Синдромный метод декодирования ЦК
Достоинства синдромного метода:
· простота алгоритма кодирования,
· высокая скорость обработки информации (отсутствие задержки информации при декодировании).
I Табличное синдромное декодирование
Декодер должен указать место ошибки и выработать сигнал коррекции. Для этого вводят дешифратор синдрома, который вырабатывает на одном из n выходов логическую «1», при соответствующих сигналах на его входах.
Таблица синдромов
| Ошибка Е(х) | Синдром |
| х0→1000000 | 1→100 |
| х1→ 0100000 | х→010 |
| х2→ 0010000 | х2→001 |
| х3→ 0001000 | х+1→110 |
| х4→ 0000100 | х2+х→011 |
| х5→ 0000010 | х2+х+1→111 |
| х6→ 0000001 | х2+1→101 |
Пример: Код (7,4), Р(х)=1+х+х3, d0=3, tиспр=1 двоичный символ, F(x)=1111111.
Пусть ошибка проозошла в 4 разряде.
Схема декодера приведена на рисунке, а работа схемы – в таблице.
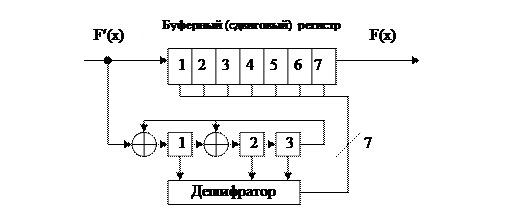
Таблица пошаговой работы схемы
| шаг | F¢(x) | F(x) | |||
 0 0
| |||||
 8 8
|
– начальное состояние
1i=3i-1ÅF¢(x)i
2i=1i-1Å3i-1
2→3 (3i=2i-1)
На n=7 такте получен синдром S(x)=110. Дешифратор определил ошибку Е(х)=0001000, следовательно, номер ошибочного бита =4. Дешифратор выдал исправляющий сигнал в соответствующий регистр. На 8…14 тактах выдается исправленное слово F(x)=1111111.
Недостатком табличного синдромного декодирования является то, что при сравнительно малом числе исправляемых ошибок схема очень сложна. Процесс может быть упрощен, за счет перехода к последовательному режиму работы, который используется в схемном синдромном декодировании.
II Схемное синдромное декодирование
Принятая кодовая последовательность поступает на сдвиговый буферный регистр и на схеме вычисляется остаток. Для исправления ошибок требуется образовать некоторое подмножество синдромов, соответствующее расположению ошибок. Удобно взять такое расположение ошибок, когда эти символы находятся на нулевых позициях в крайней правой точке буферного регистра.
Операцию определения декодируемого синдрома называют селекцией, а устройство селектором.
Для коррекции одиночной ошибки селектор в декодере циклических кодов должен быть настроен на комбинацию (00...01), причем единица расположена в старшем разряде делителя.
В качестве контрольного устройства (КУ) используется многотактный фильтр.
Пример: Код (7,4), F(x)=1111111.
Пусть ошибка проозошла в 4 разряде.
Схема декодера приведена на рисунке, а работа схемы – в таблице.
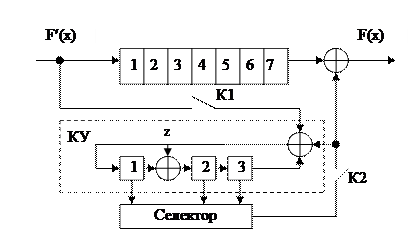
Таблица пошаговой работы схемы
| шаг | F¢(x) | z | F(x) | |||
| 0
| ||||||
 1 1
| ||||||
 0 0
| ||||||
| 1
| ||||||
– начальное состояние
До 7 такта: К1 – замкнут, К2 – разомкнут
zi= F¢(x)iÅ3i-1
z→1 (1i=zi)
2i=1i-1Åzi
2→3 (3i=2i-1)
C 8 такта: К1 – разомкнут, К2 – замкнут
Получена селектируемая комбинация, на 11 такте сработает селектор
Получили F(x)=1111111
Схема декодирующего устройства состоит из семиразрядного буферного регистра, трехразрядного делителя и селектора, настроенного на комбинацию (001). Последовательность F¢(x) записывается в n-разрядный (n=7) буферный регистр, так что через 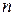 =7 тактов все слово оказывается записанным в регистр. Одновременно последовательность поступает в контрольное устройство (делитель на Р(х)), которое производит вычисление синдрома (остатка от деления, если R(х)≠0, следовательно, произошла ошибка). Селектор анализирует полученный остаток и выдает корректирующий сигнал в тот момент, когда ошибочный символ покидает буферный регистр. Если после 2n=2×4=14 сдвигов, т.е. когда последний символ покидает буферный регистр, состояние контрольного устройства будет ненулевым, это означает, что произошла некорректируемая ошибка.
=7 тактов все слово оказывается записанным в регистр. Одновременно последовательность поступает в контрольное устройство (делитель на Р(х)), которое производит вычисление синдрома (остатка от деления, если R(х)≠0, следовательно, произошла ошибка). Селектор анализирует полученный остаток и выдает корректирующий сигнал в тот момент, когда ошибочный символ покидает буферный регистр. Если после 2n=2×4=14 сдвигов, т.е. когда последний символ покидает буферный регистр, состояние контрольного устройства будет ненулевым, это означает, что произошла некорректируемая ошибка.
В общем случае декодирующее устройство получается значительно более сложным, чем в рассмотренном примере, так как с увеличением длины кода и кратности исправляемых ошибок число селектируемых комбинаций возрастает. Уже при исправлении двойных ошибок сложность селектора превышает сложность контрольного устройства. Поэтому рассмотренное декодирующее устройство находит в основном применение для исправления ошибок малой кратностью t£ 2, а также для обнаружения ошибок.
Дата добавления: 2019-04-03; просмотров: 519;