Иерархическая структура данных
Во многих случаях существует взаимосвязь между данными, называемая отношением "один ко многим" [Burrough, 1983]. Это отношение подразумевает, что каждый элемент данных имеет прямую связь с некоторым числом так называемых "потомков", и, конечно каждый такой потомок, в свою очередь, может иметь связь со своими потомками и т.д. Как следует из названия, предки и потомки напрямую связаны между собой, что делает доступ к данным простым и эффективным (Рисунок 4.6). Такая система хорошо иллюстрируется иерархической системой классификации растений и животных, называемой таксономией.
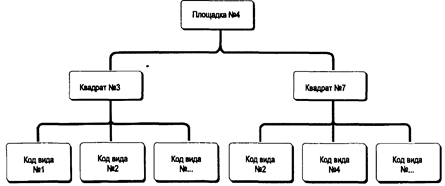
Рисунок 4.6. Иерархическая структура БД. Показано ветвление от предков к потомкам на основе ключевых атрибутов.
Например, животные делятся на позвоночные и беспозвоночные. В свою очередь, позвоночные имеют подмножество, называемое млекопитающими. Млекопитающие могут быть далее разделены на подгруппы. Структура становится похожей на генеалогическое дерево, и в действительности таксономисты используют почти такую же графическую форму для представления отношений между видами. Главной характеристикой иерархической структуры, иллюстрируемой таксономическим деревом, является прямая взаимосвязь между одной ветвью и другой. Ветвление основано на формальных ключевых признаках, которые определяют продвижение по этой структуре от одной ветви к другой.
Как вы могли догадаться, если ваша информация о ключевом признаке недостаточна, то вы не сможете продвигаться по дереву В действительности, природа иерархической системы требует явного определения каждого отношения для того, чтобы создать саму структуру и ее правила ветвления. Главным преимуществом такой системы является то, что в ней очень легко искать, поскольку она хорошо определена и может относительно легко расширяться добавлением новых ветвей и формулированием новых правил ветвления. Но если ваше изначальное описание структуры неполно или если вы хотите двигаться по ней на основе корректного критерия, который не включен в структуру, то поиск становится невозможным. Для создания иерархической структуры совершенно необходимо знание всех возможных вопросов, которые могут задаваться, поскольку эти вопросы используются как основа для разработки правил ветвления или ключей.
Наверняка многие из вас сталкивались с компьютерной системой библиографического поиска. Такие системы имитируют способы поиска книг и статей, который люди использовали до внедрения компьютеров. Мы можем искать отталкиваясь от темы, имени автора, названия и даже по диапазону номеров в каталоге, ограничивающем нас частью библиотечного фонда.
Системы, которые могут выполнять поиск по множественным критериям и с применением булевых операций отражают обе потребности легкой разработки иерархии - хорошо определенные критерии и ограниченное число типов запросов. Но представьте себе, что вам попадалась хорошая книга по геоинформатике в северо-западном углу пятого этажа главной библиотеки института. Вы не помните номер по каталогу, но хотели бы найти и другие книги, находящиеся рядом с упомянутой. Конечно, вы не будете просить библиографическую систему отыскать все книга в северо-западном углу пятого этажа главной библиотеки. Метод может быть и сработает в конце концов, но на практике вам нужно знать побольше о книгах в вашей предметной области.
Ситуации подобного недостаточно определенного запроса не так уж редки при работе с информацией в ГИС. Одна из наиболее трудных вещей - предвосхитить все возможные запросы пользователя. В конце концов, БД ГИС обычно содержит множество типов информации и разных тематических карт. Одной из самых интересных особенностей ГИС является то, что вы можете попытаться выполнить поиск или исследовать взаимосвязи, которые не предполагались до реализации системы. К сожалению, иерархическая структура не очень подходит для этого из-за ее жесткой ключевой структуры.
Помимо этого сурового ограничения иерархическая структура часто порождает большие индексные файлы. Это требует дополнительных затрат памяти для хранения данных и иногда вносит свой вклад также и в рост времени доступа.
Сетевые структуры
Как мы видели, возможности быстрого поиска, выполняемого в иерархической структуре данных, определяются структурой самого дерева. Атрибутивные и геометрические данные могут храниться в разных местах, что потребует установления большого числа связей между графической и атрибутивной частями БД. В таком случае потенциальное число ветвлений и связанных с ними ключей иерархической структуры может стать очень большим. Такая неуклюжесть возникает главным образом потому, что иерархическая структура данных больше всего подходит, когда между элементами данных требуется устанавливать связи "один к одному" или "один ко многим".
Сетевые БД ГИС используют отношение "многие ко многим", при котором один элемент может иметь многие атрибуты, при этом каждый атрибут связан явно со многими элементами. Например, исследуемый участок может иметь много квадратов, с каждым из которых может быть связаны несколько животных и растительных видов, при том, что каждый вид может присутствовать в более чем одном квадрате. Для реализации таких отношений вместе с каждым элементом данных может быть связана специальная переменная, называемая указателем (pointer), которая направляет нас ко всем другим элементам данных, связанным с этим (Рисунок 4.7). Вместо того, чтобы ограничиваться древовидной структурой связей, каждый отдельный элемент данных может быть прямо связан с любым местом базы данных, без введения отношения "предок-потомок". Указатели — обычное явление в языках программирования вроде Си и Си++, и некоторое знание их поможет вам в понимании того, как именно эти приемы реализуются. Для наших целей будет достаточно графической иллюстрации. Рисунок 4.7 показывает два квадрата (№3 и №7) исследовательской площадки №4. Обратите внимание на то, как указатели используются для связи отдельных квадратов с представляющими их видами.
Указатели обеспечивают и обратную связь от видов к квадратам, в которых они находятся.
Сетевые структуры обычно рассматриваются как усовершенствование иерархических структур, поскольку они менее жесткие и могут представлять отношение "многие ко многим". Поэтому они допускают гораздо большую гибкость поиска, нежели иерархические структуры. Также в отличие от иерархических структур они уменьшают избыточность данных. Их главным недостатком является то, что в крупных БД ГИС количество указателей может стать очень большим, требуя значительной затрат памяти. Вдобавок, хотя связи между элементами данных более гибкие, они все же должны быть явно определены с помощью указателей. Многочисленные возможные связи могут превратиться в весьма запутанную сеть, приводя часто к путанице, потерянным и ошибочным связям. Новички часто оказываются подавлены этими условиями, но опытные пользователи могут достичь высокой эффективности с такими системами и часто предпочитают их перед другими.
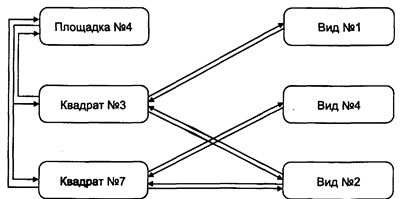
Рисунок 4.7. Сетевая структура БД. Эта структура позволяет пользователю перемещаться от одного элемента данных к другому через цепочку указателей, которые выражают взаимоотношения между элементами данных.
Дата добавления: 2016-02-24; просмотров: 1854;