Проблема поиска данных
С проблемой кодирования данных, передаваемых по каналу связи, тесно связаны проблемы их хранения в запоминающих устройствах (ЗУ) и поиска необходимых данных по специальному запросу. Действительно, чтобы исходному сообщению поставить в соответствие определенное кодовое слово, это слово часто нужно найти в некотором ЗУ. Приняв кодовое слово, также бывает необходимо найти в ЗУ данные, соответствующие исходному сообщению. С другой стороны, сложные системы поиска (например, в СУБД) в процессе своего функционирования используют большое число процедур кодирования и декодирования информации.
При рассмотрении задач поиска будем предполагать, что данные находятся в ЗУ в виде записей, каждая из которых содержит специальное поле, называемое ключом. Обычно требуется, чтобы ключи были различными и чтобы каждый ключ однозначно определял свою запись. Совокупность записей образует таблицу или файл, размещаемый в запоминающем устройстве.
Поиск обычно начинается с получения извне аргумента поиска и состоит в отыскании записи, ключ которой совпадает с аргументом поиска или находится с ним в определенном соотношении. Существуют две возможности окончания поиска: либо поиск оказался удачным, т.е. позволил найти нужную запись, либо неудачным, т.е. показал, что записи с данным ключом в таблице отсутствуют.
Хотя целью поиска являются данные, содержащиеся в некоторой записи, их извлечение, когда запись найдена, принципиальных затруднений не вызывает. Поэтому для простоты можно считать, что записи состоят только из ключей.
Конкретные процедуры поиска и их эффективность во многом определяются теми возможностями, которые предоставляют различные виды запоминающих устройств. Поэтому изучение методов поиска целесообразно начать с рассмотрения важнейших разновидностей ЗУ.
Виды ЗУ
С точки зрения поиска данных большинство известных запоминающих устройств можно отнести к одному из трех видов: последовательные, адресные и ассоциативные.
Последовательные ЗУ при каждом считывании предоставляют во внешнюю среду очередную запись таблицы или файла. Чтобы получить в распоряжение некоторую i-ю запись таблицы, нужно прежде произвести считывание предыдущих (i-1) записей. Последовательный доступ к данным реализуют такие технические устройства, как накопитель на магнитной ленте, автомат магазинной памяти и т.п.
Адресные ЗУ при каждом считывании предоставляют запись, находящуюся в ячейке, адрес которой указан на входе устройства. Чтобы получить некоторую i-ю запись таблицы, нужно на входе ЗУ указать адрес (номер) ячейки, в которой размещена эта запись. На рис. 2.1 представлена схема адресного ЗУ.
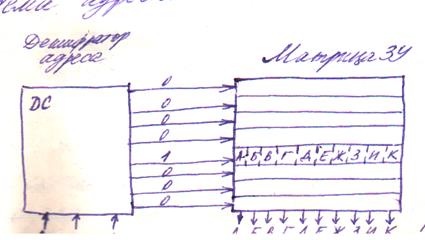
Рис.2.2
Схема адресного ЗУ
Адресное ЗУ состоит из двух частей: дешифратора адреса и матрицы ЗУ. Записи хранятся в строках матрицы ЗУ. Двоичный код адреса записи поступает на вход дешифратора адреса, который преобразует его в унитарный код с числом разрядов, равным количеству строк в матрице ЗУ. Логическая единица появляется на выходе дешифратора, номер которого соответствует двоичному коду адреса. Под действием сигнала логической единицы содержимое соответствующей строки матрицы ЗУ выводится на выход устройства. В качестве адресных ЗУ выступают такие технические устройства, как оперативное и постоянные запоминающие устройства ЭВМ, накопители на магнитных, оптических дисках и т.п.
Ассоциативные ЗУ при каждом считывании выдают на выходе запись, содержимое определенного поля которой совпадает со значением ключевого слова, поданного на вход устройства. Чтобы получить в распоряжение i-ю запись таблицы, нужно на вход ЗУ подать кодовое слово, соответствующее ключевому слову i-й записи. На рис. 2.2 приведена схема ассоциативного ЗУ.
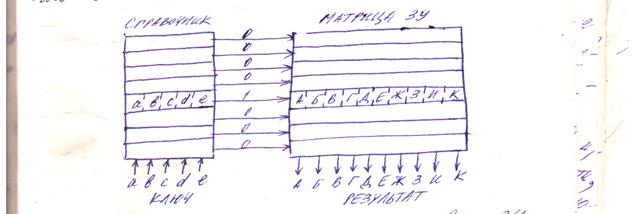
Рис.2.2
Схема ассоциативного ЗУ
Ассоциативное ЗУ состоит из справочника и матрицы ЗУ. В строках матрицы ЗУ хранятся записи. Каждая ячейка справочника представляет собой регистр, рассчитанный на хранение одного ключевого слова соответствующей записи матрицы ЗУ. Он дополнен специальными комбинационными логическими схемами, предназначенными для сравнения содержимого регистра с ключевым словом, поступающим одновременно на вход всех ячеек. Выходные шины справочника выполняют функцию адресных линий, следовательно, необходимость в дешифраторе адреса отпадает. В качестве ассоциативных ЗУ выступают технические устройства, называемые памятью с адресацией по содержанию, файлом с параллельным поиском, ассоциативным процессором и т.п.
Из запоминающих устройств всех видов ассоциативные ЗУ непосредственно решают задачу поиска: подавая на вход ассоциативного ЗУ аргумент поиска, на выходе сразу получаем запись, ключ которой совпадает с аргументом. Однако ассоциативные ЗУ являются также наиболее дорогими и сложными технически, поэтому в настоящее время задачи поиска обычно приходится решать на основе адресного или последовательного ЗУ.
Адресное ЗУ позволяет легко получить запись, зная ее порядковый номер в таблице. Следовательно, чтобы решить задачу поиска, нужно от аргумента поиска перейти к номеру записи в таблице. Для этого перехода требуется осуществить либо некоторую процедуру преобразования аргумента в адрес, либо некоторую процедуру проверки содержимого последовательности записей. В последовательных ЗУ поиск строится на основе просмотра содержимого записей.
Далее будут рассмотрены методы поиска, ориентированные, в основном, на адресные ЗУ. При этом, отвлекаясь от конкретных способов задания адресов в различных ЭВМ и системах программирования, будем считать, что имеется возможность получить значение ключа записи по ее номеру в файле или таблице.
Методы поиска можно разделить на два класса:
поиск, основанный на преобразовании аргумента в адрес;
поиск, основанный на сравнении ключей.
Рассмотрим оба этих класса.
Дата добавления: 2017-11-04; просмотров: 593;