Методы сжатия растровых данных
Перед тем как закончить обсуждение растровых моделей данных, мы должны рассмотреть четыре метода хранения растровых данных, которым свойственна существенная экономия дискового пространства. Методы сжатия растровых данных работают внутри подсистемы хранения и редактирования ГИС, но они могут вызываться и напрямую на этапе ввода информации в ГИС. Мы вернемся к этим методам в следующей главе при рассмотрении ввода данных. Подходы, освещаемые в этой главе, проиллюстрированы на Рисунке 4.12.
Первый метод сжатия растровых (и не только растровых) данных называется групповым кодированием. Когда-то растровые данные вводились в ГИС с помощью пронумерованной прозрачной сетки, которая накладывалась на кодируемую карту. Каждая ячейка имела численное значение, соответствующее данным карты, которые вводились (обычно с клавиатуры) в компьютер. Например, для карты размером 200 х 200 ячеек потребуется ввести 40'000 чисел. Если ваш преподаватель сейчас услышит ваше хихиканье, не удивляйтесь, обнаружив себя за этим занятием в качестве упражнения по истории ГИС или урока скромности. На самом деле, вы можете попробовать его как-нибудь, если у вас есть доступ к какой-либо растровой ГИС. Начав вводить, вы быстро обнаружите повторения данных, которые могут быть использованы для уменьшения работы. Конкретнее, в каждом ряду существуют длинные цепочки одинаковых чисел. Подумайте, сколько времени вы сэкономите на одной строке, если бы могли сказать компьютеру, что, например, с позиции 8 по позицию 56 идут одни единицы, ас 57-й позиции до конца ряда идут двойки. В действительности, вы могли бы также сохранить немало объема памяти, записывая только начальную и конечную позицию для каждой цепочки и значение, которое в ней присутствует. В этом и состоит идея группового кодирования.
Конечно, этот метод действует в пределах одной строки растра. Что, если бы вы могли сказать компьютеру начать с отдельной ячейки со значением 1, затем перейти в определенном направлении, скажем вертикально, на 27 ячеек и тогда изменить значение. Это позволило бы кодировать цепочки в любом направлении. Но принцип может быть расширен и дальше. Допустим,
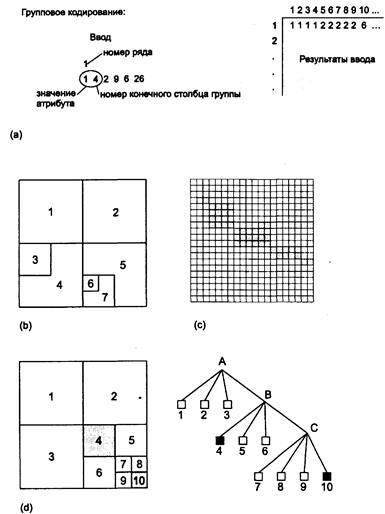
Рисунок 4.12. Методы сжатия растровых данных, а) групповое кодирование, b) блочное кодирование, с) цепочечное кодирование, d) квадродерево.
что вы видите большую группу ячеек растра, представляющую некоторую область. Если вы начнете с одного угла, задав его координаты и значение ячейки, затем перейдете по главным направлениям (вниз, вверх, вправо, влево) вдоль области, записав число, представляющее направление, и еще одно, равное количеству ячеек, на которое вы переместились, то для записи области потребуется всего лишь несколько чисел. Таким образом, вы бы сохранили еще больше места на диске и, конечно, времени ручного ввода. Этот метод называетсяцепочечным кодированием (raster chain codes), он буквально прокладывает цепь ячеек растра вдоль границы каждой области. В общем, вы указываете координаты (X,Y) начала, значение ячеек для всей области, а затем вектора направлений, показывающие, куда двигаться дальше, где повернуть и как далеко идти. Обычно векторы описываются количеством ячеек и направлением в виде чисел 0,1,2,3, соответствующих движению вверх, вниз, вправо и влево.
Есть еще два подхода к сжатию растровой информации, оба ориентированы на квадратные матрицы. Первый, называемыйблочным кодированием (block codes), является модификацией группового кодирования. Вместо указания начальной и конечной точек и значения ячеек, мы выбираем квадратную группу ячеек растра и назначаем начальную точку, скажем, центр или угол, берем значение ячейки и сообщаем компьютеру ширину квадрата ячеек. Как видите, это, в сущности, двухмерное групповое кодирование. Таким образом может быть записана каждая квадратная группа ячеек, включая и отдельные ячейки, с минимальным количеством чисел. Конечно, если ваше покрытие имеет очень мало больших квадратных групп ячеек, этот метод не даст значительного выигрыша в объеме памяти. Но в таком случае и групповое кодирование может быть неэффективно, когда есть мало длинных цепочек одной величины. Но все же большинство тематических карт имеют достаточно большое количество таких групп, и блочное кодирование поэтому очень эффективно.
Квадродерево (Quadtree), последний рассматриваемый нами метод сжатия растровых данных, несколько сложнее, и ваш преподаватель может посчитать ненужным его освещать. Все же существует по меньшей мере одна коммерческая система компании Tydac под названием SPANS и одна экспериментальная система под названием Quilt [Shaffer, Samet, and Nelson, 1987], которые основаны на этой схеме. Как и блочное кодирование, квадродерево основано на квадратных группах ячеек растра, но в данном случае вся карта последовательно делится на квадраты с одинаковым значением атрибута внутри. Вначале квадрат размером со всю карту делится на четыре квадранта (СЗ, СВ, ЮЗ, ЮВ). Если один из них однороден (т.е. содержит ячейки с одним и тем же значением), то этот квадрант записывается и больше не участвует в делении. Каждый оставшийся квадрант опять делится на четыре квадранта, опять СЗ, СВ, ЮЗ, ЮВ. Опять каждый квадрант проверяется на однородность. Все однородные квадранты записываются, и каждый из оставшихся делится далее и проверяется, пока вся карта не будет записана как множество квадратных групп ячеек, каждая с одинаковым значением атрибута внутри. Мельчайшим квадратом является одна ячейка растра [Burrough, 1983].
Системы, основанные на квадродереве, называются системами с переменным разрешением, так как они могут оперировать на любом уровне деления квадродерева. Пользователи могут решать, какой уровень разрешения нужен для их расчетов. Кроме того, благодаря высокой степени компрессии данных этого метода, в одной системе могут храниться очень большие базы данных — масштаба континента и даже всей Земли.
Наибольшей трудностью для квадродерева является метод разделения ячеек растра на регионы. В блочном кодировании решение принимается целиком на основе существования квадратных групп однородности независимо от того, где они находятся на карте. В квадродереве деление на квадранты фиксировано, поэтому некоторые однородные регионы оказываются разбитыми на несколько квадрантов. Это приводит к некоторым трудностям при анализе формы и распределения, которые приходится преодолевать достаточно сложными вычислительными методами, выходящими за рамки данной книги. ГИС, использующие квадродерево, функционируют на рабочих станциях и PC в среде разных операционных систем. Такие программы используются по всему миру и предлагают некоторые интересные возможности, особенно для тех, кто работает с очень большими базами данных.
Дата добавления: 2016-02-24; просмотров: 3520;