Равномерное алфавитное двоичное кодирование.
6.1. Байтовый код
Двоичный код первичного алфавита строится цепочками равной длины, т.е. со всеми знаками связано одинаковое количество информации равное I0.
Передавать признак конца знака не требуется, поэтому для определения длины кодовой цепочки можно воспользоваться формулой:
K(2) 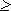 log2N.
log2N.
Приемное устройство просто отсчитывает определенное заранее количество элементарных сигналов и интерпретирует цепочку (устанавливает, какому знаку она соответствует).
Правда, при этом возможны сбои. Например, пропуск (непрочтение) одного элементарного сигнала приведет к сдвигу всей кодовой последовательности и неправильной ее интерпретации; Эта проблема решается путем синхронизации передачи или иными способами.
С другой стороны, применение равномерного кода оказывается одним из средств контроля правильности передачи, поскольку факт поступления лишнего элементарного сигнала или, наоборот, поступление неполного кода сразу интерпретируется как ошибка.
Примером использования равномерного алфавитного кодирования является
6.2. Представление символьной информации в компьютере.
Чтобы определить длину кода, необходимо начать с установления количество знаков в первичном алфавите. Компьютерный алфавит должен включать:
26 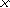 2=52 букв латинского алфавита (с учетом прописных и строчных);
2=52 букв латинского алфавита (с учетом прописных и строчных);
33 2=66 букв русского алфавита;
цифры 0...9 – всего 10;
знаки математических операций, знаки препинания, спецсимволы  20.
20.
Получаем, что общее число символов N  148. Теперь можно оценить длину кодовой цепочки:
148. Теперь можно оценить длину кодовой цепочки:
K(2) log2148 7,21.
Поскольку K(2) должно быть целым, очевидно, K(2)= 8.
Именно такой способ кодирования принят в компьютерных системах: любому символу ставится в соответствие цепочка из 8 двоичных разрядов (8 бит).
Такая цепочка получила название байт, а представление таким образом символов – байтовым кодированием.
Байт наряду с битом может использоваться как единица измерения количества информации в сообщении.
Один байт соответствует количеству информации в одном символе алфавита при их равновероятном распределении. Этот способ измерения количества информации называется также объемным.
Пусть имеется некоторое сообщение (последовательность знаков).
Оценка количества содержащейся в нем информации согласно рассмотренному ранее вероятностному подходу (с помощью формулы Шеннона ) дает Iвер, а объемная мера пусть равна Iоб; соотношение между этими величинами:
Iвер 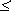 Iоб
Iоб
Именно байт принят в качестве единицы измерения количества информации в международной системе единиц СИ. 1 байт = 8 бит.
Наряду с байтом для измерения количества информации используются более крупные производные единицы:
1 Кбайт = 210 байт = 1024 байт (килобайт)
1 Мбайт = 220 байт = 1024 Кбайт (мегабайт)
1 Гбайт = 230 байт = 1024 Мбайт (гигабайт)
1 Тбайт = 240 байт = 1024 Гбайт (терабайт)
Использование 8-битных цепочек позволяет закодировать 28=256 символов, что превышает оцененное выше N и, следовательно, дает возможность употребить оставшуюся часть кодовой таблицы для представления дополнительных символов.
Однако стандартизация длины кода недостаточна, поскольку способов кодирования, т.е. вариантов сопоставления знакам первичного алфавита восьми битных цепочек, очень много.
Для обеспечения совместимости технических устройств и обеспечения возможности обмена информацией между многими потребителями требуется согласование (стандартизация) кодов, которое осуществляется в форме стандартных кодовых таблиц.
В персональных компьютерах и телекоммуникационных системах применяется международный байтовый код ASCII (American Standard Code for Information Interchange – "американский стандартный код обмена информацией").
Он регламентирует коды первой половины кодовой таблицы (номера кодов от 0 до 127, т.е. первый бит всех кодов 0).
В эту часть попадают коды прописных и строчных английских букв, цифры, знаки препинания и математических операций, а также некоторые управляющие коды (номера от 0 до 31). Ниже приведены некоторые ASCII-коды:
| Таблица 1. Некоторые ASCII-коды | ||
| Знак, клавиша | Код двоичный | Код десятичный |
| пробел | ||
| A (лат) | ||
| B (лат) | ||
| Z | ||
| Клавиша ESC |
Вторая часть кодовой таблицы – она считается расширением основной – охватывает коды в интервале от 128 до 255 (первый бит всех кодов 1).
Она используется для представления символов национальных алфавитов (например, русского или греческого), а также символов псевдографики.
Для этой части также имеются стандарты, например, для символов русского языка это КОИ–8, КОИ–7 и др.
КОИ-8 (код обмена информацией, 8 битов) — восьмибитовая ASCII-совместимая кодовая страница, разработанная для кодирования букв кириллических алфавитов.
Существует также семибитовая версия кодировки, не полностью совместимая с ASCII — КОИ-7.
Разработчики КОИ-8 поместили символы русского алфавита в верхней части кодовой таблицы таким образом, что позиции кириллических символов соответствуют их фонетическим аналогам в английском алфавите в нижней части таблицы.
Это означает, что если в тексте, написанном в КОИ-8, убирать восьмой бит каждого символа, то получается «читаемый» текст, хотя он и написан латинскими символами.
Например, слова «Русский Текст» превратились бы в «rUSSKIJ tEKST». Как побочное следствие, символы кириллицы оказались расположены не в алфавитном порядке.
Как в основной таблице, так и в ее расширении коды букв и цифр соответствуют их лексикографическому порядку (т.е. порядку следования в алфавите) – это обеспечивает возможность ускорения автоматизации обработки текстов.
В настоящее время появился и находит все более широкое применение еще один международный стандарт кодировки – Unicode.
Его особенность в том, что в нем использовано 16-битное кодирование, т.е. для представления каждого символа отводится 2 байта.
Такая длина кода обеспечивает включения в первичный алфавит 65536 знаков. Это, в свою очередь, позволяет создать и использовать единую для всех распространенных алфавитов кодовую таблицу.
Дата добавления: 2015-07-22; просмотров: 2263;