МНОГОСЛОЙНЫЕ МОДЕЛИ ДАННЫХ ГИС
В то время, как растровые и векторные структуры данных дают нам средства отображения отдельных пространственных феноменов на отдельных картах, все же существует необходимость разработки более сложных подходов, называемых моделями данных, для включения в базу данных взаимоотношений объектов, связывания объектов и их атрибутов, обеспечения совместного анализа нескольких слоев карты.
Вначале мы рассмотрим растровые модели, затем — векторные. После этого мы сделаем еще один шаг и рассмотрим способы комбинирования этих моделей данных в системы, в данном случае - геоинформационные системы.
Растровые модели
Как говорилось в начале нашего обсуждения растровых структур данных, каждая ячейка в простейшей такой структуре связана с одним значением атрибута. Для создания растровой тематической карты мы собираем данные об определенной теме в форме двухмерного массива ячеек, где каждая ячейка представляет атрибут отдельной темы. Такой двухмерный массив называется покрытием (coverage). Мы можем использовать покрытия для представления различных типов тематических данных (землепользование, растительность, тип почвы, поверхностная геология, гидрология и т.д.). Кроме того, этот подход позволяет нам фокусировать внимание на объектах, распределениях и взаимосвязях тем без ненужной путаницы. Поскольку чаще всего мы интересуемся взаимосвязями одной темы, скажем, типа почвы, с другими, то создаем отдельное покрытие для каждой дополнительной темы. Тогда мы можем сложить эти покрытия наподобие слоеного пирога, в которой сочетание всех тем может адекватно моделировать все необходимые характеристики области изучения. Если мы интересуемся только природными феноменами, то каждый важный компонент физической географии будет представлен отдельно, а вместе они дадут нам полный, многоаспектный вид изучаемой области.
Существует несколько способов хранения и адресации значений отдельных ячеек растра, их атрибутов, названий покрытий и легенд. Среди первых попыток можно упомянуть подход под названиемGRID/LUNR/ MAGI [Burrough, 1983] (Рисунок 4.1 la); все ранние растровые ГИС использовали именно его. В этой модели каждая ячейка содержит все атрибуты вроде вертикального столбика значений, где каждое значение относится к отдельной теме. Так, значение атрибута типа почвы в позиции Х=10, Y=10 будет находиться рядом со значением атрибута типа растительности в той же позиции Х= 10, Y= 10. Вы могли бы представить это себе как геологический керн, в котором каждый тип породы лежит поверх следующего, и для того, чтобы получить картину всей области исследования, нужно сложить вместе данные многих кернов. Преимуществом, конечно, является то, что относительно легко выполняется вычислительное сравнение многих тем или покрытий для каждой ячейки растра. Но в то же время, неудобно сравнивать группы ячеек одного покрытия с группами ячеек другого покрытия, поскольку каждая ячейка должна адресоваться индивидуально.
Подумайте хорошенько о том, что бы вы хотели изменить в этом подходе. Возможно, вы подумали о шахматной доске с ее черными и белыми квадратами. Если каждый из таких квадратов представляет тип ландшафта (например, черный - суша, белый - водная поверхность), то мы создали простое покрытие. Но как атрибуты нашего ландшафтного покрытия соединены физически? Мы можем взять в руки всю доску, поскольку она -физически связная структура. Аналогичным образом, тематическая карта представляет все разнообразные значения темы как единый связный объект. Вполне естественно сходство между доской как единого целого для игры и карты как единого целого для хранения пространственной информации.
В действительности, с небольшим изменением аналогии с шахматной доской, мы можем рассмотреть вторую модель растровых данных, которую Назовем моделью данныхIMGRID (Рисунок 4.11b) потому, что она использовалась в ранней ГИС с таким названием [Burrough, 1983]. Здесь мы Примем, что белые ячейки это "вода", а черные - "не вода". Мы упростили тему нашей шахматной карты до хранения одного простого атрибута, а не целой темы. В этом случае нам нет необходимости хранить широкий спектр значений для каждого покрытия. Вместо этого мы можем использовать числа 1 (белые квадраты) для обозначения присутствия воды и 0 (черные квадраты) — для обозначения ее отсутствия. А как бы мы представили тематическую карту землепользования, содержащую, скажем, четыре категории — зоны отдыха, сельского хозяйства, промышленности и жилья? Каждый из этих атрибутов должен быть выделен как самостоятельный слой. Один слой содержал бы признак только сельского хозяйства, 1 и 0 для него означали бы соответственно наличие и отсутствие такой деятельности в каждой ячейке растра. Аналогично представляются отдых, промышленность и жилье, причем прямо адресуется теперь каждый признак, а не ячейки растра, как было в модели данных GRID/LUNR/MAGI. В конечном итоге, слои можно сложить "вертикально" для получения единой карты.
Система IMGRID имеет два основных преимущества. Во-первых, мы имеем непрерывную структуру, которая больше напоминает карту. То есть, мы храним двухмерные массивы чисел для разных слоев, а не массив столбиков. Во-вторых, мы уменьшили диапазон значений для каждого слоя до одного двоичного разряда. Это упростит наши вычисления и устранит необходимость в сложной легенде карты. На самом деле, поскольку каждый признак однозначно идентифицирован одним битом, мы можем не ограничиваться одним атрибутом для каждой ячейки растра, и это третье преимущество. Например, в некоторой ячейке растра мы можем иметь частично зоны сельского хозяйства и отдыха. Поскольку каждый из этих атрибутов землепользования хранится в отдельном слое, мы можем показать, что оба вида землепользования имеют место в пределах пространства этой ячейки растра. Конечно, мы можем встретить трудности, создавая объединенное тематическое покрытие, если внутри некоторых ячеек присутствуют несколько признаков. Чтобы избежать этой проблемы, нам нужно обеспечить, чтобы каждая ячейка имела одно значение для каждого показателя.
Модель IMGRID выглядит более понятной с точки зрения картографического представления. Более того, она дает преимущество для компьютера в использовании слоя как прямо адресуемого объекта.
Ее ограничения происходят в основном из-за проблемы взрывного роста количества элементов данных. Представьте на минуту, что вы имеете базу данных из 50-ти тем (что вполне возможно). Допустим, что в среднем имеется 10 категорий в каждой теме. Каждая тема должна быть разделена на бинарные (из нулей и единиц) слои, по одному на каждую категорию. Итого, для представления этой вполне умеренной базы данных вам потребуется 10 х 50 = 500 слоев. Хотя программное обеспечение и позволяет управлять таким большим "хозяйством", нам нужен более эффективный способ представления нашей базы данных, такой, который не создает так много
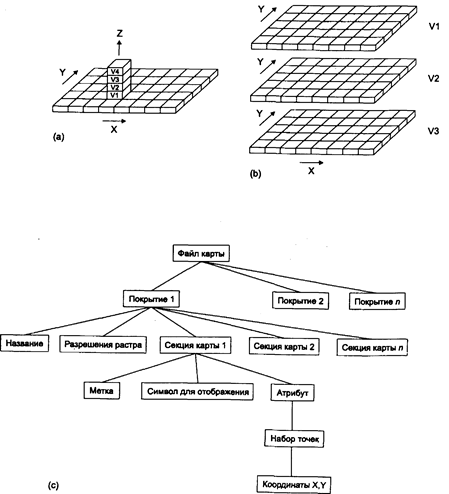
Рисунок 4.11. Три растровые модели данных для множественных покрытий:
а) Модель GRID/LUNR/MAGI; b) Модель IMGRID; с) Модель MAP.
элементов данных, которыми нужно управлять. Рассматривая далее этот подход, представьте себе, как много значений придется модифицировать и записывать для создания каждой новой темы.
Наша третья растровая модель, которую мы назовем MAP по названию системы Пакета анализа карт (Map Analysis Package, MAP) [Burrough, 1983], разработанной Д. Томлин для своей докторской диссертации, формально объединяет преимущества двух предыдущих моделей. В этой модели данных (Рисунок 4.11с) каждое тематическое покрытие записывается и выбирается отдельно по имени карты или названию, что достигается записью каждого показателя (картографической секции) темы покрытия как отдельного числового кода или метки, которая может быть доступна отдельно при выборке покрытия. Метка соответствует части легенды, и с ней связан собственный приписанный ей символ. Таким образом, легко выполняются операции над отдельными ячейками растра и группами похожих ячеек, а результат изменений величины требует перезаписи только одного числа на картографическую секцию, упрощая тем самым вычисления. Главное преимущество метода MAP состоит в том, что он обеспечивает легкую манипуляцию значениями атрибутов и наборами ячеек растра в отношении "многие к одному".
Модель данных MAP - одна из наиболее используемых растровых моделей на рынке ГИС. Ее можно найти во многих формах, от ее изначальной версии на больших машинах до вариантов для Macintosh и PC и современных рабочих станций под управлением UNIX. Гибкость и легкость использования сделали ее легкодоступным средством для обучения геоинформатике, она может использоваться в дополнительных модулях коммерческих ГИС-пакетов и даже как основа для полнофункциональных растровых ГИС.
В то время как растровые ГИС традиционно разрабатывались для представления одиночных атрибутов, хранимых индивидуально для каждой ячейки растра, некоторые из них достигли состояния использования прямых связей с существующими СУБД. Такие расширения растровой модели данных позволили также установить прямую связь с ГИС, использующими векторную структуру графических данных. Поскольку такие интегрированные растрово-векторные системы включают модули, которые преобразуют информацию из растровой формы в векторную и обратно, пользователь может использовать достоинства обеих структур данных. Процесс преобразования часто прозрачен, так что пользователю даже не нужно беспокоиться об исходной структуре данных.
Эта возможность особенно важна, поскольку она усиливает взаимодействие между программным обеспечением традиционной обработки цифровых изображений и геоинформационными системами.
Сегодня уже многие программные системы имеют оба набора функций, и еще больше таких систем появится в будущем. Благодаря еще и взаимодействию с существующими статистическими пакетами мы быстро приближаемся к системам, которые работают с множеством пространственных и непространственных аналитических методов, а в результате - к периоду расцвета компьютерной географии.
Дата добавления: 2016-02-24; просмотров: 2414;