Актуальность технического обслуживания 15 страница
. . <..., " . >-,-... . ......... .....
Задание для самопроверки 15.2
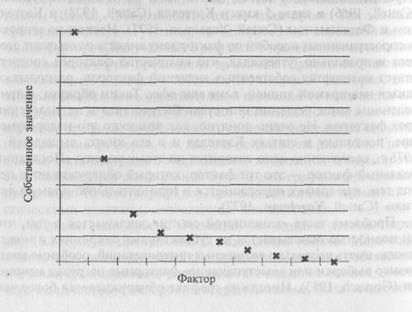
По графику, приведенному ниже, определите, сколько факторов можно было бы выделить с помощью теста «каменистой осыпи» и крите-
I Определение общностей
Общность переменной — это часть ее вариативности, которая может быть разделена с другими переменными, включенными в факторный анализ. В случае компонентного анализа допускается, что потенциально она составляет 100%. Это значит, что корреля-
|ции между переменными полностью приписываются вариативности общего фактора и ошибке измерения. В случае факторных моделей дополнительно предполагается, что каждая переменная обладает некоторой долей надежно измеряемой вариативности, которая «уникальна» для этой переменной и, следовательно, не может быть разделена с какими-либо другими переменными в анализе. Это «уникальная вариативность» переменной, поэтому общности переменных в моделях факторного анализа, как правило, составляют меньше 1,0 благодаря «уникальной вариативности», связанной с каждой переменной.
(Оценка общностей — процесс, который вызывает беспокойство у специалистов по факторному анализу, потому что не существует простого способа проверить, правильны ли оценки, которые для этого применяют. Иногда используемые процедуры приводят к нелепым оценкам общностей, которые оказываются больше 1,0 («случаи Хейвуда»), Проблемы, связанные с этим, могут побудить многих исследователей использовать более простую компонентную модель.
Разные методы выделения факторов отличаются способами, которые исполБзуются для оценки общностей. Простейшим явля-
|ется анализ главного фактора, в котором общности в первую очередь оцениваются с помощью серии множественных регрессий, при этом все другие переменные используются в качестве «предикторов». Поскольку общность определяется как пропорция вариативности какой-либо переменной, разделяемой с другими переменными, участвующими в анализе, считается, что это дает «нижний предел» общности — наименьшую величину, которую вообще может иметь общность, хотя работа Кайзера (Kaiser, 1990) оспаривает эту точку зрения. Многие компьютерные программы (такие, как SPSS) затем несколько раз модифицируют эти величины, используя процесс, известный как «итерация», до тех пор, пока не будет достигнута стабильность. Однако, к сожалению, теоретические основания для повторной итерации сомнительны и [ нет гарантий, что они дадут правдоподобные оценки подлинных
величин общностей. Можно также определить значение общностей непосредственно, и некоторые компьютерные программы позволяют пользователю выбирать другие значения, такие, как самая большая корреляция между каждой переменной и любой другой. Критерий максимального правдоподобия решает проблему общности наиболее разумным путем. Следует подчеркнуть, что на самом деле на практике редко имеет значение, какая методика используется.
Выделение факторов
Для выделения факторов существует ряд приемов, и все они имеют различные теоретические основания. Большинство статистических пакетов предлагает пользователям выбор между анализом главных факторов, анализом образов, методом максимального правдоподобия, анализом невзвешенных минимальных квадратов («MINRES») и обобщенных минимальных квадратов. Большинство из этих методов имеют свои собственные, присущие только им приемы для оценки общностей. На практике при условии, что оценивается одинаковое количество факторов и общностей, все методы будут, как правило, давать почти идентичные результаты.
Теперь, однако, мы должны признать, что в предыдущей главе излишне упростили процедуру, благодаря которой факторы проводятся через кластеры переменных. На практике этот процесс имеет две стадии. Сначала факторы помещаются в некоторую произвольную позицию по отношению к переменным, а затем факторы проводят через кластеры переменных (эта процедура называется вращение фактора).
Следовательно, все вышеупомянутые методы выделения факторов помещают факторы, по сути, в произвольные положения по отношению к переменным. В типичных случаях факторы располагают так, чтобы каждый последующий фактор находился:
• под прямыми углами по отношению к предыдущим факторам
и
• в положении, в котором он «объясняет» существенную часть вариативности заданий (т.е. там, где его собственное значение велико).
На рис. 15.2 представлены корреляции между четырьмя переменными от VI до V4. Можно видеть, что VI и V2, так же как V3 и
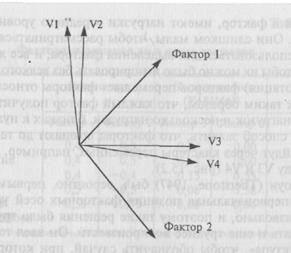
Рис. 15.2. Типичные позиции двух факторов по отношению к четырем переменным, наблюдающиеся после выделения факторов.
V4, значительно коррелируют между собой. Изучение рисунка показывает, что наиболее разумным было бы двухфакторное решение, при котором один фактор проходит между VI и V2, а другой — между V3 и V4. Однако первоначальное выделение не помещает факторы в эту осмысленную позицию. Вместо этого первый фактор проходит между двумя кластерами переменных, а не через середину любого из них. Все переменные будут иметь умеренные положительные нагрузки по этому фактору. Второй фактор находится под прямым углом к первому и имеет положительные корреляции с переменными V3 и V4 и отрицательные корреляции с VI и V2. Ни в одном случае фактор не проходит через середину пары высококоррелирующих переменных.
Вращение факторов
Вращение факторов изменяет положение факторов по отношению к переменным таким образом, что получаемое решение легко интерпретировать. Как упоминалось в главе 14, факторы выделяют, учитывая, какие переменные имеют большие и/или нулевые нагрузки по ним. Решения, не поддающиеся интерпретации, — это те решения, в которых большое число переменных,
вошедших в фактор, имеют нагрузки «среднего уровня», т.е. порядка 0,3. Они слишком малы, чтобы рассматриваться как «весомые» и использоваться для выделения фактора, и все же слишком велики, чтобы их можно было игнорировать без всякого риска. Вращение (ротация) факторов перемещает факторы относительно переменных таким образом, что каждый фактор получит несколько больших нагрузок и несколько нагрузок, близких к нулю. По сути это иной способ заявить, что факторы вращают до тех пор, пока те не пройдут через кластеры переменных, например, между VI и V2 и между V3 и V4 (рис. 15.2).
Терстоун (Therstone, 1947) был, вероятно, первым, кто осознал, что первоначальная позиция факторных осей устанавливалась произвольно, и поэтому такие решения было трудно интерпретировать и еще труднее воспроизвести. Он ввел термин «простая структура», чтобы обозначить случай, при котором каждый фактор имеет некоторое число больших нагрузок и некоторое число маленьких и аналогично каждая переменная имеет существенные нагрузки только по небольшому числу факторов. Его «эмпирические правила» были тщательно обобщены в работе Чайлда (Child, 1990, р. 48).
Табл. 15.1 демонстрирует, насколько легче интерпретировать факторные решения, полученные после вращения, по сравнению с решениями, имевшимися до вращения. Решение, имевшееся до вращения, трудно интерпретировать, поскольку все переменные имеют умеренные нагрузки по первому фактору, в то время как второй фактор, по-видимому, дифференцирует «математические» и «языковые» способности. После вращения решение становится абсолютно ясным. Первый фактор, по-видимому, измеряет языковые способности (благодаря существенным нагрузкам по тестам понимания и правописания), второй — соответствует математическим способностям. Представлены также собственные значения факторов и общности. Благодаря этому становится ясным, что во время вращения общность каждой переменной остается той же самой, а собственные значения факторов — нет.
Перед вращением факторов необходимо принять одно принципиальное решение. Должны ли они оставаться под прямым углом друг к другу («ортогональное вращение») или следует допустить их взаимную корреляцию («облическое вращение»)? Рис. 15.3 четко показывает, что облическое решение иногда необходимо, чтобы позволить факторам занять осмысленное положение по от-
Таблица 15.1
Факторные решения до и после вращения
| До вращения | После вращения | h2 | |||
| ( VARIMAX) | |||||
| Фактор 1 | Фактор 2 | Фактор 1 | Фактор 2 | ||
| Понимание | 0,4 | 0,3 | 0,50 | 0,00 | 0,25 |
| Правописание | 0,4 | 0,5 | 0,64 | 0,00 | 0,41 |
| Сложение | 0,4 | -0,4 | 0,13 | 0,55 | 0,32 |
| Вычитание | 0,5 | -0,3 | 0,06 | 0,58 | 0,34 |
| Собственное | 0,59 | 0,73 | 0,68 | 0,64 | 1,32 |
| значение фактора |
ношению к переменным. Однако вычисление и интерпретация ортогональных решений значительно проще, что объясняет их большую популярность.
Компьютерная программа Кайзера (Kaiser, 1958) VARIMAX представляет в высшей степени распространенный выбор ортогональных вращений, и многие компьютерные программы осуществляют ее как задаваемую по умолчанию. Для тех, кто заинтересован в подобных процедурах, отметим, что концептуально это достаточно просто. Табл. 15.2 содержит квадраты каждой нагрузки из табл. 15.1 (возведение в квадрат используется для того, чтобы удалить отрицательные знаки в тех случаях, когда они есть). Нижний ряд табл. 15.2 представляет вариативность (квадрат стандартного отклонения) этих четырех нагрузок, возведенных в квадрат. Видно, что, поскольку некоторые из нагрузок в матрице после вращения были больше, а другие — меньше, вариативность квадратов нагрузок после вращения оказывается намного больше, чем вариативность нагрузок в матрице до вращения (0,041 и 0,034 по сравнению с 0,002 и 0,006). Следовательно, если факторы располагаются так, что вариативность нагрузок (возведенных в квадрат) максимально велика, это должно быть гарантией, что достигнута «простая структура». И это именно тот способ (с очень небольшими модификациями, которые здесь нет необходимости рассматривать), каким действует программа VARIMAX. Она находит вариант вращения, при котором вариативность квадратов факторных нагрузок максимальна.
Таблица ]5.2
Возведенные в квадрат факторные нагрузки из табл. 15.1, демонстрирующие принцип вращения по методу VARIMAX
До вращения После вращения
(VARIMAX)
______________Фактор I Фактор 2^ Фактор 1 Фактор 2
Понимание 0,160 0,090 0,250 0,000
Правописание 0,160 0,250 0,410 0,000
Сложение 0,160 0,160 0,017 0,302
Вычитание 0,250 0,090 0,003 0,336
Вариативность 0,002 0,006 0,038 0,034 квадратов нагрузок
Облическое вращение является более сложным. Первая проблема заключается в определении того, может ли такое вращение привести к появлению простой структуры. Вы помните, что «факторная структурная матрица» содержит корреляции между всеми переменными и всеми факторами. Из рис. 15.3 ясно, что, хотя каждый фактор проходит точно через кластер переменных, поскольку факторы коррелируют между собой, больше не соблюдается положение, при котором каждая переменная имеет большую нагрузку (корреляцию) только в одном факторе. Поскольку факторы коррелируют между собой, корреляции между VI, V2 и V3 и фактором 2 не приближаются к нулю. Подобно этому, хотя V4, V5 и V6 будут иметь значительные нагрузки по фактору 2, они будут также иметь существенные корреляции с фактором 1. Это значит, что больше нельзя использовать факторную структурную матрицу, чтобы определить, достигнута ли «простая структура».
Для этой цели может быть вычислена другая матрица, называемая «матрицей факторных паттернов». Она не дает корреляции между переменными и факторами; на самом деле числа, которые она включает, могут быть больше 1,0. Зато она показывает, какому фактору какие переменные «принадлежат», по сути, корректируя структуру матрицы с учетом корреляций между факторами. Таким образом, она может быть использована, чтобы определить, достигнута ли простая структура.
Для данных, представленных на рис. 15.3, матрица факторных паттернов будет напоминать запись, полученную при вращении
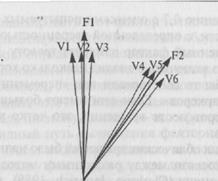
Рис. 15.3. Шесть переменных и два коррелирующих фактора.
методом VARIMAX из табл. 15.1. (В случае ортогональных вращений, таких, как VARIMAX, корреляция между факторами всегда равна О, и не существует корреляций между факторами, которые нуждались бы в корректировке. Таким образом, числа в матрице факторных паттернов соответствуют числам в структурной матрице.)
Настораживает тот факт, что не существует единой точки зрения относительно того, что следует интерпретировать — матрицу факторной структуры или матрицу факторных паттернов, для того чтобы отождествить факторы или сообщить результаты факторного анализа. Например, Клайн (Kline, 1994, р. 63) констатирует, что «очень важно... чтобы интерпретировалась структура, но не паттерн», однако Кэттелл (Cattell, 1978, ch. 8), а также Табачник и Файделл (Tabatchnick, Fidell, 1989, p. 640) придерживаются полностью противоположного мнения. Брогден (Brogden, 1969) предполагает, что если факторный анализ использует хорошо понятные тесты, но интерпретация факторов неизвестна, тогда следует принимать во внимание матрицу факторных паттернов. Напротив, если известна природа факторов, тогда следует принимать во внимание структурную матрицу. Позиция Брогдена в этом вопросе кажется обоснованной.
У читателей может вызвать удивление тот факт, что вообще существует возможность идентификации фактора, а не переменных, которые в него входят. Однако это так. Например, можно провести корреляционный и факторный анализы выборки поведенческих и психологических показателей. Факторные оценки мо-гут быть подсчитаны для каждого человека, и их можно прокорре-лировать с другими тестами. Если набор факторных оценок обна-
| До вращения | После вращения | |||
| (VARIMAX) | ||||
| Фактор I | Фактор 2 | Фактор 1 | Фактор 2 | |
| Понимание | 0,160 | 0,090 | 0,250 | 0,000 |
| Правописание | 0,160 | 0,250 | 0,410 | 0,000 |
| Сложение | 0,160 | 0,160 | 0,017 | 0,302 |
| Вычитание | 0,250 | 0,090 | 0,003 | 0,336 |
| Вариативность | 0,002 | 0,006 | 0,038 | 0,034 |
| квадратов нагрузок |
руживает корреляцию 0,7 с оценками испытуемых по признанной шкале тревожности, с определенной уверенностью можно сделать вывод, что полученный фактор измеряет тревогу. В качестве альтернативы можно включить в анализ несколько хорошо проверенных тестов', чтобы те действовали как «переменные, выполняющие функцию маркеров». Если они имеют большие нагрузки по одному из факторов после вращения, это четко выявит природу данных факторов.
Для проведения облических вращений было написано несколько программ; взаимосвязи между различными методами обсуждают Кларксон и Дженнрих (Clarkson, Jennrich, 1988), а также Харман (Harman, 1967). Техники, подобные Прямому Облимину (Jennrich, Sampson, 1966), входят в число наиболее полезных. Почти все эти программы для достижения простой структуры нуждаются в «тонкой настройке» (Harman, 1976) обычно с помощью программного параметра, который контролирует получение облических факторов. Он определяется задаваемой по умолчанию величиной, которая, как отчасти надеется автор программы, будет адекватна в большинстве случаев. Использование этой величины вслепую — хотя и распространенная, но опасная практика. Харман (Harman, 1967) предлагает использовать несколько вращений — каждое с разным значением этого параметра — и интерпретировать то из них, которое окажется самым близким к простой структуре. Я нахожу этот совет вполне обоснованным.
Задание для самопроверки 15.3
Что такое простая структура и почему «получение простой структуры путем вращения» практически всегда осуществляется в ходе факторного анализа?
Факторы и факторные оценки
Представим себе, что проводится факторный анализ заданий теста, измеряющего некоторые умственные способности, например, скорость, с которой люди могут визуально представить себе, как будут выглядеть различные геометрические формы после их вращения или переворачивания. После выполнения факторного или компонентного анализа полученных данных можно обнаружить, что большую часть вариативности объясняет один фактор, в котором существенные нагрузки имеют многие задания теста.
Можно валидизировать этот фактор точно таким же способом, как стали бы валидизировать тест (последнее обсуждалось в главе 13). Например, можно определить, насколько высоко фактор коррелирует с другими психологическими тестами, измеряющими пространственные способности, с показателями выполнения теста и т.д. Однако, чтобы сделать это, необходимо для каждого испытуемого получить показатель по этому фактору — его «факторную оценку».
Один очевидный путь вычисления факторной оценки заключается в том, чтобы выделить задания, имеющие существенные нагрузки по данному фактору, и для каждого испытуемого суммировать оценки, полученные по этим заданиям, игнорируя задания, которые имеют незначительные нагрузки по данному фактору. Например, представим себе, что показатели времени ответов были профакторизованы только для четырех заданий и что они получили факторные нагрузки 0,62; 0,45; 0,18 и 0,90 (после вращения). Это дает основание считать, что задания 1, 2 и 4 измеряют в значительной степени один и тот же конструкт, в то время как задание 3 измеряет скорее что-то отличное от них. Следовательно, можно было бы просмотреть файл данных и у каждого испытуемого усреднить показатели времени ответов только на задания 1, 2 и 4. Таким образом, каждый испытуемый получит «факторную оценку», являющуюся показателем скорости, с которой они могут решить три задания, имеющие существенные нагрузки по фактору. Другой способ проанализировать это — допустить, что оценки каждого испытуемого «взвешены» с использованием следующих чисел 1, 1, 0 я 1. Вес, равный «1», дается, если факторная нагрузка считается существенной (выше 0,4 например); вес, равный нулю, соответствует маленьким незначимым факторным нагрузкам. Таким образом, факторная оценка испытуемого может быть вычислена по такой формуле:
или
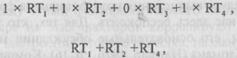
где символы от RT, до RT4 представляют показатели времени ответа на задания с 1-го по 4-е, соответственно. «Веса» (нули или единицы) называются «коэффициентами факторной оценки». Если вычислены факторные оценки каждого испытуемого, их можно коррелировать с другими переменными, чтобы установить валид-ность этого показателя пространственных способностей.
Хотя эта методика вычисления факторных оценок иногда встречается в литературе, она на самом деле имеет свои недостатки. Например, хотя задания 1, 2 и 4 имели факторные нагрузки больше 0,4, задание 4 имело нагрузку, которая существенно выше, чем нагрузка задания 2. Это означает, что задание 4 представляет собой намного лучший показатель фактора, чем задание 2. Должны ли веса — «коэффициенты факторной оценки» — отражать это? Вместо того чтобы быть нулями и единицами, должны ли они каким-то образом быть связаны с размером факторных нагрузок? Этот подход явно имеет смысл, и стандартная программа факторного анализа почти неизменно будет предлагать пользователям опцию вычисления этих коэффициентов факторных оценок — по одной для каждой переменной и для каждого фактора. После их получения не составит труда умножить оценку каждого испытуемого по каждой переменной на соответствующий коэффициент факторной оценки и таким образом вычислить «факторную оценку» каждого испытуемого по-каждому фактору. Большинство компьютерных программ даже сделают это вычисление за вас.
Для полноты картины следует упомянуть, что коэффициенты факторной оценки не применимы к «сырым» оценкам по каждому заданию, их можно использовать только со «стандартизованными» оценками. Рассмотрим задание-1. Если испытуемый имеет время ответа на это задание 0,9 с, тогда как среднее время ответа на остальные задания выборки вместе с этим заданием составляет 1,0с, а стандартное отклонение — 0,2 с, то время ответа 0,9 с
будет преобразовано в стандартизованную величину
Именно эта величина, а не первичная величина 0,9 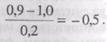 с, используется при вычислении факторных оценок.
с, используется при вычислении факторных оценок.
Сама процедура вычисления коэффициентов факторной оценки не должна нас здесь беспокоить. Для тех, кто заинтересуется этим вопросом, его основательные обсуждения можно найти в руководствах Хармана (Harman, 1976, ch. 16), Комри и Ли (Comrey, Lee, 1992, sec. 10.3), а также Харриса (Harris, 1967). Вычисление факторных оценок — простое дело, когда используется анализ главных компонент, проблема усложняется в случае применения любой формы факторного анализа. Здесь существует несколько разных методов, предназначенных для вычисления факторных оценок, каждый со своими собственными достоинствами и недостатками.
Метод Бартлетта — один из лучших (как утверждают McDonald, Burr, 1967-), и он присутствует как опция во многих пакетах по факторному анализу.
Задание для самопроверки 15-4
Предположим, что менеджер по персоналу провел факторный анализ оценок соискателей по ряду тестов. Как можно использовать этот анализ для того, чтобы решить, какие тесты больше не будут предсказывать, насколько хорошо работники справятся со своими обязанностями?
Иерархический факторный анализ
Когда проводится облическое факторное вращение, получае-1ые факторы обычно коррелируют между собой. Матрица взаим-1ых корреляций факторов представляет углы между факторами, и :ама может быть подвергнута факторному анализу. Иначе говоря, сорреляции между факторами можно проанализировать и выде-шть любые кластеры факторов, т.е. произвести факторный анализ (второго порядка», или «второго уровня» (факторизация корреляций между переменными — это анализ «первого порядка»), и ис-;ледователи, например, Кэттелл, широко использовали эту мето-щку. Полезность такого анализа можно проиллюстрировать с по-ющью примера.
Недавно вместе с Крисом МакКонвиллом мы задались целью установить, какими могут быть основные параметры настроения [McConville, Cooper, 1992b). Мы провели факторный анализ кор->еляций более 100 заданий, направленных на оценку настроения, извлекли и подвергли облическому вращению пять факторов первого порядка, соответствующих основным параметрам настроения, обсуждавшимся в главе 10. Затем мы провели факторный анализ корреляций между этими факторами первого порядка и обнаружили, что четыре из этих факторов коррелируют между собой, образуя фактор настроения второго порядка, названный «негативный аффект». Пятый фактор настроения имел незначительную нагрузку по этому фактору. Таким образом была установлена иерархия факторов настроения, как показано на рис. 15.4.
Если имеется много факторов второго порядка и они обнаруживают приемлемую степень корреляции, будет вполне законным провести факторный анализ корреляций между факторами второго порядка, чтобы выполнить факторный анализ третьего порядка.
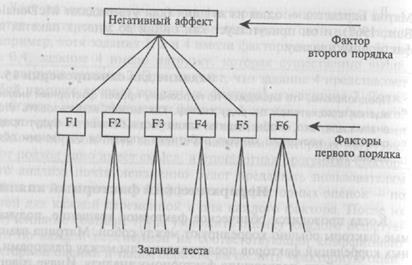
Рис. 15.4. Пример иерархического факторного анализа из работы Мак-Конвилла и Купера (McConville, Cooper, 1992b).
Процесс можно продолжать либо до тех пор, пока корреляции не станут, по сути, равными нулю, либо до тех пор, пока не получится только один фактор.
Проблема, присущая этому иерархическому анализу, состоит в том, что может быть чрезвычайно трудно идентифицировать или концептуализировать факторы второго и более высоких порядков. В то время как факторы первого порядка могут быть экспериментально идентифицированы выделением заданий с существенными нагрузками, матрица факторов второго порядка показывает, как факторы первого порядка нагружают фактор (факторы) второго порядка. По этой причине может быть достаточно сложно идентифицировать факторы второго порядка. Например, что можно было бы сделать с фактором, который, оказывается, измеряет первичные способности к правописанию, визуализации образов и способности в области механики. Было бы намного легче проанализировать, что происходит, если бы можно было показать, что около дюжины переменных имеют большие нагрузки по фактору второго порядка, вместо того чтобы пытаться интерпретировать факторы второго порядка в категориях только двух больших нагрузок, присущих факторам первого порядка.
Для того чтобы преодолеть эту проблему, было изобретено несколько методов. Все они связывают факторы второго и более высоких порядков с непосредственно наблюдаемыми переменными (Schmid, Leiman, 1957). В приведенном выше примере факторы второго порядка будут определены не в категориях первичных факторов (правописание, визуализация, способности в области механики и т.д.), а в категориях действительных переменных. МакКон-велл и Купер (McConville, Cooper, 1992b) приводят пример использования этой методики на практике. Ни один из стандартных пакетов, осуществляющих факторный анализ, не включает мето-- дику Шмида—Лемана, но такие пакеты, как EQS и LISREL (описанные ниже), могут выполнять подобный анализ.
Вторая проблема, связанная с таким анализом, касается ошибки измерения. Иногда несколько довольно разных факторов первого порядка почти в полной мере удовлетворяют требованиям, поскольку это касается критерия соответствия простой структуре. Однако более или менее произвольный выбор одного такого решения будет оказывать мощный эффект на корреляции между факторами и, следовательно, на количество и природу факторов второго порядка. Факторный анализ следует осуществлять с особой тщательностью, если предполагается получить иерархические решения.
Конфирматорный факторный анализ
Л,
Полное изучение этой темы выходит за рамки данного текста. Цель этого раздела — просто указать на то, что существует такой метод, и дать пример его использования. В то время как основная цель исследовательского факторного анализа заключается в определении (путем вращения факторов и достижения простой структуры) количества и природы факторов, которые лежат в основе данных, конфирматорный факторный анализ (как следует из его названия) проверяет гипотезы или, скорее, позволяет пользователю выбрать между несколькими конкурирующими гипотезами, описывающими структуру данных. Например, предположим, вас заинтересовало использование опросника, измеряющего отношение к питанию. В результате обзора литературы вы можете установить, что в части предшествующих исследований утверждается, что 10 из 20 заданий формируют один фактор, а оставшиеся 10 заданий формируют другой фактор, и корреляция этих факторов рав-
на 0,4. Другая часть исследований с применением того же теста может указывать на то, что все 20 заданий теста формируют один фактор. Принципиально важно узнать, которое из этих утверждений правильно. В результате первого у каждого человека будут вычислены две оценки, в то время как второе будет приводить только к одной оценке. Для того чтобы определить, какая из этих конкурирующих моделей лучше всего соответствует данным, можно использовать конфирматорный факторный анализ.
Для конфирматорного факторного анализа можно использовать модели либо исследовательского факторного анализа, либо метода главных компонент. Однако почти все исследования базируются на моделях исследовательского факторного анализа, где устаналиваются общности каждой переменной. В действительности можно выполнить иерархический факторный анализ и проверить огромный диапазон моделей, используя эту методику. Хорошее описание конфирматорного факторного анализа и источника его происхождения — моделирования с помощью линейных структурных уравнений дается, в частности, в работах Лонга (Long, 1983), Лоелина (Loehlin, 1987) и Комрея и Ли (Comrey, Lee, 1992, ch. 12, 13). Клайн (Kline, 1994) и Чайлд (Child, I990) предлагают более простое введение в эту проблему.
Ряд компьютерных программ .был написан для выполнения конфирматорного факторного анализа. Наиболее известная из них — LISREL — разработана Карлом Йорескогом, статистиком, который изобрел этот метод. EQS (Bentler, 1989) — другая программа, которая, по-видимому, проще для использования, чем LISREL. Поскольку конфирматорный факторный анализ — одна из простейших форм моделирования с помощью линейных структурных уравнений, любая программа такого типа должна выполнять этот анализ,
Конфирматорный факторный анализ рассматривает базисные данные (тестовые оценки, ответы на задания теста, физиологические показатели и т.д.) как вызванные или обусловленные одним (или более) фактором (часто называемым «латентной переменной»). Таким образом, может быть составлен ряд уравнений, каждое из которых предположительно показывает, какой фактор (факторы) влияет на какую переменную (переменные).
Дата добавления: 2015-03-03; просмотров: 1077;