Коэффициент корреляции, коэффициент детерминации, корреляционное отношение
Для трактовки линейной связи между двумя переменными акцентируют внимание на коэффициенте корреляции.
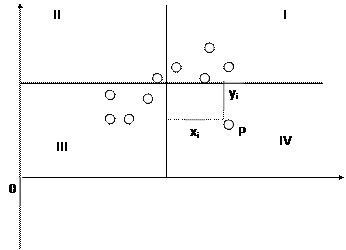
Пусть имеется выборка наблюдений (Xi, Yi), i=1,...,n, которая представлена на диаграмме рассеяния, именуемой также полем корреляции (рис. 2.3).
Y
 |
X
Рис. 2.3. Диаграмма рассеяния
Разобьем диаграмму на четыре квадранта так, что для любой точки P(Xi, Yi) будут определены отклонения 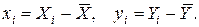
Ясно, что для всех точек I квадранта xiyi>0; для всех точек II квадранта xiyi<0; для всех точек III квадранта xiyi>0; для всех точек IV квадранта xiyi<0. Следовательно, величина åxiyi может служить мерой зависимости между переменными X и Y. Если большая часть точек лежит в первом и третьем квадрантах, то åxiyi>0 и зависимость положительная, если большая часть точек лежит во втором и четвертом квадрантах, то åxiyi<0 и зависимость отрицательная. Наконец, если точки рассеиваются по всем четырем квадрантам åxiyi близка к нулю и между X и Y связи нет.
Указанная мера зависимости изменяется при выборе единиц измерения переменных X и Y. Выразив åxiyi в единицах среднеквадратических отклонений, получим после усреднения выборочный коэффициент корреляции:
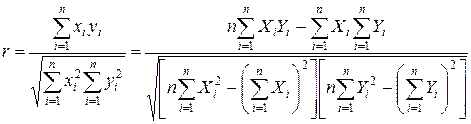 (2.9)
(2.9)
Из последнего выражения можно после преобразований получить следующую формулу для квадрата коэффициента корреляции:
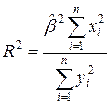 или
или
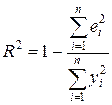 (2.10)
(2.10)
Квадрат коэффициента корреляции называется коэффициентом детерминации. Согласно (2.10) значение коэффициента детерминации не может быть больше единицы, причем это максимальное значение будет достигнуто при 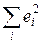 =0, т.е. когда все точки диаграммы рассеяния лежат в точности на прямой. Следовательно, значения коэффициента корреляции лежат в числовом промежутке от -1 до +1.
=0, т.е. когда все точки диаграммы рассеяния лежат в точности на прямой. Следовательно, значения коэффициента корреляции лежат в числовом промежутке от -1 до +1.
Кроме того, из (2.10) следует, что коэффициент детерминации равен доле дисперсии Y (знаменатель формулы), объясненной линейной зависимостью от X (числитель формулы). Это обстоятельство позволяет использовать R2 как обобщенную меру "качества" статистического подбора модели (2.6). Чем лучше регрессия соответствует наблюдениям, тем меньше и тем ближе R2 к 1, и наоборот, чем "хуже" подгонка линии регрессии к данным, тем ближе значение R2 к 0.
Поскольку коэффициент корреляции симметричен относительно X и Y, то есть rXY=rYX, то можно говорить о корреляции как о мере взаимозависимости переменных. Однако из того, что значения этого коэффициента близки по модулю к единице, нельзя сделать ни один из следующих выводов: Y является причиной X; X является причиной Y; X и Y совместно зависят от какой-то третьей переменной. Величина r ничего не говорит о причинно-следственных связях. Эти вопросы должны решаться, исходя из содержательного анализа задачи. Следует избегать и так называемых ложных корреляций, т.е. нельзя пытаться связать явления, между которыми отсутствуют реальные причинно-следственные связи. Например, корреляция между успехами местной футбольной команды и индексом Доу-Джонса. Классическим является пример ложной корреляции, приведенный в начале ХХ века известным российским статистиком А.А. Чупровым: если в качестве независимой переменной взять число пожарных команд в городе, а в качестве зависимой переменной – сумму убытков от пожаров за год, то между ними есть прямая корреляционная зависимость, т.е. чем больше пожарных команд, тем больше сумма убытков. На самом деле здесь нет причинно-следственной связи, а есть лишь следствия общей причины – величины города.
Проверка гипотезы о значимости выборочного коэффициента корреляции эквивалентна проверке гипотезы о b=0 (см. ниже) и, следовательно, равносильна проверке основной гипотезы об отсутствии линейной связи между Y и X. Вычисляя значение t-статистики
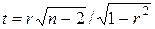 ,
,
вывод о значимости r делается при |t|>te, где te - соответствующее табличное значение t-распределения с (n-2) степенями свободы и уровнем значимости e.
Пример. Вычислим коэффициент корреляции и проверим его значимость для нашего примера табл. 2.1.
По (2.9) r=43145/(46510×40068,25)0,5=0,9994. R2=0,998. Значение t-статистики t=0,9994×[10/(1-0,998)]0,5=70,67. Поскольку t0,05;10=2,228, то t>t0,05;10 и коэффициент корреляции значим. Следовательно, можно считать, что линейная связь между переменными Y и X в примере существует. Ñ
Если между переменными имеет место нелинейная зависимость, то коэффициент корреляции теряет смысл как характеристика степени тесноты связи. В этом случае используется наряду с расчетом коэффициента детерминации расчет корреляционного отношения.
Предположим, что выборочные данные могут быть сгруппированы по оси объясняющей переменной X. Обозначим s – число интервалов группирования, 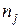 (j=1,…,s) – число выборочных точек, попавших в j-й интервал группирования,
(j=1,…,s) – число выборочных точек, попавших в j-й интервал группирования, 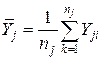 - среднее значение ординат точек, попавших в j-й интервал группирования,
- среднее значение ординат точек, попавших в j-й интервал группирования, 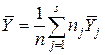 - общее среднее по выборке. С учетом формул для оценок выборочных дисперсий среднего значения Y внутри интервалов группирования
- общее среднее по выборке. С учетом формул для оценок выборочных дисперсий среднего значения Y внутри интервалов группирования 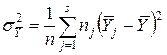 и суммарной дисперсии результатов наблюдения
и суммарной дисперсии результатов наблюдения 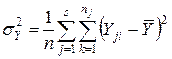 получим:
получим:
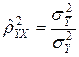 . (2.11)
. (2.11)
Величину 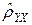 в (2.11) называют корреляционным отношением зависимой переменной Y по независимой переменной X. Его вычисление не предполагает каких-либо допущений о виде функции регрессии.
в (2.11) называют корреляционным отношением зависимой переменной Y по независимой переменной X. Его вычисление не предполагает каких-либо допущений о виде функции регрессии.
Величина по определению неотрицательная и не превышает единицы, причем =1 свидетельствует о наличии функциональной связи между переменными Y и X. Если указанные переменные не коррелированны друг с другом, то =0.
Можно показать, что не может быть меньше величины коэффициента корреляции r (формула (2.9)) и в случае линейной связи эти величины совпадают.
Это позволяет использовать величину разности 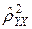 – R2 в качестве меры отклонения регрессионной зависимости от линейного вида.
– R2 в качестве меры отклонения регрессионной зависимости от линейного вида.
Дата добавления: 2017-04-20; просмотров: 886;