Актуальность технического обслуживания 12 страница
Конструктная валидность
Один из полезных способов проверки того, действительно ли тест измеряет то, что он должен измерить, — проведение продуманных экспериментов. Представим себе, что тест предназначен для измерения тревожности студентов университетов Великобритании. Как можно проверить его валидность с помощью эксперимента?
Первый подход, иногда называемый «конвергентная валиди-зация», состоит в том, чтобы проверить, связаны ли тестовые оценки с другими показателями, как ожидается. Например, если в арсенале методик имеются другие широко используемые тесты тревоги, группе студентов могут быть предъявлены оба теста и полученные ряды оценок подвергнуты корреляционному анализу. Высокая положительная корреляция дала бы основание полагать, что новая шкала валидна.
С другой стороны, группе студентов, заявляющих о том, что у них есть фобия по отношению к паукам, можно было бы предъя-
вить этот тест перед и после показа им тарантула. Если их оценки увеличатся, это может означать, что тест действительно измеряет тревогу. Основная цель таких приемов конвергентной валидизации состоит в том, чтобы определить, будут ли оценки теста варьировать в соответствии с теоретическими ожиданиями. К сожалению, неудачные попытки установить ожидаемые связи могут быть обусловлены некоторыми проблемами либо с самим тестом, либо с другими средствами измерения. Например, другой тест тревоги может быть не валиден или некоторые из индивидуумов, заявляющие, что они боятся пауков, на самом деле могут и не испытывать такого чувства. Однако если оценки теста действительно варьируют в соответствии с теорией, вывод о том, что тест валиден, представляется разумным.
Второй подход — исследование «дивергентной валидности» — устанавливает, что тест не измеряет никакой черты, с которой он теоретически не должен быть связан. Например, в литературе утверждается, что тревога не связана с интеллектом, социально-экономическим статусом, социальной желательностью и т.д. Поэтому если тест, направленный на измерение тревоги, на самом деле обнаружил высокую корреляцию с любой из этих переменных, должны возникнуть сомнения в том, действительно ли он измеряет тревогу в целом.
Прогностическая вал идность
Психологические тесты очень часто используются для прогноза поведения, и их успех в этом известен как прогностическая валидность. Например, тест может быть дан подросткам с целью предсказать, кто из них будет страдать шизофренией в дальнейшей жизни, или психологический тест может быть использован для отбора наиболее перспективного кандидата на должность продавца — тест будет обладать прогностической валидностью, если с его помощью можно показать, что люди с более высокими тестовыми оценками будут иметь больший объем продаж. Этот процесс производит впечатление очень простой, прямолинейной процедуры, но на практике таковой не является.
Первая проблема заключается в природе критериев, по которым проводится оценка теста. Хотя постановка диагноза шизофрении или определение объема продаж достигается достаточно прямыми способами, для характеристики многих видов деятельности одного критерия недостаточно. Работа университетского препода-
вателя иллюстрирует это положение. Моя работа включает преподавание, администрирование и исследование, наблюдение за аспирантами, обеспечение неформальной помощи по вопросам статистики и программирования, поддержку и ободрение студентов и т.д. — перечень достаточно длинный. При этом совсем не ясно, как можно оценить большинство этих видов деятельности или определить их относительную важность. В других случаях (например, когда управляющие ранжируют работников) разные эксперты могут пользоваться абсолютно разными эталонами.
Вторая прблема известна как «ограничение диапазона». Система отбора обычно состоит из нескольких стадий: например, первичное психометрическое тестирование уменьшает число соискателей, доводя его до контролируемых пропорций, за ним следует собеседование и более детальная психологическая оценка индивидуумов, которые прошли через первую стадию. В конечном счете все соискатели, получающие назначение, будут иметь похожие (высокие) оценки по тестам отсеивания (иначе они были бы отвергнуты перед стадией собеседования), и, таким образом, диапазон оценок в группе отобранных индивидуумов окажется намного меньше, чем в общей популяции. Последнее создаст проблемы для любой попытки валидизировать скрининговый тест, поскольку этот ограниченный диапазон способностей будет уменьшать корреляцию между тестом и любым критерием. Имеются способы решения данной проблемы (см.: Dobson, 1988; он предлагает одно из лучших решений), но эти два примера показывают, насколько трудно установить прогностическую валидность теста.
Задание для самопроверки 133
(а) Должен ли надежный тест быть валидным?
(б) Должен ли валидный тест быть надежным?
(в) Что такое «конструктная валидность», «содержательная валидность» и «прогностическая валидность» теста?
(г) Что такое «конвергентная валидность» и «дивергентная валидность»?
Резюме
Надежность теста важна, потому что она показывает, насколько близко тестовая оценка приближается к подлинной оценке личности по измеряемой черте. Следовательно, она показывает, разум-
но ли использовать оценку, полученную по определенному тесту, как средство измерения скрытой черты. К сожалению, довольно легко завысить коэффициент надежности альфа, включая в тест задания, которые, по сути, просто перефразируют друг друга. Это очевидная проблема, которая недостаточно явно представлена в литературе. Чтобы избежать этого, создателям теста необходимо проверять все пары заданий, гарантируя таким способом их локальную независимость.
Принципиально важно установить перед использованием теста для каких-либо целей его содержательную валидность, конструктную валидность и(или) прогностическую валидность. Тест с низкой надежностью не может быть валидным измерением черты. Однако высокая надежность не гарантирует высокую валидность.
Предложения
по дополнительному чтению
Все учебники по психометрике и многие книги по статистике дают описания теории надежности. Среди них лучшими являются — книги Кронбаха (Cronbach, 1994 и другие издания), Анастази (Anastasi, 1961 и другие издания), а также Гилфорда и.Фрачтера (Guilford, Fruchter, 1978). Специалисты по психометрике обычно рекомендуют книгу Нанелли (Nunnally, 1978); многие формулы, упомянутые выше, взяты из этой работы, например, формулы, показывающие, как надежность связана с подлинной оценкой черты (уравнение 6.1) и насколько близка оценка надежности (вычисленная на одной выборке испытуемых) к ее подлинному значению (Nunnally, 1978, р. 208; обратите внимание на опечатку в уравнении 6.13, р. 207).
Ответы на задания по самопроверке
13.1 (а) При допущении, что каждая пара заданий находится под влиянием различных наборов посторонних факторов, корреляция будет показывать степень, с которой пара заданий оценивает измеряемую черту, в данном случае — экстраверсию.
(б) Поскольку вопрос 1 обнаруживает низкую корреляцию со всеми другими вопросами, он, по-видимому, является плохим средством измерения экстраверсии.
(в) Очевидно, следовало бы написать больше вопросов теста, дать старые и новые вопросы новой выборке испытуемых (по крайней мере 200 человек) и заново вычислить корреляции и коэффициент альфа. Существует также другая возможность. Мы
видели в ответе на вопрос (б), что вопрос 1 на самом деле не ачень удачен, он обнаруживает низкие корреляции со всеми другими вопросами теста. Удаление этого вопроса из теста увеличит среднюю корреляцию между оставшимися вопросами (от 0,206, базирующейся на 10 корреляциях, до 0,285, базирующейся на 6 корреляциях) и сократит длину теста. Первый фактор будет вести к увеличению коэффициента альфа, второй— к уменьшению. Таким образом, возможно (хотя и не обязательно), что удаление вопроса 1 может также увеличить коэффициент альфа. Мы вернемся к этому в главе 18.
13.2. (а) Альтернативные названия внутренней согласованности, или надежности, теста, которую я называю «альфа» на протяжении всей книги.
(б) Подобные действия обеспечивают очень высокую надежность, поскольку задания разделяют общую специфическую вариативность, так же как и измерение одной и той же черты.
(в) Стандартная ошибка измерения (SEM) показывает, насколько точными окажутся оценки индивидуумов. Если по результам некоторого теста показатель IQ ребенка оказался равен 100, а SEM — 3, мы могли бы с большим основанием считать, что в этом случае интеллект ребенка в действительности был равен 100, чем в том случае, когда тест имел бы ошибку измерения, равную 5.
(г) -^/0,81 = 0,9 и ^/0,56 = 0,75. Представим себе, что тест 2 был
абсолютно надежен. В этом случае корреляция между тестом 1 и тестом 2 должна быть такой же, как корреляция между тестом 1 и подлинной оценкой, т.е. 0,9. Однако, поскольку тест 2 не является совершенно надежным, корреляция будет ниже. Можно показать, что самая большая корреляция, которую только можно ожидать между двумя тестами, представляет собой произведение квадратных корней из показателей их надежности. В этом случае не следовало бы ожидать, что тесты будут корре-
I
лировать более чем
0,68. Это со-
впадает с тем, что я говорил ранее, указывая на то, что всю вариативность шкалы репрессии—сенситизации можно объяснить социальной желательностью, хотя корреляция между двумя шкалами была только -0,91, а не -1,0.
13.3. (а) Совершенно определенно нет. Высокая надежность говорит вам, что тест измеряет некоторую черту или состояние, не объясняя, что представляет собой эта черта или состояние. (б) Да. Хотя имейте в виду, если надежность небольшой шкалы
оказывается слишком высокой (например, шкала из 10 вопросов с надежностью 0,9), это дает основания полагать, что один и тот же вопрос перефразировали несколько раз.
(в) Смотри текст.
(г) При конструктной валидизации конвергентная валидность — показатель того, в какой степени тест коррелирует с характеристиками, с которыми он должен коррелировать, если он валиден; например, в какой степени тест IQ коррелирует с оценками академической успеваемости детей, которые дают учителя. Дивергентная валидность подтверждает, что тест обнаруживает незначимые корреляции с характеристиками, с которыми он теоретически не должен быть связан. Например, оценки, полученные по тесту IQ, можно было бы коррелировать с тестами, измеряющими социальную желательность, различные аспекты личности и т.д.; при этом предполагается, что такие корреляции будут близки к нулю.
ФАКТОРНЫЙ АНАЛИЗ
Факторный анализ — это статистический инструмент, который лежит в самой основе исследования индивидуальных различий. Многочисленные варианты его использования включают конструирование тестов, выявление основных параметров личности и способностей, установление того, сколько отдельных психологических характеристик (т.е. черт) измеряется набором тестов или заданиями теста. В этой главе вводится широкое понятие факторного анализа. Детали того, как выполнять и интерпретировать факторный анализ, описываются в главе 15.
Главы, рекомендуемые для предварительного чтения
1, 11 и 13.
Введение
Мы должны начать с упоминания о том, что термин «факторный анализ» может относиться к двум довольно разным статистическим методикам. Исследовательский факторный анализ* — более старая (и более простая) методика, ее описание составляет основу этой главы и первый раздел главы 15. Конфирматорный факторный анализ и его разновидности (известные как «анализ путей», «анализ латентных переменных» или «модели LJSREL») полезны во
* В отечественной литературе он иногда называется эксплораторным фактор-ным анализом. (Прим. науч. ред.)
= 1-989
многих областях за пределами изучения индивидуальных различий и особенно популярны в социальной психологии. Краткое описание этой методики дается в конце главы 15. Авторы не всегда четко указывают, какой из видов факторного анализа использовался — исследовательский или конфирматорный. Если вы увидите термин «факторный анализ» в журнале, следует допустить, что имеется в виду исследовательский факторный анализ.
В главе 13 было показано, почему важно, чтобы все задания шкалы измеряли одну (и только одну) психологическую переменную, и кроме того, был введен коэффициент альфа как показатель надежности шкалы. Эта техника исходит из того, что все задания в тесте формируют одну шкалу и коэффициент надежности, в сущности, проверяет, насколько это допущение обоснованно.
Альтернативный подход может включать исследование выборки заданий теста и выявление того, сколько различных шкал они содержат и какие задания принадлежат каждой шкале (шкалам). Предположим, что психолог предъявлял группе испытуемых ряд словарных заданий, несколько заданий — на понимание и несколько заданий, содержащих анаграммы. Наиболее полезным было бы узнать, будут ли словарные задания формировать первую шкалу, задания на понимание — вторую и задания на решение анаграмм — третью шкалу или (например) словарные задания и задания на понимание сформируют одну шкалу, в то время как задачи на решение анаграмм — другую. Однако давайте сначала рассмотрим более простой пример. Предположим, что в интересах науки вы планируете собрать следующие данные у случайно сформированной выборки, например, у 200 знакомых студентов в баре вашего университета или колледжа:
« VI — вес тела (в кг);
• V2 — степень невнятности речи (ранжируется по шкале от 1 До 5);
• V3 — длина ноги (в см);
• V4 — разговорчивость (ранжируется по шкале от 1 до 5);
• V5 — длина руки (в см);
• V6 — степень шатания при попытках пройти по прямой линии (ранжируется по шкале от 1 до 5).
Кажется вероятным, что VI, V3 и V5 будут варьировать совместно, поскольку крупные люди будут склонны иметь длинные
руки и ноги и больше весить. Все эти три пункта измеряют некоторое фундаментальное свойство индивидуумов вашей выборки: их размеры. Точно так же вероятно, что V2, V4 и V6 будут варьировать совместно, так как количество употребленного алкоголя, вероятно, будет связано с четкостью речи, разговорчивостью и с осложнениями при попытках пройти по прямой линии. Таким образом, хотя мы собрали шесть фрагментарных данных, эти переменные измеряют только 2 конструкта: размеры тела и степень опьянения. В факторном анализе вместо слова «конструкт» обычно используется слово «фактор», и далее мы будем следовать этой традиции.
Исследовательский факторный анализ, по существу, выполняет две функции.
• Он показывает, сколько отдельных психологических конструктов (факторов) измеряется данным набором переменных. В приведенном выше примере такими двумя факторами являются размеры тела и степень опьянения.
• Он показывает, какие именно конструкты измеряют использованные переменные. В приведенном выше примере было показано, что VI, V3 и V5 измеряют один фактор и V2, V4 и V6 измеряют другой, совершенно отличный фактор.
В некоторых формах факторного анализа дополнительно можно прокоррелировать факторы между собой, и затем вычислить для каждого испытуемого индивидуальную оценку по каждому фактору в целом («факторные оценки»).
Оценки по полным тестам (а не по его отдельным заданиям) также могут подвергаться факторному анализу — на самом деле именно так эта методика и используется. Факторный анализ в этом случае может показать, действительно ли тесты, которые, предположительно, измеряют один и тот же конструкт (например, шесть тестов, которые претендуют на измерение тревожности), продуцируют один фактор, или же в этом случае будут выделены несколько факторов (указывая на то, что тесты на самом деле измеряют несколько разных характеристик). Факторный анализ оценок, полученных на основе полных тестов, может быть чрезвычайно полезен для установления того, что именно измеряется группой тестов, поскольку многозначность языка допускает, что одному и тому же конструкту разными исследователями могут быть даны различные наименования. «Тревога» у одного автора может обо-
значать то же самое, что «нейротицизм» — у другого или «негативный аффект» — у третьего. Число терминов, используемых в психологии индивидуальных различий, потенциально безгранично, и без факторного анализа нет надежного способа установить, действительно ли несколько шкал измеряют один и тот же базисный психологический феномен. Например, если в издательском каталоге указано, что имеются психологические средства измерения «нейротицизма», «тревоги», «истерии», «силы Эго», «нервозности», «низкой самоактуализации» и «боязливости», кажется разумным задать вопрос: действительно ли это шесть отдельных понятий или это одна и та же характеристика, которой исследователи, имеющие разные теоретические воззрения, дали различные названия? Факторный анализ может точно ответить на этот вопрос, и поэтому он чрезвычайно полезен для упрощения структуры личности и способностей.
Возможности факторного анализа не ограничиваются анализом заданий или оценок теста. Можно факторизовать, например, показатели времени реакции, взятые из когнитивных тестов различного типа, чтобы определить, какие из них (если такие есть) связаны между собой. Возможен и иной подход. Предположим, что группу школьников, которые не имели специальной спортивной подготовки или спортивной практики, оценивали с точки зрения их успешности в соревнованиях по 30 видам спорта с помощью комплекса оценок, включавшего рейтинги тренеров, регистрацию времени, среднюю длину броска, процент отсутствия очков при игре в крикет, забитые голы и любые другие измерения показателей успешности, наиболее подходящие для каждого вида спорта. Единственное условие состоит в том, что каждый ребенок должен участвовать в каждом виде соревнования. Факторный анализ обнаружит много интересных фактов; например, он покажет, будут ли индивидуумы, успешные в одной игре с мячом, демонстрировать тенденцию к успешности во всех остальных играх, будут ли соревнования по бегу на длинные и короткие дистанции образовывать две различные группы (и какой вид соревнования будет входить в какую группу) и т.д. Таким образом, вместо того чтобы обсуждать происходящее в терминах успешности в 30 различных областях, будет возможно суммировать ЭТУ информацию, обсуждая ее в категориях шести основных спортивных способностей (или стольких способностей, сколько выявит факторный анализ).
Изучение исследовательског
факторного анализ
Верхняя часть табл. 14.1 представляет собой опросник, состоящий из шести утверждений. Шестерых студентов попросили ответить на каждое утверждение, используя пятибалльную оценочную шкалу, как показано в таблице, и их ответы даны в нижней части таблицы. Они говорят о степени согласия каждого участника с каждым утверждением.
Упражнение
Посмотрите на ответы студентов, расположенные в нижней части табл. 14.1. Попытайтесь определить, основываясь на этих цифрах, существует ли какая-либо степень совпадения между каждым из шести заданий и, если существует, то укажите между какими из них. На это упражнение отводится около 5 минут.
Первое, что вы можете сделать, — это оценить усредненные ответы по каждому заданию. На основе этого вы можете увидеть, что индивидуумы не склонны соглашаться с утверждением 4, ответы на которое имеют средний ранг 2,16, в то же время большинство индивидуумов обнаруживают тенденцию соглашаться с утверждением 2, среднее значение ответов на которое составляет 3,5. Вы можете таже попробовать проанализировать вариативность оценок, чтобы узнать, образуют ли одни утверждения больший диапазон ответов, чем другие. Однако, как бы ни были интересны эти данные, они в действительности не помогают нам понять характер связей между переменными. Было бы полезно знать, действительно ли шесть утверждений оценивают шесть различных понятий или же они полностью перекрываются, а таблица средних значений этого показать не может.
В главе 11 говорилось, что опросники обычно обрабатываются путем суммирования оценок, полученных индивидуумом по всем входящим в состав опросника утверждениям. Было бы интересно повторить то же самое с данными из табл. 14.1 и вычислить, например, что Стефен по всему опроснику имеет оценку 18 и т.д. Если вы попытаетесь сделать это, вам следует прежде прочесть главу 11 еще раз. Помните, что имеет смысл суммировать оценки индивидуумов только в том случае, если все задания оценивают
Таблица 14.1
Личностный опросник, состоящий из шести заданий, и ответы пяти студентов
Q1 Я получаю удовольствие от общения 1
Q2 Я часто действую импульсивно
Q3 Я веселый человек 4 5
Q4 Я часто ощущаю депрессию
Q5 Мне трудно засыпать по ночам 4 5
Q6 Большие толпы людей вызывают 12345
у меня чувство тревоги
Пожалуйста, обведите кружком одну цифру, которая соответствует вашей реакции на утверждение:
обводите «5», если вы полностью согласны с описывающим вас утверждением;
обводите «4», если оно характеризует вас достаточно хорошо; обводите «3», если не имеете определенной точки зрения или не уверены в том, что это утверждение характеризует вас;
обводите «2», если чувствуете, что утверждение не вполне характеризует вас;
обводите «1», если абсолютно уверены, что это утверждение вас не
характеризует.
| Q1 | Q2 | Q3 | Q4 | Q5 | Q6 | ||
| Стефен | I | ||||||
| Энн | |||||||
| Пол | |||||||
| Джанетт | |||||||
| Майкл | |||||||
| Кристин |
один и то же психологический концепт, а у нас нет никакого представления о том, действительно ли шесть утверждений опросника измеряют одно, два, три, четыре, пять или шесть достаточно разных психологических феноменов. Основная цель данного анализа — как раз ответить на этот вопрос, и потому описанная стратегия также оказывается неподходящей.
Наблюдательные читатели могли заметить некоторые тенденции в этих данных. Вы могли обратить внимание, что ответы индивидуумов на утверждения I, 2 и 3 обнаруживают тенденцию к сходству. Стефен склонен соглашаться со всеми тремя, Энн не
склонна соглашаться с ними, в то время как остальные обнаруживают более или менее нейтральную позицию по отношению к ним. Это, коечно, довольно грубые апроксимации, однако вы можете видеть, что ни один из тех, кто поставил себе ранг 1 или 2 по одному из этих трех вопросов, не присваивает себе ранг 4 или 5 по одному из других. Благодаря этому можно предположить, что удовольствие от общения, импульсивность действий и жизнерадостное отношение демонстрируют тенденцию к группированию и поэтому можно ожидать, что эти три задания образуют шкалу. Тоже самое относится и к заданиям с 4 по 6. Опять такие испытуемые, как Стефен и Энн, которые дают себе низкую оценку по одному из этих трех утверждений, присваивают себе низкий балл и по оставшимся двум утверждениям, в то время как Кристин выставляет себе высокие оценки по всем трем позициям.
Таким образом, оказывается, что в этом опроснике существует два кластера утверждений: первый состоит из утверждений 1, 2 и 3, второй — из утверждений 4, 5 и 6. Однако обнаружение этих связей — очень сложная задача. Если порядок колонок в табл. 14.1 изменить, то эти связи трудно или невозможно будет обнаружить «на глаз».
К счастью, статистическая характеристика, именуемая коэффициентом корреляции, дает возможность определить, действительно ли индивидуумы, имеющие низкие баллы по одной переменной, склонны иметь низкий (или высокий) балл по другим переменным. Краткое описание корреляционных методов дано в приложении А, к котерому следует обратиться в данный момент, если в этом есть необходимость.
В табл. 14.2 представлены корреляции, вычисленные на основе табл. 14.1. (Подробное вычисление этих корреляций не приводится, поскольку работы по статистике, такие, как книга Хауэлла (Howell, 1992), объясняют эту процедуру во всех деталях.) Эти корреляции подтверждают наши предположения, касающиеся взаимосвязей между ответами студентов на утверждения с 1 по 3 и с 4 по 6. Ответы на утверждения с 1 по 3 высоко коррелируют между собой (0,933; 0,824 и 0,696, соответственно) и почти не коррелируют с ответами на вопросы с 4 по 6 (-0,096 и т.д.)- Точно так же ответы на утверждения с 4 по 6 высоко коррелируют между собой (0,896; 0,965 и 0,808, соответственно) и почти не коррелируют с ответами на утверждения с 1 по 3.
Таким образом, корреляции позволяют сделать вывод, что утверждения с 1 по 3 формируют одну естественную группу, а
Таблица 14,2 Корреляции между шестью утверждениями табл. 14.1
| Qi | Q2 | Q3 | Q4 | Q5 Q6 | |
| Q1 | 1,000 | ||||
| Q2 | 0,933 | 1,000 | |||
| Q3 | 0,824 | 0,696 | 1,000 | ||
| Q4 | -0,096 | -0,052 | 0,000 | 1,000 | |
| Q5 | -0,005 | 0,058 | 0,111 | 0,896 | 1,000 |
| Q6 | -0,167 | -0,127 | 0,000 | 0,965 | 0,808 1,000 |
утверждения с 4 по 6 — другую. Это значит, что опросник на самом деле измеряет два конструкта, или «фактора». Один фактор состоит из трех первых утверждений, а другой включает три последних утверждения.
Хотя сказанное довольно легко подтверждается корреляциями, которые мы видим в табл. 14.2, следует помнить, что они едва ли являются типичными. Для этого имеются конкретные причины:
• Данные были сконструированы таким образом, чтобы корреляции между переменными были либо очень большими, либо очень маленькими. В реальной жизни корреляции между переменными редко будут больше 0,5, а многие из них окажутся в диапазоне 0,2-0,3. Из-за этого очень трудно «на глаз» определить, каковы паттерны корреляций.
• Вопросы были расположены в таком порядке, что большие по величине корреляции в табл. 14.2 оказались рядом. Если бы вопросы предъявлялись в другом порядке, выделить кластеры больших корреляций было бы нелегко.
• Использовалось только шесть утверждений, поэтому рассматривалось лишь 15 корреляций. При 40 вопросах пришлось бы
рассматривать 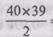 = 780 корреляций, что сделало бы вы-
= 780 корреляций, что сделало бы вы-
деление групп взаимосвязанных утверждений намного более трудным.
Существует несколько других проблем, связанных с проведением факторного анализа «на глаз», одна из которых заключается
в том, что разные люди могут приходить к различным заключениям по поводу числа и природы факторов, поэтому весь процесс является весьма ненаучным.
К счастью, несмотря на это, хорошо известные математические методы могут быть использованы для выявления факторов в группе переменных, обнаруживающих тенденцию к интеркорреляциям, и в настоящее время факторный анализ даже очень большого эмпирического материала можно выполнить на персональном компьютере. Для проведения факторного анализа могут быть использованы несколько статистических компьютерных программ, включая SPSS, BMDP, SYSTAT, Statview и SAS. Чтобы понять, как компьютер может осуществить эту задачу, полезно представить проблему в наглядном виде — геометрически.
Геометрический подход к факторному анализу
Чайлд (Child, 1990) показывает, что можно представить корреляционные матрицы в геометрическом выражении. Переменные изображаются в виде векторов равной длины, берущих начало в одной точке. Эти векторы располагаются таким образом, что корреляции между переменными представляют значения косинусов углов между ними. Косинус угла — это тригонометрическая функция, которую можно либо найти в таблицах, либо вычислить непосредственно с помощью простейшего карманного калькулятора. Вам не нужно знать, что означают косинусы, достаточно знать, где их найти. В табл. 14.3 приводятся несколько значений косинусов углов, что дает общее представление о них. Следует помнить, что в том случае, когда угол между двумя векторами маленький, значение косинуса будет большим и положительным, когда два вектора находятся под прямым углом друг к другу, корреляция (косинус) равна нулю. Когда два вектора направлены в противоположные стороны, корреляция (косинус) будет отрицат тельной.
Это лишь небольшой шаг к пониманию геометрического выражения всей корреляционной матрицы. Вектор проводится на любом месте страницы и представляет одну из переменных, неважно какую именно. Другие переменные изображаются с помощью дру-
Дата добавления: 2015-03-03; просмотров: 1235;