Математическая постановка задачи кодирования
На этом шаге мы рассмотрим математическую постановку задачи кодирования.
Не обсуждая технических сторон передачи и хранения сообщения (т.е. того, каким образом фактически реализованы передача-прием последовательности сигналов или фиксация состояний), попробуем дать математическую постановку задачи кодирования.
Пусть:
· первичный алфавит A содержит N знаков со средней информацией на знак, определенной с учетом вероятностей их появления, I1(A) (нижний индекс отражает то обстоятельство, что рассматривается первое приближение, а верхний индекс в скобках указывает алфавит).
· исходное сообщение, представленное в первичном алфавите, содержит n знаков
· вторичный алфавит B пусть содержит M знаков со средней информационной емкостью I1(В).
· закодированное сообщение – m знаков.
Если исходное сообщение содержит I(A) информации, а закодированное – I(B), то условие обратимости кодирования, т.е. неисчезновения информации при кодировании, очевидно, может быть записано следующим образом:
I(A) 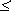 I(B),
I(B),
Смысл этого условия в том, что операция обратимого кодирования может увеличить количество формальной информации в сообщении, но не может его уменьшить.
Однако каждая из величин в данном неравенстве может быть заменена произведением числа знаков на среднюю информационную емкость знака, т.е.:

Отношение m/n характеризует среднее число знаков вторичного алфавита, которое приходится использовать для кодирования одного знака первичного алфавита – будем называть его длиной кода или длиной кодовой цепочки и обозначим
K(B)= m/n (верхний индекс указывает алфавит кодов).
В частном случае, когда появление любых знаков вторичного алфавита равновероятно, согласно формуле Хартли I1(B) =log2M, и тогда
 (1)
(1)
По аналогии с величиной R, характеризующей избыточность языка, можно ввести относительную избыточность кода Q:
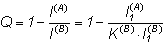 (2)
(2)
Данная величина показывает, насколько операция кодирования увеличила длину исходного сообщения.
Очевидно, чем меньше Q (т.е. чем ближе она к 0 или, что то же, I(B) ближе к I(A)), тем более выгодным оказывается код и более эффективной операция кодирования.
Выгодность кодирования при передаче и хранении – это экономический фактор, поскольку более эффективный код позволяет затратить на передачу сообщения меньше энергии, а также времени и, соответственно, меньше занимать линию связи; при хранении используется меньше площади поверхности (объема) носителя.
При этом следует сознавать, что выгодность кода не идентична временнóй выгодности всей цепочки кодирование – передача – декодирование;
Возможна ситуация, когда за использование эффективного кода при передаче придется расплачиваться тем, что операции кодирования и декодирования будут занимать больше времени и иных ресурсов (например, места в памяти технического устройства, если эти операции производятся с его помощью).
Выражение (1) пока следует воспринимать как соотношение оценочного характера, из которого неясно, в какой степени при кодировании возможно приближение к равенству его правой и левой частей.
По этой причине для теории связи важнейшее значение имеют две теоремы, доказанные Шенноном.
Первая –затрагивает ситуацию с кодированием при передаче сообщения по линии связи, в которой отсутствуют помехи, искажающие информацию. Вторая теорема относится к реальным линиям связи с помехами.
Первая теорема Шеннона, которая называется также основной теоремой о кодировании при отсутствии помех, формулируется следующим образом:
При отсутствии помех передачи всегда возможен такой вариант кодирования сообщения, при котором среднее число знаков кода, приходящихся на один знак кодируемого алфавита, будет сколь угодно близко к отношению средних информаций на знак первичного и вторичного алфавитов.
Используя понятие избыточности кода, можно дать более короткую формулировку теоремы:
При отсутствии помех передачи всегда возможен такой вариант кодирования сообщения, при котором избыточность кода будет сколь угодно близкой к нулю.
Данные утверждения являются теоремами и, следовательно, должны доказываться, однако доказательства мы опустим.
Для нас важно, что теорема открывает принципиальную возможность оптимального кодирования.
Однако необходимо сознавать, что из самой теоремы никоим образом не следует, как такое кодирование осуществить практически – для этого должны привлекаться какие-то дополнительные соображения.
Ограничим себя ситуацией, когда M = 2, т.е. для представления кодов в линии связи используется лишь два типа сигналов – с практической точки зрения это наиболее просто реализуемый вариант.
Например, существование напряжения в проводе (будем называть это импульсом) или его отсутствие (пауза);
наличие или отсутствие отверстия на перфокарте или намагниченной области на дискете);
Подобное кодирование называется двоичным. Знаки двоичного алфавита принято обозначать "0" и "1", но нужно воспринимать их как буквы, а не цифры.
Удобство двоичных кодов и в том, что при равных длительностях и вероятностях каждый элементарный сигнал (0 или 1) несет в себе 1 бит информации (log2M = 1);
Тогда из (1), теоремы Шеннона:
I1(A) K(2)
и первая теорема Шеннона получает следующую интерпретацию:
При отсутствии помех передачи средняя длина двоичного кода может быть сколь угодно близкой к средней информации, приходящейся на знак первичного алфавита.
Применение формулы (2) для двоичного кодирования дает:

Определение количества переданной информации при двоичном кодировании сводится к простому подсчету числа импульсов (единиц) и пауз (нулей).
При этом возникает проблема выделения из потока сигналов (последовательности импульсов и пауз) отдельных кодов. Приемное устройство фиксирует интенсивность и длительность сигналов.
Элементарные сигналы (0 и 1) могут иметь одинаковые или разные длительности.
Их количество в коде (длина кодовой цепочки), который ставится в соответствие знаку первичного алфавита, также может быть одинаковым (в этом случае код называется равномерным) или разным (неравномерный код).
Наконец, коды могут строиться для каждого знака исходного алфавита (алфавитное кодирование) или для их комбинаций (кодирование блоков, слов).
В результате при кодировании (алфавитном и словесном) возможны следующие варианты сочетаний:
Таблица 1. Варианты сочетаний
| Длительности элементарных сигналов | Кодировка первичных символов (слов) | Ситуация |
| одинаковые | равномерная | (1) |
| одинаковые | неравномерная | (2) |
| разные | равномерная | (3) |
| разные | неравномерная | (4) |
В случае использования неравномерного кодирования или сигналов разной длительности (ситуации (2), (3) и (4)) для отделения кода одного знака от другого между ними необходимо передавать специальный сигнал – временной разделитель (признак конца знака) или применять такие коды, которые оказываются уникальными, т.е. несовпадающими с частями других кодов.
При равномерном кодировании одинаковыми по длительности сигналами (ситуация (1)) передачи специального разделителя не требуется, поскольку отделение одного кода от другого производится по общей длительности, которая для всех кодов оказывается одинаковой (или одинаковому числу бит при хранении).
Длительность двоичного элементарного импульса (  ) показывает, сколько времени требуется для передачи 1 бит информации.
) показывает, сколько времени требуется для передачи 1 бит информации.
Очевидно, для передачи информации, в среднем приходящейся на знак первичного алфавита, необходимо время  .
.
Таким образом, задачу оптимизации кодирования можно сформулировать в иных терминах:
построить такую систему кодирования, чтобы суммарная длительность кодов при передаче (или суммарное число кодов при хранении) данного сообщения была бы наименьшей.
Дата добавления: 2015-07-22; просмотров: 1745;