Характеристики точности оценок коэффициентов регрессии
Из МНК следует, что оценки коэффициентов уравнения регрессии 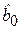 и
и 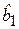 являются СВ, зависящими от случайной составляющей еi. При этом оценки тем надежнее, чем меньше их дисперсии D( )и D( ). Очевидно, что надежность получаемых оценок тесно связана с выборочной дисперсией случайных отклонений D(e).
являются СВ, зависящими от случайной составляющей еi. При этом оценки тем надежнее, чем меньше их дисперсии D( )и D( ). Очевидно, что надежность получаемых оценок тесно связана с выборочной дисперсией случайных отклонений D(e).
Исходя из МНК, можно показать, что для парной регрессии математическое ожидание дисперсии D(e) определяется выражением
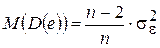 . (2.15)
. (2.15)
Отсюда следует, что
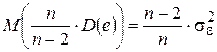 , т. е. величина
, т. е. величина
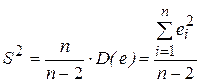 (2.16)
(2.16)
является несмещенной оценкой теоретической дисперсии случайных отклонений 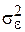 . S2 представляется как необъясненная дисперсия (мера разброса зависимой переменной вокруг линии регрессии). Величина
. S2 представляется как необъясненная дисперсия (мера разброса зависимой переменной вокруг линии регрессии). Величина  называется стандартной ошибкой оценки (стандартной ошибкой регрессионной модели).
называется стандартной ошибкой оценки (стандартной ошибкой регрессионной модели).
Характеристиками точности оценок коэффициентов и будут являться их стандартные отклонения, называемые стандартными ошибками (с.о.) коэффициентов регрессии
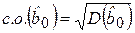 ,
, 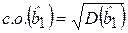 . (2.17)
. (2.17)
Приведем формулы связи дисперсий коэффициентов регрессии с необъясненной дисперсией S2, которые необходимы для расчета стандартных ошибок.
Формулу для определения можно представить в виде
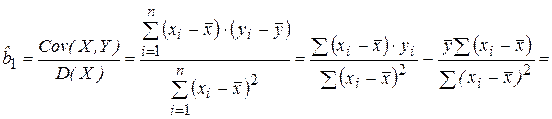
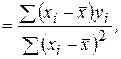 т. к.
т. к. 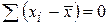 .
.
Вводя обозначение 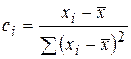 , запишем:
, запишем:
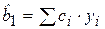 . (2.18)
. (2.18)
Тогда 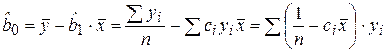 .
.
Обозначив  имеем:
имеем:
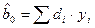 . (2.19)
. (2.19)
Так как дисперсию Y можно считать постоянной и не зависящей от Х для конкретных выборочных наблюдений, то ci и di можно рассматривать как некоторые постоянные.
Для регрессионной модели дисперсия Y будет фактически равна оценке дисперсии случайных отклонений S2. Следовательно,
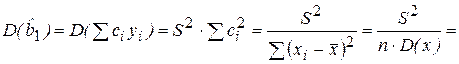
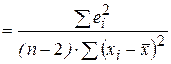 . (2.20)
. (2.20)
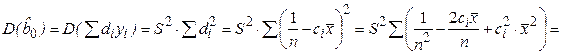
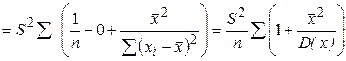 . (2.21)
. (2.21)
Формулы (2.17), (2.20) и (2.21) позволяют определять стандартные ошибки коэффициентов регрессии.
Из (2.20) следует, что дисперсия оценки (углового коэффициента парной регрессионной модели) тем больше, чем меньше дисперсия Х. Поэтому желательно выбирать набор значений xi таким образом, чтобы их разброс вокруг среднего значения был достаточно большим. Другими словами, точность оценок будет тем больше, чем шире область изменений объясняющей переменной (фактора-аргумента) Х.
Параметры эмпирической регрессионной модели изменяются при переходе от одной выборки к другой. Поэтому на практике возникает задача выбора наиболее точных и надежных параметров и определения их интервальных оценок. Эта задача решается путем сравнения коэффициентов регрессионных уравнений и с теоретическими коэффициентами b0 и b1 по схеме статистической проверки гипотез (см. раздел 1.6.4).
Если рассматривается гипотеза 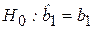 против альтернативной гипотезы
против альтернативной гипотезы 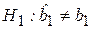 , то для анализа используется как мера ошибки относительная величина
, то для анализа используется как мера ошибки относительная величина
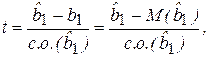 (2.22)
(2.22)
которая, по определению статистики Стьюдента, имеет распределение Стьюдента с числом степеней свободы v = n - 2 для парной линейной регрессии. Следовательно, на основании t-критерия гипотеза Н0 отклоняется если
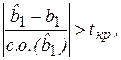 (2.23)
(2.23)
где tкр определяется по таблице критических точек распределения Стьюдента при требуемом уровне значимости α. В противном случае гипотеза Н0 принимается.
Тогда (в предположении, что верна Н0) для определения доверительного интервала параметра b1 воспользуемся соотношением для доверительной вероятности
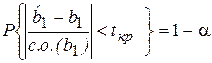 . (2.24)
. (2.24)
Переходя к двойному неравенству и разрешая его относительно b1 получим
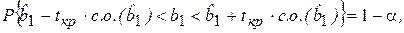
где 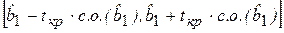 – доверительный интервал для b1. Например, при уровне значимости α = 0,05, это будет означать, что построенный доверительный интервал накрывает истинное значение коэффициента b1 с заданной вероятностью 0,95 (с надежностью 95 %).
– доверительный интервал для b1. Например, при уровне значимости α = 0,05, это будет означать, что построенный доверительный интервал накрывает истинное значение коэффициента b1 с заданной вероятностью 0,95 (с надежностью 95 %).
Наиболее простой и в то же время важной для парной регрессии задачей является проверка гипотезы 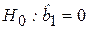 (
( 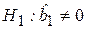 ), которую будем называть гипотезой о статистической значимости коэффициента регрессии.
), которую будем называть гипотезой о статистической значимости коэффициента регрессии.
Если Н0 принимается, то есть основания считать, что исследуемая величина Y не зависит от Х. В этом случае коэффициент считается статистически незначимым (близким к нулю). При отклонении Н0 (принятии Н1) коэффициент признается статистически значимым, что указывает на наличие определенной линейной зависимости между Y и Х.
В данной постановке гипотез t-статистика (критерий) определяется отношением
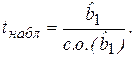 (2.25)
(2.25)
Это значение приводится всеми эконометрическими компьютерными пакетами в результатах регрессионной статистики. В данном случае рассматривается двусторонняя критическая область, поскольку может быть как положительным, так и отрицательным.
Чтобы сделать вывод о статистической значимости , рассчитывается соответствующее наблюдаемое значение tнабл по формуле (2.25) и сравнивается с критическим значением tкр при выбранном уровне значимости α и числе степеней свободы n - 2 (tα, n - 2). Если |tнабл| > tкр, то гипотеза Н0 отклоняется и коэффициент признается статистически значимым.
По аналогичной схеме на основе t-статистики проверяется гипотеза о статистической значимости коэффициента . В этом случае
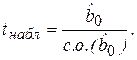 (2.26)
(2.26)
Малые значения t-статистики соответствуют отсутствию достоверной статистической значимости коэффициентов. Для получения промежуточных выводов при оценке значимости коэффициентов линейной регрессии (параметров модели) можно использовать следующее «грубое» правило, позволяющее не прибегать к таблицам.
Если |tнабл| < 2, то коэффициент не может быть признан достоверно статистически значимым.
Если |tнабл| > 3, то коэффициент признается статистически значимым. Доверительная вероятность в этом случае составляет не менее 0,95.
В случае 2 £ |tнабл| £ 3, найденная оценка может рассматриваться как относительно значимая.
Предложенное правило достаточно надежно работает, если число наблюдений n ³ 10.
Пример 2.2. По данным примера 2.1 вычислить характеристики точности и оценить статистическую значимость параметров построенной регрессионной модели.
Вычислим стандартные ошибки параметров парной регрессии. Для имеем:
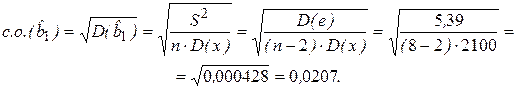
Вычисления дисперсии D(x) проведены при оценке параметра по МНК (знаменатель выражения (2.12)).
Для параметра 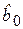 имеем:
имеем:
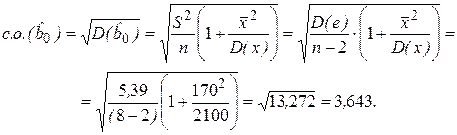
Проверим статистическую значимость параметров (коэффициентов регрессии). Расчетное (наблюдаемое значение) t-статистики для параметра :
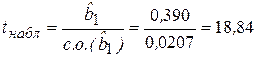 .
.
Табличное (критическое) значение t-статистики при уровне значимости α = 0,01 и числе степеней свободы v = n - 2 = 6 будет составлять tкр = 3,71.
Поскольку |tнабл| > tкр (18,84 > 3,71), то гипотеза Н0 (нулевая гипотеза) отклоняется и принимается альтернативная гипотеза Н1, согласно которой коэффициент регрессии признается статистически значимым.
Для параметра (свободного члена) наблюдаемое значение t-статистики вычислим по формуле (2.26):
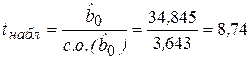 .
.
Так как |tнабл| > tкр (8,74 > 3,71), то нулевая гипотеза отклоняется и свободный член в уравнении регрессионной модели 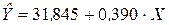 признается статистически значимым.
признается статистически значимым.
Рассчитаем доверительные интервалы параметров и для уровня значимости α = 0,05. В этом случае значение tкр = 2,45.
Доверительный интервал для коэффициента регрессии 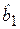 :
:
[0,39 - 2,45 · 0,0207; 0,39 + 2,45 · 0,0207] ~ [0,339 (нижняя граница); 0,440 (верхняя граница)].
Построенный интервал накрывает истинное значение с надежностью 95 %.
Доверительный интервал для свободного члена :
[34,845 - 2,45 · 3,643; 34,845 + 2,45 · 3,643] ~ [22,93; 40,76].
Таким образом, параметры построенной по имеющимся статистическим данным регрессионной модели будут находиться в указанных границах с вероятностью Р = 1 - α = 0,95.
Дата добавления: 2016-06-02; просмотров: 1730;