что определенное задание испытывает на себе сильное влияние ошибки измерения или степени сложности, например, задание настолько простое, что каждый испытуемый дает на него правильный ответ, или задание было настолько двусмысленно сформулировано, что никто не смог понять суть вопроса. Какова бы ни была причина, низкая общность подразумевает, что задание не совмещается с общими факторами либо потому, что оно измеряет другую черту, либо из-за большой ошибки измерения, либо потому, что существуют некоторые индивидуальные различия между людьми, обусловливающие вариативность ответов на это задание.
Наконец, факторная матрица показывает относительную значимость общих факторов. Можно вычислить, какую часть вариативности объясняет каждый общий фактор. Общий фактор, который объясняет 40% перекрытия между переменными в исходной корреляционной матрице, очевидно, является более значимым, чем другой, который объясняет только 20% вариативности. Еще раз подчеркнем, что необходимо допущение ортогональности общих факторов (т.е. их взаимного расположения под прямым углом). Первый шаг састоит в том, чтобы вычислить так называемое собственное значение (eigenvalue) для каждого фактора. Это можно сделать с помощью возведения в квадрат факторных нагрузок и их сложения по столбцу. Используя данные, представленные в табл. 14.4, можно убедиться, что собственное значение фактора 1 составляет (0,902 + 0,982 + 0,902 + ОДО2 + 0,02+ (-0,10)2 = 2,60. Если собственное значение фактора разделить на число переменных (шесть в этом примере), это число покажет, какая пропорция вариативности объясняется каждым общим фактором. Здесь фактор 1 объясняет 0,43 или 43%, информации в исходной корреляционной матрице.
Задание для самопроверки 14-3
Попытайтесь определить понятия «собственное значение фактора» и «общность». Затем вернитесь к табл. 14.4 и:
(а) вычислите общности переменных V2, V3, V4, V5, V6;
(б) вычислите собственное значение фактора F2;
(в) определите, какая доля вариативности объясняется фактором F2;
(г) определите путем сложения долю вариативности, которая объясняется факторами F1 и F2 совместно.
Прежде чем. завершить изучение факторной матрицы, целесообразно разобраться с вопросом, который может возникнуть у читателя. Представим себе, что один из факторов в анализе имеет ряд нагрузок, больших по абсолютной величине и отрицательных (например, —0,6; —0,8), а некоторые его нагрузки близки к нулю (-0,1, +0,2) и в нем нет больших положительных нагрузок. Предположим также, что задания с большими отрицательными нагрузками принадлежат к утверждениям такого типа, где согласие кодируется «1», несогласие — «О» (например: «вы нервозный человек?» и «много ли вы беспокоитесь?»). Большие отрицательные корреляции подразумевают, что фактор измеряет психологическую характеристику, противоположную нервозности и склонности к беспокойству. Она может быть гипотетически идентифицирована как «эмоциональная стабильность» или что-то близкое к ней. Хотя интерпретировать факторы таким способом абсолютно приемлемо, иногда может быть удобнее изменить все знаки всех нагрузок переменных по данному фактору на противоположные. Так, нагрузки, упоминавшиеся выше, будут изменены с —0,6; -0,8; -0,1 и +0,2 на +0,6; +0,8; +0,1 и -0,2. Подобная процедура выполняется только ради удобства, как будет показано в задании для самопроверки 14.4. Однако если вы изменяете знаки всех факторных нагрузок, вам также следует:
• изменить знак корреляции между фактором, взятым с обратным знаком, и всеми другими факторами в матрице факторных корреляций;
• изменить знак всех «факторных оценок» (обсуждаемых ниже), вычисляемых в свою очередь из данного фактора.
Задание для самопроверки 14.4
(а) Используйте табл. 14.3, чтобы графически изобразить набор корреляций между одним фактором (F1) и двумя переменными (V1 и V2), представленными в табл. 14.5.
(б) Затем измените знак корреляции между переменными и F1 и заново постройте график.
(в) Исходя из этого попытайтесь объяснить, как изменение знака всех факторных нагрузок изменяет положение фактора.
Выполнив задание для самопроверки 14.3 (г), вы заметите нечто довольно странное. Два общих фактора, будучи объединены, объясняют только 83,4% вариативности исходной корреляционной матрицы. Сходным образом, все общности оказываются меньше, чем 1,0. Что случилось с «потерянными» 17% вариативности?
Факторный анализ, по сути, представляет собой методику для компактного представления информации — для построения широких обобщений на основе детально подобранных данных. В нашем примере мы рассматривали корреляции между шестью переменными, наблюдали, как они распадаются на два отдельных кластера, и поэтому решили, что наиболее экономно анализировать материал в понятиях двух факторов, а не шести исходных переменных. Другими словами, число конструктов, необходимых для описания данных, уменьшилось с шести (число переменных) до двух (число общих факторов). Данная апроксимация полезна, но несовершенна, как и любая другая. Часть информации в исходной корреляционной матрице была принесена в жертву построению широкого обобщения. Действительно, никакая — даже минимальная — информация не будет утрачена только при условии, если переменные VI, V2 и V3 будут иметь корреляции, равные 1,0 (то же самое относится к V4, V5 и V6), и если все корреляции между этими двумя группами переменных будут точно равны нулю. Тогда (и только тогда!) мы не потеряли бы никакой информации в результате обращения к двум факторам, а не к шести переменным.
Это составляет первую часть объяснения «исчезнувшей вариативности». Она«может рассматриваться как неизбежное следствие уменьшения числа конструктов с шести до двух. Представим себе, однако, что вместо выделения только двух факторов из корреляций между шестью переменными было извлечено шесть факторов (все находятся под прямыми углами друг к другу и, следовательно, недоступны для зрительного представления).
Таблица 14,5 Корреляции между двумя переменными и одним фактором
| F1 | VI | V2 | |
| F1 | 1,000 | ||
| VI | -0,867 | 1,000 | |
| V2 | -0,867 | 0,500 | 1,000 |
Поскольку в данном случае имеется столько же факторов, сколько переменных, здесь не должно быть потери информации. Можно ожидать, что шесть факторов будут в состоянии объяснить всю информацию в исходной корреляционной матрице.
Анализ главных компонент и факторный анализ
В конечном итоге все зависит от того, каким образом осуществляется факторный анализ. Существует два главных подхода к факторному анализу. Наиболее простой подход, который называется «анализом главных компонент», допускает, что шесть факторов действительно могут полностью объяснить информацию в корреляционной матрице. Таким образом, каждая переменная будет иметь общность, точно равную 1,0, а все факторы вместе будут объяснять 100% совместной вариативности переменных.
Более формально модель главных компонент предполагает, что для каждой переменной
общая вариативность = вариативность общего фактора + + ошибка измерения
и что когда число выделенных факторов соответствует числу переменных, эти общие факторы могут объяснить всю информацию в корреляционной матрице.
Допущение, согласно которому то, что не измеряется общими факторами, должно быть только ошибкой измерения, является достаточно весомым. Каждое задание теста может иметь небольшую долю «уникальной вариативности», которая специфична для данного задания, но не может быть разделена с другими заданиями. Представим себе, что ученик дает правильный ответ на вопрос географического теста: «Как называется столица Венесуэлы?» Это может указывать на то, что либо ученик в общем имеет хороший уровень географических знаний, либо он просто случайно обладает небольшим специфическим фрагментом знаний, требуемых для правильного ответа на этот вопрос, но может не знать никаких других географических фактов.
Другой способ посмотреть на эту проблему состоит в предположении, что в принципе не существует двух абсолютно эквивалентных заданий. Один человек может знать столицу Венесуэлы и
не знать столицы Эквадора; может так случиться, что другой человек с тем же общим уровнем географических знаний знает название столицы Эквадора, но не знает название столицы Венесуэлы. Поэтому рассматривать эти два задания как совершенно эквивалентные невозможно. Ответит ли испытуемый на задания правильно, зависит, с одной стороны, от общего фактора (факторов), измеряемого тестом (географических знаний и т.д.), ы, с другой стороны, от чего-то совершенно уникального, присущего конкретному заданию. Модель главных компонент предполагает, что вся вариативность ответов на задания объяснима одними общими факторами (например, географическими знаниями). Она не может рассматривать вероятность того, что каждое задание измеряет также определенную долю специфических знаний или навыков, которые для него являются уникальными. «Специфическая вариативность», по определению, не может быть предсказана на основе любого из общих факторов. Поэтому, даже если из матрицы извлекается столько же общих факторов, сколько там содержится переменных, общности переменных не будут равны единице, но обычно будут меньше, «исчезнувшая вариативность» будет объясняться «специфической вариативностью». Таким образом, модель факторного анализа предполагает, что для любого задания
общая вариативность = вариативность общего фактора + + вариативность специфического фактора + ошибка измерения.
Из этого следует, что факторный анализ — более сложный процесс, чем анализ компонент. В то время как компонентный анализ должен определить число извлекаемых факторов и то, как каждая переменная должна коррелировать с каждым фактором, факторный анализ должен установить (тем или иным способом), какой будет общность каждой переменной, если извлекается столько же факторов, сколько взято переменных. Другими словами, он должен также установить, какая часть вариативности заданий составляет вариативность общего фактора, а какая часть уникальна для каждой отдельной переменной и не может быть разделена с каким-нибудь другим заданием. Положительный момент связан с тем, что на практике не имеет слишком большого значения, какой анализ проводится — факторный или компонентный — поскольку оба ведут к сходным результатам. В действительности авторитетные специалисты по факторному анализу могут быть разделены на три группы. Одни считают, что факторный анализ (а от-
нюдь не компонентный) никогда не должен использоваться (например, Лэйланд Уилкинсон, который, согласно Стамму (Stamm, 1994, личное сообщение), боролся за то, чтобы изъять опции факторного анализа из своего статистического пакета SYSTAT. Коммерческое давление в конце концов победило). Другие поддерживают точку зрения, согласно которой метод факторного анализа является единственно законным (например, Carroll, 1993), и наконец, некоторые прагматики утверждают, что, поскольку обе методики в общем дают в значительной степени сходные решения, не играет особой роли, которая из них используется (например: Tabatchnik, Fidell, 1989; Юте, 1994).
В то же время вызывает беспокойство одна проблема: нагрузки, получаемые при компонентном анализе, всегда выше, чем нагрузки, появляющиеся в результате факторного анализа, поскольку первый допускает, что каждая переменная имеет общность, равную 1,0, в то время как последний подсчитывает величину общности в данном эмпирическом материале, и она обычно оказывается меньше, чем 1,0. Благодаря этому результаты, получаемые компонентным анализом, всегда выглядят более впечатляющими (имеют более высокие нагрузки), чем результаты факторного анализа. Это имеет большое значение для многих эмпирических правил, таких, как рассмотрение факторных нагрузок выше 0,4 (или меньше чем -0,4) в качестве наиболее «характерных» и исключение тех нагрузок, которые находятся между -0,39 и +0,39, но, к сожалению, эти вопросы почти не анализируются в литературе. Кроме того, чрезвычайно важно, чтобы авторы работ четко указывали, какую модель они используют: факторного или компонентного анализа. Некоторые авторы так и делают, в то время как другие говорят о факторном анализе, хотя реально проводят анализ главных компонент.
Использование факторного анализа
Факторный анализ имеет три основных применения в психологии. Во-первых, он может быть использован для конструирования тестов. Например, можно написать 50 заданий для измерения каких-либо способностей, личностной черты или аттитюда (такого, например, как консерватизм). Затем задания будут предъявлены репрезентативной выборке из нескольких сотен индивидуумов
и обработаны (в случае тестов способностей) таким образом, что правильный ответ будет кодироваться «1», а неправильный — «О». Ответы, которые получают при использовании ранговых шкал (как в большинстве опросников личности и аттитюдов), просто вводятся в их сыром виде: один балл, если выбирается вариант ответа (а), два балла, если выбирается вариант ответа (б), и т.д. Ответы на эти 50 заданий затем коррелируют между собой и подвергают факторному анализу. Задания, которые имеют высокие нагрузки по каждому фактору, измеряют один и тот же лежащий в их основе психологический конструкт и таким образом формируют шкалу. Это позволяет определить, как обрабатывать опросники в будущем, просто взглянув на факторную матрицу: если задания 1, 2, 10 и 12 — единственные, которые имеют существенные нагрузки по одному фактору, тогда одна шкала теста будет состоять только из этих четырех заданий. Существует вероятность, что некоторые задания не будут иметь существенной нагрузки ни по одному из факторов (т.е. обнаружат низкую степень общности). Это может случиться по целому ряду причин: в тесте способностей задания могут быть настолько простыми (или трудными), что вариативность оценок испытуемых либо будет очень маленькой, либо ее вообще не будет. Личностные задания могут быть связаны с необычным действием или чувством, где вариативность опять будет небольшой, например: «В моей жизни бывают случаи, когда я испытываю чувство страха», — утверждение, с которым, вероятно, каждый согласится. Задания могут оказаться несостоятельными, потому что они сильно подвержены ошибкам измерения или измеряют что-то отличное от всех остальных заданий, которые предъявлялись. Разработчики тестов обычно не выясняют, почему именно задания не работают так, как ожидалось. Задания, которым не удается как следует нагрузить фактор, просто удаляются. Таким образом, факторный анализ может выявить ряд особенностей:
• сколько отдельных шкал входит в состав теста;
• какие задания принадлежат к каким шкалам (указывая, таким образом, как тест следует обрабатывать);
• какие задания должны быть удалены из теста.
Кроме того, каждая из шкал нуждается в валидизации, например, путем подсчета баллов, полученных каждым человеком по каждому фактору, и оценки конструктной и(или) прогностической валидности этих шкал. Например, баллы, полученные по фак-
торам, можно прокоррелировать с баллами, полученными из других опросников, используемых для прогноза успешности обучения, и т.д. Вторая задача, которую может решить факторный анализ, заключается в редукции данных, или в «концептуальной чистке». Было разработано огромное количество тестов для измерения личности, основывающихся на различных теоретических позициях, и далеко не всегда очевидно, в какой степени они перекрываются. Представим себе, что на рынке предлагается шесть шкал для измерения несколько отличающихся аспектов личности: одна шкала претендует на измерение «негативной реактивности», другая — «силы Эго», третья — «интуитивного мышления» и т.д. Действительно ли они измеряют шесть совершенно разных параметров личности? Может быть, все они измеряют одну и ту же характеристику? Или истина заключается в том, что тесты измеряют два, три, четыре или пять отдельных аспектов личности? Чтобы узнать это, просто необходимо предъявить задания теста большой выборке людей и затем факторизовать корреляции между заданиями, и факторный анализ точно покажет, какова на самом деле лежащая в их основе структура. Например, может быть выделено два фактора. Первый фактор может иметь большие нагрузки по всем заданиям в тестах 1, 5 и 6. Все существенные нагрузки по второму фактору могут определяться заданиями из тестов 2, 3 и 4. Следовательно, становится ясным, что тесты 1, 5 и 6 измеряют одну и ту же характеристику, так же как и тесты 2, 3 и 4. Таким образом, можно показать, что любые утонченные теоретические дискуссии по поводу незначительных различий между шкалами в действительности не имеют основы и каждый рационально мыслящий психолог, увидя результаты такого анализа, вынужден будет анализировать материал в терминах двух (а не шести) теоретических конструктов, что представляет значительное упрощение.
Дата добавления: 2015-03-03; просмотров: 973;