Актуальность технического обслуживания 11 страница
• склонность соглашаться: установлено, что люди склонны соглашаться с утверждениями;
• настроение студента;
• случайная ошибка: если вы зададите студенту тот же самый вопрос двумя минутами позже, можете получить несколько отличающийся ответ.
Ваш список, вероятно, содержит и другие важные переменные. Множество посторонних факторов определяет, каким образом индивидуум будет отвечать на вопрос в личностном тесте, и некоторые из них мы рассмотрим в главе 17. То же самое в значи-
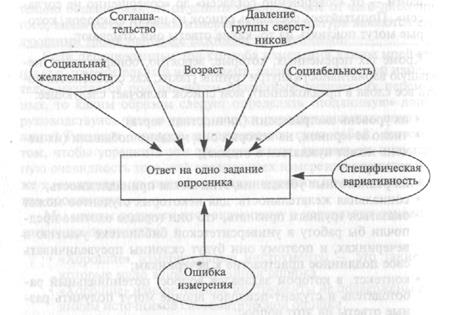
Рис. 13.2. Примеры переменных, которые могут оказывать влияние на ответы человека, получаемые на одно утверждение из личностного опросника.
тельной степени приложимо и к тесту способностей. На успешность здесь могут оказывать влияние не только способности, но и тревога, удача при угадывании правильного ответа, непонимание того, что ожидается, социальное давление (намеренное частичное выполнение теста, чтобы не выделяться из группы), осознаваемая важность получения высокой оценки и т.д. Мы могли бы сделать такое же заключение по поводу оценок поведения (когда особенности личности ранжирующего и его чувствительности будут также влиять на выставляемые ранги). Таким образом, любой фрагмент собранных данных при оценке индивидуальных различий, видимо, подвержен влиянию большого числа факторов, как показано на рис. 13.2.
Можно было бы провести эксперименты, чтобы определить меру влияния каждой из этих переменных на индивидуальный ответ, полученный на каждый вопрос. Если вопрос предназначен для измерения такой черты, как экстраверсия, «хорошим» будет
вопрос, при котором эффекты всех других переменных окажутся малы, аналогично тому как на «хороший» показатель длины влияет расстояние, а не температура, давление воздуха или что-либо еще. В предыдущем примере, касавшемся измерения длины стены, реальная длина стены оказывала решающее влияние на показатели, получаемые с помощью измерительной ленты. К сожалению, в психологии это не так. Почти невозможно найти вопрос личностного теста, для которого диагностируемая черта объясняла бы более чем 20—30% вариативности индивидуальных ответов на вопросы. Большая часть вариативности обязана своим происхождением другим факторам.
Проблема действительно серьезна. Кажется, что сложно или невозможно придумать вопросы, которые измеряли бы черту в чистом виде, поскольку ответы индивидуумов на каждый вопрос теста подвержены влияниям множества черт, состояний, аттитю-дов, настроений и везения. Можем ли мы надеяться, что личность или способности могут быть оценены с какой-либо степенью точности?
К счастью, существует подход к решению этой проблемы. Например, можно привести некоторые другие вопросы, измеряющие экстраверсию, каждый из которых зависит от действия различного набора посторонних факторов. В главе 5 показано, что Ай-зенк считает экстравертов социабельными, оптимистичными, разговорчивыми, импульсивными и т.д., — значит, можно сформулировать вопросы, которые измеряли бы и эти переменные тоже. Вопрос типа «Ведете ли вы себя тихо во время общественных мероприятий?» был бы подвержен влиянию определенного числа посторонних факторов, но лишь некоторые из них оказались бы теми же, что и для первого вопроса. Таким образом, если опрос^ ники конструировались из некоторого количества вопросов, на каждый из которых действует различный набор посторонних факторов, влияние последних будет иметь тенденцию к снижению, в то время как влияние черты будет накапливаться. Следовательно, чтобы разработать более точное измерение личностной черты, необходимо просто:
• написать несколько вопросов, каждый из которых отражает разные аспекты черты и, следовательно, оказывается под воздействием различных наборов посторонних факторов;
• оценить ответы на эти вопросы;
• сложить эти оценки вместе.
Общий (или средний) балл, полученный по опроснику, неизбежно будет лучшей оценкой черты индивидуума, чем ответ на один-единственный вопрос, поскольку посторонние факторы устраняют действие друг друга. Это тот же принцип, о котором говорилось в предыдущем разделе. Там я утверждал, что для получения «наилучшей» оценки длины комнаты по результатам трех измерений, которые слегка различаются (потому что на каждый действует различный набор посторонних факторов), мы должны просто взять среднее значение этих величин. Когда мы поступаем таким образом, 80%, 90% (и даже более) вариативности в общей оценке теста обусловливается личностной чертой, что намного лучше, чем 20 или 30%, которые можно было бы получить с помощью одного отдельно взятого, даже самого хорошего, вопроса. Этот простой принцип составляет основу «теории надежности», которая будет обсуждаться в следующем разделе. Прежде чем закончить этот раздел, необходимо объяснить, что означает термин «специфическая вариативность», который без предупреждения вкрался в рис. 13.2. Остальные стрелки на этом рисунке дают основание предполагать, что ответ индивидуума на этот вопрос может быть полностью охарактеризован в терминах пяти основных параметров (плюс некоторая ошибка измерения, которую мы можем опустить). Однако это не обязательно так. Вполне возможно, что некто, не являющийся экстравертом и не получающий удовольствия от выпивки, и чей ответ не подвержен сильному влиянию любого другого постороннего фактора, может тем не менее просто извлекать удовольствие из «пьяных» вечеринок. Другими словами, может получиться так, что некоторые индивидуумы ответят на этот вопрос полным согласием, даже несмотря на то что такой вариант ответа невозможно предугадать исходя из знания их аттитюдов, личностных черт и прочих обстоятельств из числа «мешающих факторов». Необходимо принимать это в расчет, что и делается с помощью понятия, называемого специфической вариативностью.
Надежность умственных тестов
В предыдущем разделе я показал, что отдельно взятый вопрос теста — плохое средство измерения черты и что значительно лучшую оценку ее выраженности можно получить, если мы сложим
оценки, полученные по некоторому количеству вопросов, измеряющих различные аспекты черты. Представим себе, что для измерения определенной черты разработано около 20 вопросов и они предъявляются приблизительно 200 испытуемым. Пока мы допускаем, что все вопросы измеряют одну и ту же черту, а о том, как проверить это допущение и устранить вопросы, которые измеряют ее плохо, мы будем говорить в главе 18. Специализированные компьютерные программы (такие, как операция оценки «надежности» в SPSS) могут быть использованы, чтобы вычислить по этим данным статистическую характеристику, которую различные авторы упоминают как «надежность» теста, «альфа», «коэффициент альфа», «KR-20», «альфа Кронбаха» или «внутренняя согласованность». Деталей того, как вычисляется эта статистика, мы здесь касаться не будем, но их можно найти в большинстве учебников по психометрике. Как вы можете ожидать исходя из прочитанного в предыдущем разделе, на коэффициент альфа влияют два фактора:
• средняя величина корреляции между вопросами теста. Поскольку мы допустили в предыдущем разделе, что различные задания теста подвержены действию разных посторонних факторов, единственная причина, по которой ответы индивидуумов на любую пару заданий должны коррелировать между собой, состоит в том, что оба вопроса измеряют одну и ту же скрытую черту. Поэтому, если все вопросы теста измеряют одну и ту же черту, корреляции между ними будут высокими и положительными (после обработки);
• количество вопросов в шкале. Снова я указываю на то, что общая цель построения шкалы из нескольких вопросов состоит в том, чтобы попытаться устранить действие посторонних факторов. Видимо, легко понять: чем больше вопросов в шкале, тем более вероятно, что все эти посторонние факторы будут устранены. В этом случае может оказаться полезной формула Спирмена — Брауна (имеющаяся в любом стандартном руководстве по психометрике). Она позволяет предсказать, как будет увеличиваться или уменьшаться надежность шкалы, если число вопросов в шкале меняется.
Следует помнить, что надежность теста — это просто статистическая характеристика, которая может быть вычислена на основе любого набора данных (при условии, что выборка составляет не менее 200 испытуемых). Помните также, что ее максимально воз-
20-989
Таблица 13.2 Корреляции между пятью гипотетическими вопросами теста
| Вопрос 1 | Вопрос 2 | Вопрос 3 | Вопрос 4 | Вопрос 5 | |
| Вопрос 1 | 1,0 | ||||
| Вопрос 2 | -0,02 | 1,0 | |||
| Вопрос 3 | 0,10 | 0,28 | 1,0 | ||
| Вопрос 4 | 0,15 | 0,31 . | 0,24 | 1,0 | |
| Вопрос 5 | 0,12 | 0,25 | 0,27 | 0,36 | 1,0 |
можное значение составляет 1,0 (ее минимальное значение может при определенных обстоятельствах быть меньше 0). Это в высшей степени важно. Для больших тестов квадратный корень из коэффициента альфа представляет очень близкую апроксимацию к корреляции между оценками индивидуумов по определенному интеллектуальному тесту и подлинной оценкой их черты (Nunnally, 1978). Так, коэффициент альфа, равный 0,7, предполагает корреляцию
д/OJ или 0,84, между оценками, полученными по тесту, и подлинными оценками испытуемых, в то время как величина коэффициента альфа, равная 0,9, подразумевает, что корреляция достигает такого высокого значения, как 0,95. Поскольку основная цель использования психологических тестов — попытаться достичь максимально возможного приближения к подлинной оценке черты личности, из этого следует, что тесты должны иметь высокое значение коэффициента альфа.
Широко распространенное эмпирическое правило указывает на то, что тест не должен использоваться, если он имеет коэффициент альфа ниже 0,7, а применять его при принятии важных решений по поводу конкретного индивидуума (например, для оценки необходимости коррекционного обучения) можно только в том случае, если величина коэффициента альфа больше 0,9.
Задание для самопроверки 13-1
Тест из пяти вопросов, измеряющий экстраверсию, предъявляли большой выборке испытуемых. Были вычислены корреляции между ответами на его вопросы. Они представлены в табл. 13.2. (а) Что показывает корреляция между любой парой ответов на вопросы теста?
(б) Какой вопрос оказывается наименее эффективным в измерении экстраверсии?
(в) Представьте себе, что вы подсчитали величину коэффициента альфа по корреляциям, показанным в табл. 13.2, и нашли, что эта величина ниже 0,7. Что вы можете предпринять?
Вышеизложенное кажется достаточно простым, но мы еще ничего не сказали о содержании заданий теста. Проблема заключается в том, что довольно легко повысить среднюю корреляцию между заданиями теста, задавая несколько раз, по существу, один и тот же вопрос, слегка перефразируя его в каждом случае. Благодаря этому все посторонние факторы, которые влияют на первый вопрос, будут влиять и на второй. Поскольку оба вопроса имеют отношение к одному и тому же поведению, они будут также разделять большую часть своей специфической вариативности. Поэтому можно ожидать, что корреляция между двумя утверждениями будет близка к 1,0. Примерами двух таких утверждений могут быть: «Я получаю удовольствие от вечеринок» и «Я получаю удовольствие от «тусовок»». Поскольку эти два задания, по сути, задают один и тот же вопрос, трудно представить себе, что многие люди могли бы полностью согласиться с одним и столь же решительно не согласиться с другим. Ответы на эти два вопроса обязаны иметь высокую положительную корреляцию. При условии, что корреляции между заданиями теста обычно невелики (в лучшем случае порядка 0,2-0,3), корреляция 0,9, полученная в результате сопоставления двух фактически идентичных утверждений, будучи включена в таблицу, существенно увеличит среднюю корреляцию. В примере, приведенном в табл. 13.2, изменение корреляций между вопросом 1 и вопросом 2 с -0,02 до 0,9 увеличит среднюю корреляцию с 0,206 до 0,298. В результате этого произойдет значительное увеличение коэффициента альфа. Однако должно быть ясно, что мы нарушили два главных условия: каждый вопрос будет подвержен влиянию различного набора посторонних факторов и каждый будет иметь свою собственную «уникальную» вариативность, которая не разделяется другими вопросами.
Крайне важно убедиться, что задания в каждой шкале хорошо подобраны. В некоторых случаях сделать это несложно. Например, в случае словарного теста просто необходимо подбирать задания из словаря (может быть, исключая те слова, которые встречаются ниже определенного порога частотности, или слова грубые, архаичные, специальные, т.е. профессиональные, термины). Когда это
сделано, единственное, что будет влиять на корреляцию между ответами на пару заданий, — степень, с которой каждое из них измеряет скрытую черту (грамотность), — принцип, иногда определяемый как «локальная независимость». Не существует магической формулы для автоматической реализации этого принципа при конструировании тестов. От человека, пишущего задания, зависит гарантия того, что единственной причиной, объясняющей корреляцию ответов на любую пару заданий, является та скрытая черта личности или способностей, которую они оба должны измерять. К сожалению, некоторые подходы к конструированию тестов, например, те, в защиту которых выступают Коста и МакКрей (Costa, McCrae, 1992a), в конечном счете обязательно приведут к появлению большого количества искусственно завышенных корреляций, что даст, в свою очередь, завышенную оценку коэффициента альфа. Купер (Cooper, в печати) приводит некоторые рассуждения по поводу того, как значимость этой проблемы может быть оценена в системе существующих диагностических шкал.
Важно также обеспечить, чтобы выборка испытуемых, чьи тестовые оценки используются для вычисления коэффициента альфа, была репрезентативна группе, в которой будет применяться данный тест. Бессмысленно, установив его величину в размере 0,9 на выборке студентов университета, затем считать, что этот тест будет годиться для использования на общей популяции, поскольку студенты университета — это не случайная выборка: они молоды, академически одаренны, принадлежат к среднему классу, грамотны и умеют вычислять. Еще раз подчеркнем, что не существует количественного способа определить, будет ли тест, имеющий высокое значение коэффициента альфа на одной выборке, так же работать на другой, — это дело здравого смысла. Я бы с большой осторожностью относился к допущению, что личностный тест, который был разработан с участием американских студентов колледжа, будет работать на общей популяции Великобритании (и соответственно, наоборот), но не все разделяют эти опасения. Самое безопасное — вычислять коэффициент альфа во всех случаях использования теста, хотя в качестве предварительного условия обязательным будет тестирование большей выборки испытуемых (Нанелли рекомендует минимум 200 человек).
При использовании должным образом коэффициент альфа очень полезен. Любой тест можно рассматривать как комплекс заданий, выбранных из большого набора вопросов, которые потенциально могли быть заданы. Например, тест на правописание — это выбор-
ка слов из словаря. Тест, измеряющий тревогу, — это набор всех (многих!) вопросов, которые можно было бы перечислить с целью измерения множества аспектов тревоги. Тест математических способностей — это выборка из почти бесконечного числа математических заданий, которые только можно было бы написать.
Ранее я использовал понятие «подлинная оценка», но не определил его значение. Подлинное значение черты индивидуума — это оценка, которую он получил бы, если бы ему предъявили каждое возможное задание из полного набора. Если бы вы оценили чью-либо способность правильно писать каждое слово из словаря, -то узнали бы точно, каковы способности этого человека к правописанию, поскольку отсутствовала бы ошибка измерения, обусловленная случайным выбором заданий. Однако в тесте мы берем лишь небольшую выборку заданий из возможного набора и объединяем их вместе. Если (и только если) задания теста формируют репрезентативную выборку по отношению к полному набору заданий, квадратный корень из коэффициента альфа довольно точно оценивает корреляцию между оценкой, полученной испытуемыми при выполнении теста, и их подлинной оценкой (т.е. оценкой, которую они могли бы получить, если бы им были предъявлены все задания до полного исчерпания набора).
Чем выше величина коэффициента альфа, тем меньше будет ошибка при измерении черты, и, зная надежность теста и стандартные отклонения тестовых оценок, можно извлечь статистическую характеристику, которая называется «стандартная ошибка измерения» («standard-error of measurement» (SEM)). Она показывает, насколько ошибка измерения может быть связана с каждым измерением. Можно установить, что если оценка человека по тесту равна 35, то с 99%-ной вероятностью можно полагать, что подлинная оценка находится где-то между 30 и 38*.
Формула для вычисления стандартной ошибки такова:
где SD — стандартное отклонение тестовых оценок. Таким образом, тест со стандартным отклонением 1,0 и надежностью 0,7 бу-
* Если вам захочется сделать это на практике, я вам очень советую перед этим проконсультироваться с книгой Нанелли (Nunnally, 1978, р. 241). Процедуры, описанные в большинстве руководств по использованию тестов (даже таких широко используемых, как WISC-III) и во многих учебниках по психометрике, неправильны.
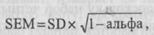
дет иметь стандартную ошибку 5,4. Если бы его надежность была равна 0,9, то стандартная ошибка измерения упала бы до 3,1. Таким образом, знание надежности теста позволяет делать некоторые интересные заключения, касающиеся величины ошибки, которая, вероятно, имеется в любом измерении, при условии, конечно, что задания данного теста можно считать репрезентативными по отношению к полному набору заданий.
Задание для самопроверки 13.2
(а) Что такое KR-20 и альфа Кронбаха?
(б) Почему при разработке опросника нецелесообразно перефразировать одно и то же задание несколько раз?
(в) О чем говорит стандартная ошибка измерения?
(г) Представьте себе, что мы имеем два теста, которые ставят своей целью измерение тревоги. Тест 1 имеет надежность 0,81, а тест 2 имеет надежность 0,56. Какой будет корреляция между каждым из этих тестов и подлинной оцеукой? Какой будет самая большая корреляция, которую вы, вероятно, получите, если будете коррелировать оценки индивидуумов, полученные по тесту 1, с их же оценками, полученными по тесту 2?
Другие подходы
к измерению надежности
До появления компьютеров вычислять коэффициент альфа вручную было утомительно, поэтому использовалась апроксимация. Вместо сложения всех заданий теста для получения общей оценки вычислялись две оценки: одна основывалась на всех нечетных заданиях теста, а другая — на всех четных. Полученные две оценки затем коррелировали между собой, и после применения формулы Спирмена—Брауна (поскольку набор четных или нечетных заданий — только половина объема полного теста) это давало надежность, полученную методом расцепления. В настоящее время, по-видимому, нет весомых оснований для ее использования.
Ретестовая надежность, иногда известная как временная стабильность, имеет совершенно другой смысл. Как следует из названия, она проверяет, в какой степени оценки черты остаются более или менее постоянными в течение времени. Большинство тестов разработано для измерения таких черт, как экстраверсия,
способности к вычислениям или нейротицизм, а в определении черты подчеркивается, что это относительно устойчивая диспозиция. Последнее предполагает, что индивидуумы должны иметь похожие оценки, 'когда они тестируются в двух ситуациях (например, с интервалом в несколько недель) при условии, что:
• с ними не случилось ничего значительного в интервале между двумя тестированиями (например, не было эмоционального кризиса, изменений, обусловленных развитием, или значительного образовательного опыта, который мог бы повлиять на черту);
• тест хорошо измеряет черту.
Если при первом тестировании тест показывает, что ребенок гениален, а через месяц его интеллект оказывается на среднем уровне, то либо концепция интеллекта характеризует в большей степени состояние, а не черту, либо тест несостоятелен.
Оценка ретестовой надежности обычно включает двукратное тестирование одной и той же группы людей с интервалом по крайней мере в один месяц (чтобы минимизировать вероятность того, что испытуемые запомнят свои предыдущие ответы), но все же не слишком большим (иначе изменения, обусловленные развитием, обучением или другими жизненными событиями, могут изменить позиции индивидов по данной черте). Ретестовая надежность -это просто корреляция между двумя наборами оценок. Если она высока (означая тем самым, что индивидуумы имеют сходные уровни по черте g обоих случаях), то можно утверждать, что черта стабильна и тест, вероятно, является хорошим средством измерения черты.
Проблема, разумеется, заключается в том, что ретестовая надежность основывается на общей оценке, она ничего не говорит о том, как люди выполняют отдельные задания. В то время как коэффициент альфа показывает, измеряет ли набор заданий некоторую конкретную скрытую черту, прекрасную ретестовую надежность может иметь набор заданий, которые не имеют ничего общего между собой. Например, если вы попросили кого-то суммировать номер своего дома, размер обуви и год рождения в двух разных ситуациях, полученная статистическая характеристика будет обнаруживать впечатляющую ретестовую надежность, хотя эти три пункта не имеют между собой ничего общего.
Ради полноты картины теперь следует упомянуть надежность параллельных форм. Конструкторы тестов иногда создают из набо-
pa заданий несколько тестов. Чтобы создать две параллельные формы теста, задания предъявляются большой выборке испытуемых и подбираются пары заданий со сходным содержанием и уровнем трудности. Например, обе формы теста могут включать задание решить анаграмму из семи букв, и в обоих случаях ответом будут слова, одинаково часто встречающиеся в языке, и только около 25% выборки будут способны решить каждую из них. Одно задание будет затем включено в форму А теста, а другое — в форму Б. Эти два теста продаются отдельно, и (теоретически) несущественно, какой из них будет использоваться в определенных целях, поскольку обычно предпринимаются специальные усилия, гарантирующие, что эти две версии дают одинаковое распределение оценок (и благодаря этому позволяют использовать одни и те же таблицы норм для обеих форм теста). Если оба теста измеряют одну и ту же черту, следует ожидать высокой положительной корреляции между оценками индивидуумов по двум формам теста. Эта корреляция известна как надежность параллельных форм. Однако, поскольку параллельные формы имеют относительно немногие тесты, она используется редко.
Теория генерализованности (Cronbach et al., 1972) — другой подход к теории надежности. Хорошее объяснение можно найти в работе Кронбаха (Cronbach, 1994). Эта теория, в сущности, требует от исследователей соблюдать высокую точность по отношению к тем заключениям, которые могут быть сделаны на основе набора тестовых оценок. Она пытается идентифицировать все возможные источники ошибок, которые могут возникнуть при оценивании, в значительной степени так же, как это было показано для отдельных заданий теста в предыдущем разделе. Она стремится оценить каждый из них независимо и внести поправку в оценку каждого индивидуума с учетом влияний этих посторонних факторов. Представим себе, что дети выполнили тест на правописание в двух ситуациях; данные, полученные в двух тестированиях, могут быть проанализированы многими способами. Например, можно оценить временную стабильность теста на правописание, определить, насколько стабильно дети выполняют буквенный анализ слова, или составить диаграмму, оценивающую рост успехов класса в правописании. Проблема заключается в том, что определение (и измерение) всех этих переменных — очень запутанная и громоздкая процедура, и, поскольку важность переменных будет, вероятно, меняться при переходе от одной выборки к другой (пенсионеры
могут прилагать меньше усилий для выполнения тестов способностей, чем студенты, например), это до сих пор не имеет большого практического применения.
Проверка валидности
• -••.' *
Мы видели, что теория надежности может доказать, измеряет или нет набор тестовых заданий некоторую скрытую черту. Однако она не в состоянии пролить какой-либо свет на сущность черты. То обстоятельство, что исследователь думает, будто набор заданий должен измерять определенную черту, не дает гарантии того, что измеряется действительно эта черта. В начале 1960-х гг. много публикаций было посвящено шкале репрессии—сенситизации (R—S). Эта шкала была предназначена измерять степень, с которой индивидуумы использовали «перцептивную защиту», другими словами, оценивать склонность к менее осознанному восприятию эмоционально угрожающих фраз по сравнению с нейтральными фразами при предъявлении и тех и других на очень короткое время. Задания образовывали вполне надежную шкалу, поэтому все просто признавали, что эта шкала измеряла то, что она должна была измерить. На ее основе было проведено очень большое количество исследований. Затем Джой (Joy, 1963; цит. no: Kline, 1981) установил, что оценки, полученные по этому тесту, обнаруживали корреляцию —0,91 с хорошо обоснованным тестом социальной желательности. Максимальная корреляция между двумя тестами ограничена величиной их надежности, поэтому корреляция —0,91 в действительности подразумевает, что вся вариативность шкалы репрессии—сензитизации могла объясняться социальной желательностью. Она не измеряла ничего нового вообще.
В этой истории содержится важное положение. Даже если набор заданий, по-видимому, образует целостную шкалу, невозможно сказать, что именно она измеряет, просто просмотрев задания. Необходимо эмпирически определить, что именно измеряет шкала, с помощью процедуры, известной как валидизация теста.
Говорят, что тест валиден, если он измеряет то, что он должен измерить либо в теоретических понятиях, либо в практическом приложении. Например, тест, который предлагается использовать как средство измерения тревожности в общей популяции Великобритании, должен измерять тревожность, а не социальную
желательность, навыки чтения, социабельность или какую-либо другую не связанную с ней черту. Тест, использующийся для профотбора соискателей, которые будут с наибольшей вероятностью успешны в определенной деятельности, должен быть способен выявить индивидуума (индивидуумов), который будет работать лучше других. Однако, если надежность теста может быть выражена определенным числом (для конкретной выборки испытуемых), валидность теста также зависит и от целей тестирования. Например, тест, валидный для отбора компьютерных программистов из выборки студентов Великобритании, может оказаться бесполезным для отбора администраторов в сфере торговли. Тест, валидный для измерения депрессии при использовании его медицинскими работниками, скорее всего не будет валиден при общем обследовании нанимающихся на работу соискателей, поскольку большинство из них будут понимать цель теста и искажать свои ответы.
Из этого следет, что надежность является необходимым условием валидности теста, поскольку низкая надежность подразумевает, что тест не измеряет одну конкретную черту. Однако высокая надежность сама по себе не гарантирует валидность теста, поскольку, как показано выше, это зависит полностью от того, как, почему и на ком используется тест.
Существует четыре главных способа установления валидности теста.
Очевидная валидность
Очевидная валидность просто оценивает, насколько тест внешне соответствует тому, для чего он предназначался. Описанное выше ниспровержение шкалы R—S показывает, что даже внимательное изучение содержания заданий не дает гарантий того, что тест будет измерять именно предполагавшуюся черту. Несмотря на это, некоторые широко распространенные тесты (особенно в социальной психологии) конструируются путем формулирования нескольких заданий, обеспечения достаточной величины коэффициента альфа (что обычно не создает проблем, потому что задания перефразируют одно другое), а также наивного полагания, что шкала измеряет то понятие, для оценки которого она предназначалась. Принципиально важно до использования теста обеспечить ему лучшие, чем эти, основания.
Содержательная валидность
Иногда можно сконструировать тест, который должен быть валиден, по определению. Например, представьте себе, что кто-то захотел сконструировать тест на правописание. Поскольку, по определению, словарь содержит полный набор заданий, любая процедура, обеспечивающая репрезентативную выборку слов из словаря, должна быть валидным тестом способности к правописанию. Именно это и означает валидность по содержанию. Приведем другой пример: психологи, специализирующиеся на отборе кадров, в некоторых случаях используют особые подходы, условно обозначаемые как «рабочая корзина», когда соискателям предлагают выполнить ряд работ, которые относятся к сфере профессиональной деятельности, а затем тем или иным способом оценивается их успешность по этим заданиям. Эти эксперименты не являются психологическими тестами в прямом смысле слова, но можно согласиться с тем, что эта процедура имеет содержательную валидность. Проблема заключается в том, что редко удается достаточно точно определить полный набор потенциальных заданий теста. Например, каким образом следовало бы определить задания, которые нужно включить в тест способности к вычислениям? В результате этого данная методика используется не слишком часто.
Дата добавления: 2015-03-03; просмотров: 1291;