Временные ряды и их характеристики
МОДЕЛИ ВРЕМЕННЫХ РЯДОВ
При анализе многих экономических показателей используются статистические данные, упорядоченные по времени их получения (временные ряды). Зависимости между такими показателями получили название моделей временных рядов (динамических моделей). Эти модели могут включать в себя в качестве регрессоров как само время (t), так и текущие и предыдущие во времени значения переменных.
Следует заметить, что методы оценивания и исследования моделей временных рядов могут существенно отличаться от методов регрессионного анализа моделей пространственных данных, что связано с нарушением определенных условий Гаусса-Маркова (предпосылок МНК).
В последующих разделах этой главы мы рассмотрим некоторые общие вопросы построения регрессионных моделей временных рядов, включая анализ временных рядов в узком смысле, когда модель представляет собой последовательную временную зависимость некоторого показателя.
Временные ряды и их характеристики
Под временным рядом в экономике подразумевается последовательность наблюдений значений некоторой СВ Y, соответствующей определенному экономическому показателю, в последовательные моменты времени. Отдельные наблюдения носят название уровней временного ряда и обозначаются yt(t = 1, 2, …, n), где n - число уровней.
В общем случае экономический временной ряд представляется как совокупность следующих составляющих:
yt = ut + st + ct + et, (6.1)
где ut - тренд (тенденция), плавно меняющаяся компонента, описывающая чистое влияние долговременных факторов; st - сезонная компонента, отражающая повторяемость экономических процессов в течение определенного периода времени; ct - циклическая компонента, формирующая повторяющиеся изменения переменной yt под действием долговременных циклических факторов различной природы (например, влияние волн экономической активности Кондратьева, демографических «ям», циклов солнечной активности и т. п.); et - случайная компонента, отражающая влияние на экономический показатель всех неучтенных случайных факторов и обусловливающая случайную (стохастическую) природу временного ряда.
Следует заметить, что первые три компоненты временного ряда представляются неслучайными (детерминированными), закономерными. Эти составляющие не обязательно одновременно участвуют в процессе формирования временного ряда. Например, во многих практических случаях можно не рассматривать циклическую компоненту ct в аддитивной схеме (6.1). Однако влияние случайных факторов всегда имеет место, поэтому случайную компоненту необходимо учитывать во всех возможных ситуациях.
Важную роль в анализе временных рядов играют стационарные временные ряды, поскольку многие временные последовательности могут быть сведены к стационарному ряду после операций выделения тренда или сезонной компоненты. Временной ряд будем называть стационарным, если его числовые характеристики – математическое ожидание (среднее), дисперсия и ковариации случайной величины уt не зависят от времени t. Тогда математическое ожидание М[y(t)] = a и дисперсия такого ряда σ2 могут быть оценены в соответствии с имеющимися наблюдениями уt(t = 1, 2, .., n) по формулам:
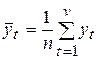 ; (6.2)
; (6.2)
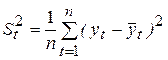 . (6.3)
. (6.3)
Здесь уt определяет уровень, относительно которого колеблются значения временного ряда, а S определяет размах этих колебаний.
Основной задачей анализа временных рядов является выявление и статистическая оценка основной тенденции (тренда либо тренда с сезонной компонентой) развития изучаемого процесса и отклонений от нее.
Первое и самое простое, что необходимо сделать на начальном этапе анализа временного ряда, – построить график полученных наблюдений. Возможно, что графическое представление временного ряда визуально покажет на наличие тренда или сезонной (периодической) компоненты.
Для выделения неслучайной составляющей необходимо осуществить выравнивание (сглаживание) временного ряда. Достаточно распространенным методом сглаживания является метод скользящих средних. Он основан на переходе от начальных значений уровней ряда к их средним значениям на интервале времени, длина которого выбирается заранее. При этом сам выбранный временной интервал как бы «скользит» по основному времени.
Полученный таким образом ряд интервальных средних ведет себя более гладко, чем исходный ряд, вследствие усреднения отклонений ряда. Действительно, если разброс значений временного ряда уt около своего среднего значения a характеризуется дисперсией σ2, то разброс среднего из m членов временного ряда (у1 + у2 +…+ уm) / m около того же значения a будет характеризоваться существенно меньшей дисперсией, равной σ2 / m.
Для усреднения могут быть использованы простая средняя, средняя с «весовыми» коэффициентами и медиана. При этом выбирают некоторую нечетную «длину усреднения» m = 2р + 1, измеренную в числе подряд идущих членов временного ряда ( 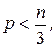 обычно не более трех). В случае использования для усреднения простой средней арифметической сглаженные значения временного ряда вычисляют по формуле:
обычно не более трех). В случае использования для усреднения простой средней арифметической сглаженные значения временного ряда вычисляют по формуле:
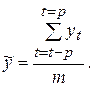 (6.4)
(6.4)
В результате применения такой процедуры получаются n - m + 1 сглаженных значений уровней ряда, при этом первые р уровней и последние р уровней ряда не сглаживаются.
Метод скользящей средней с «весовыми» коэффициентами отличается от метода простой средней тем, что уровни, входящие в интервал сглаживания, суммируются с разными весами, что позволяет проводить аппроксимацию ряда в пределах интервала сглаживания с использованием соответствующей полиномиальной функции.
При выборе полиномиальной функции, аппроксимирующей тренд, может быть применен метод последовательных разностей (абсолютных приростов), состоящий в вычислении разностей первого порядка 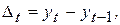 второго порядка
второго порядка 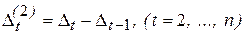 и т. д. Здесь порядок разностей, при котором они будут примерно одинаковы, принимается за степень полинома.
и т. д. Здесь порядок разностей, при котором они будут примерно одинаковы, принимается за степень полинома.
Наиболее статистически точными и обоснованными представляются аналитические методы выравнивания временного ряда, основанные на применении метода наименьших квадратов (МНК), который подробно рассмотрен нами в главе 2. В этом случае строится регрессионная модель вида
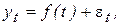 (6.5)
(6.5)
где значения временного ряда yt рассматриваются как зависимая переменная, а время t – как объясняющая переменная (регрессор). При выборе регрессионной зависимости f(t) на практике наиболее часто используются линейная, параболическая и экспоненциальная функции. Во многих случаях нелинейные функции могут быть подвергнуты линеаризации (см. раздел 4.1), что приводит к возможности построения уравнения тренда в виде линейной (или сведенной к линейной) модели
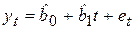 , (6.6)
, (6.6)
где еt - оценка случайной составляющей (случайное отклонение, остаток).
Параметры этой модели оцениваются по МНК, а ее надежность – по коэффициенту детерминации R2 и проверочной F-статистике.
Степень тесноты статистической связи между последовательностями уровней временного ряда, сдвинутыми относительно друг друга по времени на Dt = k единиц, может быть определена с помощью коэффициента корреляции (1.26):
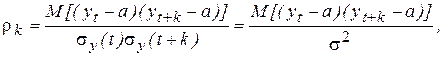 (6.7)
(6.7)
поскольку для стационарных временных рядов 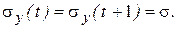
Временной сдвиг k, при котором рассчитывается коэффициент корреляции, называется лагом. Так как коэффициент rk измерят корреляцию между уровнями одного и того же ряда, его называют коэффициентом автокорреляции, а зависимость r(k) - автокорреляционной функцией. В силу предполагаемой стационарности временного ряда автокорреляционная функция зависит только от лага k, причем r(-k) = r(k).
Статистической оценкой rk является выборочный коэффициент автокорреляции rk, который, согласно соотношению (1.37), рассчитывается по формуле:
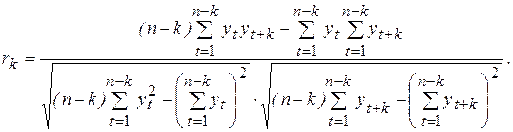 (6.8)
(6.8)
Последовательность значений r(k) называется выборочной автокорреляционной функцией, а ее график – коррелограммой.
С увеличением лага число пар наблюдений (n - k), по которым определяется выборочный коэффициент автокорреляции, уменьшается. Поэтому для обеспечения статистической достоверности расчетов рекомендуется выбирать величину лага k и, соответственно, максимальный порядок коэффициента автокорреляции не более n / 3.
Анализ автокорреляционной функции r(k) позволяет определить лаг, при котором связь между текущими и предыдущими уровнями ряда наиболее тесная. Если наиболее высоким оказался коэффициент автокорреляции первого порядка, то временной ряд содержит только тенденцию. Если наибольшим оказался коэффициент автокорреляции порядка k = m, то временной ряд содержит сезонную составляющую с периодичностью в m моментов времени.
Наряду с автокорреляционной функцией в анализе временных рядов используется частная автокорреляционная функция rчаст(k), представляющая собой последовательность частных коэффициентов корреляции (см. раздел 3.4) и выражающая степень корреляции между уt и уt + k при устранении влияния промежуточных ( 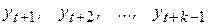 ) уровней ряда. Например, частный коэффициент автокорреляции между последовательностями наблюдений уt и
) уровней ряда. Например, частный коэффициент автокорреляции между последовательностями наблюдений уt и 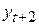 при устранении влияния
при устранении влияния 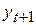 может быть оценен по формуле:
может быть оценен по формуле:
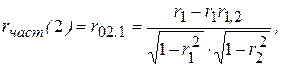 (6.9)
(6.9)
где r1, r1, 2, r2 - коэффициенты автокорреляции между уt и уt + 1, уt + 1 и уt + 2, уt и уt + 2 соответственно.
Знание автокорреляционных функций r(k) и rчаст(k), характеризующих внутреннюю структуру ряда, может оказать существенную помощь при подборе и анализе регрессионной модели временного ряда.
Важным практическим применением анализа временных рядов является прогнозирование на их основе развития изучаемого экономического процесса. При этом исходят из того, что тенденция развития, установленная в прошлом, может быть распространена (экстраполирована) на будущий период времени t.
В общем виде задача ставится следующим образом: имеется временной ряд уt (t = 1, 2, …, n), и требуется дать прогноз уровня этого ряда на момент времени n + t, а также оценить надежность прогноза.
Если можно рассматривать временной ряд как классическую регрессионную модель изучаемого признака по переменной «время», то для решения поставленной задачи в полной мере применимы методы анализа, рассмотренные нами в разделе 2.5, где дается точечный и интервальный прогноз зависимой переменной Y. Исходя из экономического смысла решения подобных задач, следует заметить, что прогноз изучаемого процесса на основе экстраполяции временного ряда оказывается эффективным в рамках краткосрочного, в крайнем случае, среднесрочного периода прогнозирования.
Необходимо также учитывать (как отмечалось в главе 5), что для временного ряда далеко не всегда удается подобрать «классическую» модель, для которой случайные отклонения et будут удовлетворять основным предпосылкам регрессионного анализа. В этом случае для улучшения прогнозирования может быть использована доступная информация о поведении ряда остатков.
Пример 6.1.В табл. 6.1 приведены статистические данные, отражающие динамику спроса на некоторый товар в течение 16 кварталов, т. е. временной ряд объемов спроса yt (усл. ед.).
Таблица 6.1
| t | ||||||||
| yt | 6,66 | 4,93 | 5,65 | 10,26 | 8,28 | 5,57 | 7,02 | 11,8 |
| t | ||||||||
| yt | 9,52 | 6,72 | 7,74 | 13,42 | 11,07 | 8,18 | 8,75 | 13,61 |
Необходимо охарактеризовать структуру временного ряда и построить аналитическую функцию для моделирования его тенденции (тренда).
 Изобразим графически данный временной ряд (рис. 6.1). По характеру расположения экспериментальных точек на графике можно выдвинуть предположение о наличии возрастающей тенденции (тренда) и сезонной компоненты.
Изобразим графически данный временной ряд (рис. 6.1). По характеру расположения экспериментальных точек на графике можно выдвинуть предположение о наличии возрастающей тенденции (тренда) и сезонной компоненты.
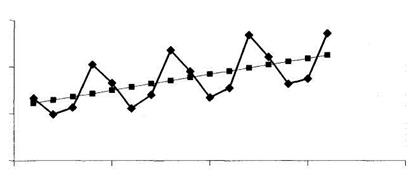
Рис. 6.1.
Рассчитаем коэффициенты автокорреляции первого, второго и высших порядков (до седьмого включительно), воспользовавшись формулой (6.8). Коэффициент автокорреляции 1-го порядка r1 (для лага k = 1) вычисляется по пятнадцати парам наблюдений yt и yt + 1; коэффициент автокорреляции 2-го порядка r2 – по четырнадцати парам наблюдений yt и yt + 2, и т. д. Проведя необходимые вычисления, получим последовательность значений автокорреляционной функции, которую представим в виде табл. 6.2.
Таблица 6.2
| Лаг, k | Коэффициент автокорреляции уровней временного ряда, rk |
| 0,257 | |
| -0,439 | |
| 0,204 | |
| 0,985 | |
| 0,182 | |
| -0,618 | |
| 0,058 |
Анализ значений автокорреляционной функции позволяет сделать вывод о том, что во временном ряду, во-первых, присутствует линейная тенденция, и, во-вторых, содержится сезонная компонента. Поскольку наибольшее абсолютное значение имеет коэффициент автокорреляции 4-го порядка, период сезонных колебаний равен 4.
По имеющимся статистическим данным (табл. 6.1) найдем регрессионное уравнение неслучайной компоненты (тренда) для временного ряда yt, полагая тренд линейным. Для этого проведем вычисления, порядок которых полностью аналогичен примеру 2.1, в которых вместо xi приводятся значения времени t. Оценивая параметры 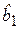 и
и 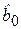 по МНК, получим уравнение тренда:
по МНК, получим уравнение тренда:
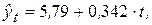
согласно которому спрос ежеквартально возрастает в среднем на 0,34 ед. На рис. 6.1 тренд изображен графически в виде сплошной линии.
Проверим статистическую значимость полученного уравнения тренда по F-критерию на 5%-ном уровне значимости (a = 0,05), для чего рассчитаем коэффициент детерминации по формуле (2.28):
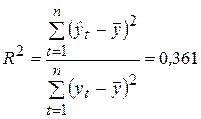 .
.
Затем найдем по формуле (2.30) наблюдаемое значение F-статистики:
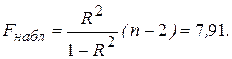
Критическое (табличное) значение F-статистики составляет F0,05; 1; 14 = 4,60. Поскольку Fнабл существенно превышает Fкр, то уравнение тренда статистически значимо, несмотря на относительно невысокое значение коэффициента детерминации.
Следует заметить, что учет сезонной компоненты при моделировании временного ряда в данном примере может быть осуществлен с помощью фиктивных переменных для кварталов (раздел 4.2).
Дата добавления: 2016-06-02; просмотров: 2770;