Статистические ряды
Особую форму группировки данных представляют так называемые статистические ряды, или числовые значения признака, расположенного в определенном порядке. В зависимости от того, какие признаки изучаются, статистические ряды делят на атрибутивные, вариационные, ряды динамики, регрессии, ряды ранжированных значений признаков и ряды накопленных частот. Наиболее часто в психологии используются вариационные ряды, ряды регрессии и ряды ранжированных значений признаков.
Вариационным рядом распределения называют двойной ряд чисел, показывающий, каким образом числовые значения признака связаны с их повторяемостью в данной выборке. Например, психолог провел тестирование интеллекта по тесту Векслера у 25 школьников, и сырые баллы по второму субтесту оказались следующими: 6, 9, 5, 7, 10, 8, 9, 10, 8, 11, 9, 12, 9, 8, 10, 11, 9, 10, 8, 10, 7, 9, 10, 9, 11. Как видим, некоторые цифры попадаются в данном ряду по несколько раз. Следовательно, учитывая число повторений, данные ряд можно представить в более удобной, компактной форме:
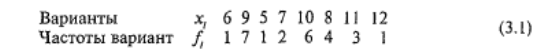
Это и есть вариационный ряд. Числа, показывающие, сколько раз отдельные варианты встречаются в данной совокупности, называются частотами, или весами, вариант. Они обозначаются строчной буквой латинского алфавита.fi и имеют индекс “i”, соответствующий номеру переменной в вариационном ряду.

Процентное представление частот полезно в тех случаях, когда приходится сравнивать вариационные ряды, сильно различающиеся по объемам. Например, при тестировании школьной готовности детей города, поселка городского типа и села были обследованы выборки детей численностью 1000, 300 и 100 человека соответственно. Различие в объемах выборок очевидно. Поэтому сравнение результатов тестирования лучше проводить, используя проценты частот.
Приведенный выше ряд (3.1) можно представить по другому. Если элементы ряда расположить в возрастающем порядке, то получится так называемый ранжированный вариационный ряд:

Подобная форма представления (3.3) более предпочтительна, чем (3.1), поскольку лучше иллюстрирует закономерность варьирования признака.
Частоты, характеризующие ранжированный вариационный ряд, можно складывать, или накапливать. Накопленные частоты получаются последовательным суммированием значений частот от первой частоты до последней.
В качестве примера вновь обратимся к ряду 3.3. Преобразуем его в ряд 3.4 в котором введем дополнительную строчку и назовем ее «кумуляты частот»:

Рассмотрим подробно как получилась последняя строчка. В начале ряда частот стоит 1. В кумулятивном ряду на втором месте стоит 2 — это сумма первой и второй частоты, т.е. 1 + 1, на третьем месте стоит 4 это сумма второй (уже накопленной частоты) и третьей частоты, т.е. 2 + 2, на четвертом 8 = 4 + 4 и т.д.
Размах (иногда эту величину называют разбросом) выборки обозначается буквой R. Это самый простой показатель, который можно получить для выборки — разность между максимальной и минимальной величинами данного конкретного вариационного ряда, т.е.
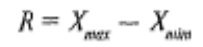
Понятно, что чем сильнее варьирует измеряемый признак, тем больше величина R, и наоборот.
Однако может случиться так, что у двух выборочных рядов и средние, и размах совпадают, однако характер варьирования этих рядов будет различный. Например, даны две выборки:
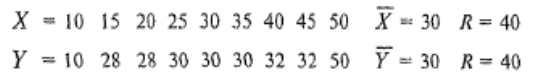
При равенстве средних и разбросов для этих двух выборочных рядов характер их варьирования различен. Для того чтобы более четко представлять характер варьирования выборок, следует обратиться к их распределениям.
Таблицы и графики распределения частот
Как правило, анализ данных начинается с изучения того, как часто встречаются те или иные значения интересующего исследователя признака (переменной) в имеющемся множестве наблюдений. Для этого строятся таблицы и графики распределения частот. Нередко они являются основой для получения ценных содержательных выводов исследования.
Если признак принимает всего лишь несколько возможных значений (до 10-15), то таблица распределения частот показывает частоту встречаемости каждого значения признака. Если указывается, сколько раз встречается каждое значение признака, то это — таблица абсолютных частот распределения, если указывается доля наблюдений, приходящихся на то или иное значение признака, то говорят об относительных частотах распределения.
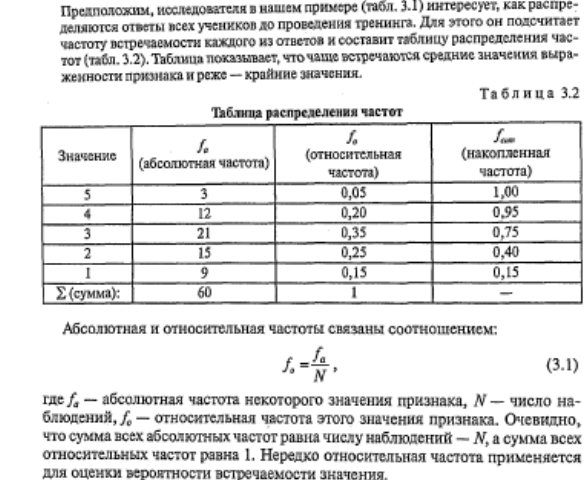
Во многих случаях признак может принимать множество различных значений, например, если мы измеряем время решения тестовой задачи. В этом случае о распределении признака позволяет судить таблица сгруппированных частот, в которых частоты группируются по разрядам или интервалам значений признака.

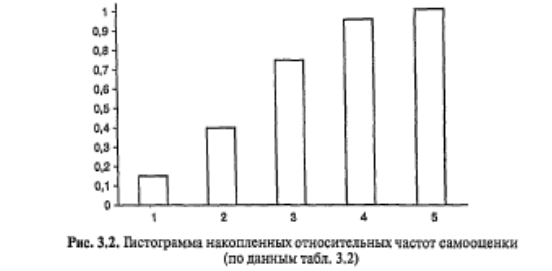
Еще одной разновидностью таблиц распределения являются таблицы распределения накопленных частот. Они показывают, как накапливаются частоты по мере возрастания значений признака. Напротив каждого значения (интервала) указывается сумма частот встречаемости всех тех наблюдений, величина признака у которых не превышает данного значения (меньше верхней границы данного интервала). Накопленные частоты содержатся в правых столбцах табл. 3.2 и 3.3.
Для более наглядного представления строится график распределения частот или график накопленных частот — гистограмма или сглаженная кривая распределения.

Гистограмма распределения частот - это столбиковая диаграмма, каждый столбец которой опирается на конкретное значение признака или разрядный интервал (для сгруппированных частот). Высота столбика пропорциональна частоте встречаемости соответствующего значения. На рис. 3.1 изображена гистограмма распределения частот для примера из табл. 3.2.
Гистограмма накошенных частот отличается от гистограммы распределения тем, что высота каждого столбика пропорциональна частоте, накопленной к данному значению (интервалу). На рис. 3.2 изображена гистограмма накопленных частот для данных табл. 3.2.
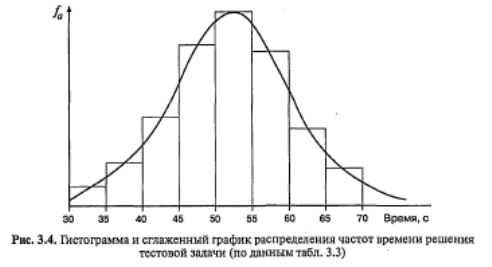
Построение полигона распределения частот напоминает построение гистограммы. В гистограмме вершина каждого столбца, соответствующая частоте встречаемости данного значения (интервала) признака, — отрезок прямой. А для полигона отмечается точка, соответствующая середине этого отрезка. Далее все точки соединяются ломаной линией (рис. 3.3). Вместо гистограммы или полигона часто изображают сглаженную кривую распределения частот. На рис. 3.4 изображена гистограмма распределения для примера из табл. 3.3 (столбики) и сглаженная кривая того же распределения частот.

Таблицы и графики распределения частот дают важную предварительную информацию о форме распределения признака: о том, какие значения встречаются реже, а какие чаще, насколько выражена изменчивость признака. Обычно выделяют следующие типичные формы распределения. Равномерное распределение – когда все значения встречаются одинаково (или почти одинаково) часто. Симметричное распределение — когда одинаково часто встречаются крайние значения. Нормальное распределение — симметричное распределение, у которого крайние значения встречаются редко и частота постепенно повышается от крайних к серединным значениям признака. Асимметричные распределения — левосторонние (с преобладанием частот малых значений), правосторонние (с преобладанием частот больших значений).
Уже сами по себе таблицы и графики распределения признака позволяют делать некоторые содержательные выводы при сравнении групп испытуемых между собой. Сравнивая распределения, мы можем не только судить о том, какие значения встречаются чаще в той или иной группе, но и сравнивать группы по степени выраженности индивидуальных различий — изменчивости по данному признаку.
Таблицы и графики накопленных частот позволяют быстро получить дополнительную информацию о том, сколько испытуемых (или какая их доля) имеют выраженность признака не выше определенного значения.
Раздел 4. Описательные статистики
(Статистическое распределение и его числовые характеристики)
Переменная может принимать много значений. На начальном этапе обработки данных вместо того, чтобы рассматривать все значения переменной, рекомендуется проанализировать т. к. описательные статистики. Они дают общее представление о значениях или разбросе значений, которые принимает переменная.
К первичным описательным статистикам (Descriptive Statistics) обычно относят числовые характеристики распределения измеренного на выборке признака. Каждая такая характеристика отражает в одном числовом значении свойство распределения множества результатов измерения: с точки зрения их расположения на числовой оси либо с точки зрения их изменчивости. Основное назначение каждой из первичных описательных статистик — замена множества значений признака, измеренного на выборке, одним числом (например, средним значением как мерой центральной тенденции). Компактное описание группы при помощи первичных статистик позволяет интерпретировать результаты измерений, в частности, путем сравнения первичных статистик разных групп.
Дата добавления: 2016-03-04; просмотров: 2538;