Поиск на основе преобразования ключа в адрес
Идея данных методов поиска состоит в том, чтобы по аргументу поиска определить адрес соответствующей записи и получить эту запись за одно считывание данных.
Простейшей реализацией этой идеи является использование аргумента, эквивалентного адресу. Например, на каждой квитанции по квартплате может быть указан адрес записи в файле, соответствующей данному абоненту. Физический адрес вводится в ЭВМ и по нему считываются необходимые данные.
Примерно такой же простотой и быстротой характеризуется поиск, основанный на определенной регулярности возможных значений ключей. Например, если в файле успеваемости студентов в качестве ключей использовать последовательность NMP, то адрес записи с информацией об успеваемости студента с номером N в месяце M по предмету с номером P может вычисляться по формуле (N-1)∙35∙12∙L + (M-1)∙12∙L + (P-1)∙L + 1, где L – длина записей в файле.
Рассмотренные способы основаны на учете конкретных закономерностей значений ключей, поэтому они носят ограниченный характер. Во многих задачах поиска нежелательно или недопустимо накладывать какие-либо ограничения на возможные значения ключей. Так, в предыдущем примере может потребоваться искать записи по фамилиям студентов, а не по их порядковым номерам. В этом случае нет практически никакой регулярности в возможных значениях ключей и вышеуказанные методы неприемлемы.
Строку символов, составляющих ключ, всегда можно взаимно однозначно преобразовать в целое число. Например, ее можно рассматривать как запись числа в системе счисления с основанием, равным размеру алфавита. Так, для русского алфавита А=0, Б=1, В=2, …, Ю=31, Я=32 и фамилия «ДЕЕВ» будет преобразована в число 4∙333 + 5∙332 + 5∙331 + 4∙330 = 149362. Однако и после такого преобразования значения ключей не приобретут регулярности.
Перемешивание
Простым и в то же время универсальным методом поиска, основанным на преобразовании аргумента в адрес, является так называемое перемешивание. Этот метод называется также хешированием (кешированием) или рандомизацией.
Идея данного метода заключается в том, что записи размещаются в ячейках памяти, адреса которых получены преобразованием ключей в псевдослучайные числа из диапазона возможных значений адресов.
Пусть, например, таблицу поиска составляют записи с данными о 31 студенте группы и в качестве ключей выступают фамилии студентов. Воспользовавшись тем, что дни рождения более или менее равномерно распределены в диапазоне от 1 до 31, будем в качестве адреса использовать день рождения студента. В этом случае может быть получена таблица адресов, приведенная на рис. 2.3.
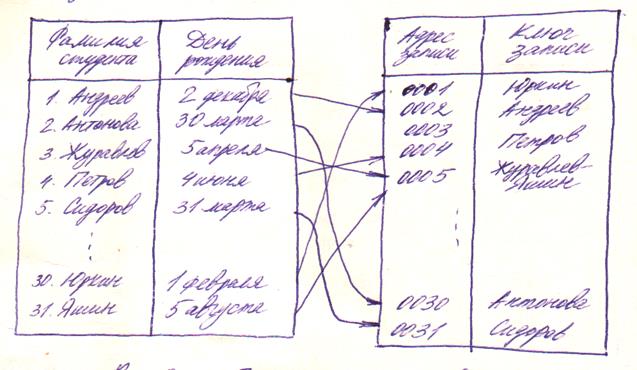
Рис.2.3
Пример использования перемешивания
Теперь, если требуется найти в таблице сведения о каком-либо студенте группы, то его фамилию (аргумент поиска) нужно «преобразовать» в день рождения (адрес), по которому обратиться к соответствующей ячейке памяти.
В приведенном примере отражены две существенные проблемы перемешивания:
1) как найти преобразование значений аргумента в целые числа из заданного диапазона, при котором числа были бы распределены в диапазоне достаточно равномерно?
2) как поступать в тех случаях, когда двум различным аргументам в результате преобразования присваиваются одинаковые значения адресов и возникает так называемая коллизия?
Для преобразования аргумента в адрес, которое называется функцией перемешивания или хеш-функцией, предложено много алгоритмов, идеи которых в большинстве случаев связаны с методами формирования на ЭВМ псевдослучайных чисел. Процедура получения хеш-адресов выполняется обычно в три этапа:
1. Перевод аргумента (если он не числовой) во взаимно однозначное числовое представление.
2. Преобразование числового представления аргумента в псевдослучайное число, имеющее тот же порядок, что и значения адресов памяти.
3. Нормирование полученного числа для того, чтобы оно строго укладывалось в диапазоне значений адресов памяти.
Следует особо отметить, что псевдослучайный, а не чисто случайный характер получаемых хеш-адресов имеет принципиальное значение. Функция перемешивания должна быть строго детерминированной, так как она используется как при начальном заполнении таблицы или файла, так и при последующем поиске (в обоих случаях по одному значению аргумента должен получаться один и тот же хеш-адрес).
Наиболее распространенная функция перемешивания основана на методе деления. Аргумент в числовом представлении делится на число, равное или близкое к числу записей в таблице. Остаток от деления дает относительный хеш-адрес. Данный метод при всей его простоте обеспечивает достаточно равномерное рассеивание хеш-адресов при заполнении таблицы. Для лучшей равномерности перемешивания делитель должен быть нечетным числом, не должен выражаться степенью основания, по которому ключи переводятся в числовую форму, по мере возможности это должно быть простое число. Например, если число адресов равно 7000, то в качестве делителя подходит число 6997. Пусть числовая форма ключа равна 149362 (строка «ДЕЕВ»), тогда остаток от деления ее на число 6997 равен 2425. Поэтому запись с ключом «ДЕЕВ» при заполнении таблицы направляется в ячейку с адресом 2425, а при поиске извлекается из той же ячейки.
Проблема коллизий решается достаточно просто: при заполнении таблицы для записи, претендующей на уже занятую ячейку, отводится место, расположение которого легко установить, зная адрес коллизии. Простейший прием состоит во введении ячеек переполнения и указании в точках коллизии ссылок на эти ячейки (метод ячеек переполнения). Другой прием заключается в просмотре последовательности ячеек, следующих за вычисленным хеш-адресом, до тех пор, пока не будет обнаружена свободная (метод внутренней адресации).
В любом случае при наличии одной или нескольких ячеек с одинаковыми адресами необходимо иметь возможность идентифицировать по ключам попавшие туда записи, поскольку неизвестно, каким образом эти записи распределены по ячейкам памяти. Обычно для этого вместе с данными записывается ключ соответствующей записи, а на этапе поиска он сравнивается с аргументом поиска.
Возможность коллизий приводит к тому, что не всегда нужная запись находится за одно считывание данных из памяти. При возникновении коллизии, возможно, потребуется два, три или даже более считываний данных – так называемых опробований, пока не будет найдена требуемая запись или не выяснится, что данная запись отсутствует. Другой особенностью данного метода организации поиска является наличие пустых мест в таблице. Дело в том, что чем плотнее заполнена таблица, тем больше вероятность коллизии и, следовательно, больше опробований нужно совершить, чтобы найти нужную запись. Поэтому для сокращения времени поиска целесообразно не заполнять таблицу до конца (на практике плотность заполнения таблицы обычно не более 80-90%).
Во многих случаях методом перемешивания удобно определять адреса не отдельных ячеек, а групп из установленного числа ячеек – участков. По мере заполнения памяти записи помещаются в свободные ячейки участка с вычисленным хеш-адресом. При поиске определяется хеш-адрес участка и далее перебираются записи в участке до тех пор, пока не будет найдена та из них, ключ которой совпадает с аргументом поиска.
Дата добавления: 2017-11-04; просмотров: 728;