Контекстно-свободные грамматики и автоматы с магазинной памятью
Синтаксический анализ.
Пусть G = (N, T, P, S) - КС-грамматика. Введем несколько важных понятий и определений.
Вывод, в котором в любой сентенциальной форме на каждом шаге делается подстановка самого левого нетерминала, называетсялевосторонним. Если S=>* u в процессе левостороннего вывода, то u - левая сентенциальная форма. Аналогично определим правосторонний вывод. Обозначим шаги левого (правого) вывода =>l (=>r).
Упорядоченным графом называется пара (V,E), где V есть множество вершин, а E - множество линейно упорядоченных списков дуг, каждый элемент которого имеет вид ((v, v1), (v, v2), ... , (v, vn)). Этот элемент указывает, что из вершиныv выходят n дуг, причем первой из них считается дуга, входящая в вершину v1, второй - дуга, входящая в вершину v2, и т.д.
Упорядоченным помеченным деревом называется упорядоченный граф (V,E), основой которого является дерево и для которого определена функция f : V -> F (функция разметки) для некоторого множества F.
Упорядоченное помеченное дерево D называется деревом вывода (или деревом разбора ) цепочки w в КС-грамматике G = (N, T, P, S), если выполнены следующие условия:
(1) корень дерева D помечен S ;
(2) каждый лист помечен либо 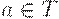 , либо e ;
, либо e ;
(3) каждая внутренняя вершина помечена нетерминалом  ;
;
(4) если X - нетерминал, которым помечена внутренняя вершина и X1, ... , Xn - метки ее прямых потомков в указанном порядке, то X -> X1 ... Xk - правило из множества P ;
(5) Цепочка, составленная из выписанных слева направо меток листьев, равна w.
Процесс определения принадлежности данной строки языку, порождаемому данной грамматикой, и, в случае указанной принадлежности, построение дерева разбора для этой строки, называется синтаксическим анализом. Можно говорить о восстановлении дерева вывода (в частности, правостороннего или левостороннего) для строки, принадлежащей языку. Повосстановленному выводу можно строить дерево разбора.
Грамматика G называется неоднозначной, если существует цепочка w, для которой имеется два или более различных деревьев вывода в G.
Грамматика G называется леворекурсивной, если в ней имеется нетерминал A такой, что для некоторой цепочки R существуетвывод 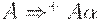 .
.
Автомат с магазинной памятью (МП-автомат) - это семерка 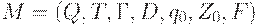 , где
, где
(1) Q - конечное множество состояний, представляющих всевозможные состояния управляющего устройства;
(2) T - конечный входной алфавит;
(3) 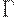 - конечный алфавит магазинных символов ;
- конечный алфавит магазинных символов ;
(4) D - отображение множества 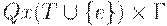 в множество конечных подмножеств
в множество конечных подмножеств 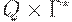 , называемоефункцией переходов ;
, называемоефункцией переходов ;
(5)  - начальное состояние управляющего устройства;
- начальное состояние управляющего устройства;
(6) 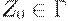 - символ, находящийся в магазине в начальный момент ( начальный символ магазина );
- символ, находящийся в магазине в начальный момент ( начальный символ магазина );
(7) 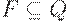 - множество заключительных состояний.
- множество заключительных состояний.
Конфигурация МП-автомата - это тройка (q, w, u), где
(1) 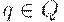 - текущее состояние управляющего устройства;
- текущее состояние управляющего устройства;
(2) 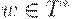 - непрочитанная часть входной цепочки; первый символ цепочки w находится под входной головкой; если w = e, то считается, что вся входная лента прочитана;
- непрочитанная часть входной цепочки; первый символ цепочки w находится под входной головкой; если w = e, то считается, что вся входная лента прочитана;
(3) 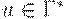 - содержимое магазина; самый левый символ цепочки u считается верхним символом магазина; если u = e, то магазин считается пустым.
- содержимое магазина; самый левый символ цепочки u считается верхним символом магазина; если u = e, то магазин считается пустым.
Такт работы МП-автомата M будем представлять в виде бинарного отношения 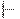 , определенного на конфигурациях.
, определенного на конфигурациях.
Будем писать
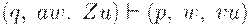
если множество D(q, a, Z) содержит (p, v), где 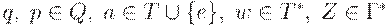 и
и 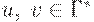 (верхушка магазина слева).
(верхушка магазина слева).
Начальной конфигурацией МП-автомата M называется конфигурация вида (q0, w, Z0), где , то есть управляющее устройство находится в начальном состоянии, входная лента содержит цепочку, которую нужно проанализировать, а в магазине имеется только начальный символ Z0.
>Заключительной конфигурацией называется конфигурация вида (q, e, u), где 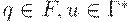 , то есть управляющее устройство находится в одном из заключительных состояний, а входная цепочка целиком прочитана.
, то есть управляющее устройство находится в одном из заключительных состояний, а входная цепочка целиком прочитана.
Введем транзитивное и рефлексивно-транзитивное замыкание отношения , а также его степень k > 0 (обозначаемые 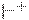 ,
, 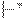 и
и 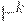 соответственно).
соответственно).
Говорят, что цепочка w допускается МП-автоматом M, если 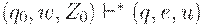 для некоторых
для некоторых 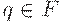 и .
и .
Множество всех цепочек, допускаемых автоматом M называется языком, допускаемым (распознаваемым, определяемым) автоматомM (обозначается L(M) ).
Пример 4.1. Рассмотрим МП-автомат
M = ({q0, q1, q2}, {a, b}, {Z, a, b}, D, q0, Z, {q2}),
у которого функция переходов D содержит элементы:
D(q0, a, Z) = {(q0, aZ)},D(q0, b, Z) = {(q0, bZ)},D(q0, a, a) = {(q0, aa), {q1, e)},D(q0, a, b) = {(q0, ab)},D(q0, b, a) = {(q0, ba)},D(q0, b, b) = {(q0, bb), (q1, e)},D(q1, a, a) = {(q1, e)},D(q1, b, b) = {(q1, e)},D(q1, e, Z) = {(q2, e)}.Нетрудно показать, что 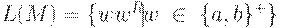 , где wR обозначает обращение ("переворачивание") цепочки w.
, где wR обозначает обращение ("переворачивание") цепочки w.
Иногда допустимость определяют несколько иначе: цепочка w допускается МП-автоматом M, если 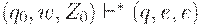 для некоторого . В таком случае говорят, что автомат допускает цепочкуопустошением магазина. Эти определения эквивалентны, ибо справедлива
для некоторого . В таком случае говорят, что автомат допускает цепочкуопустошением магазина. Эти определения эквивалентны, ибо справедлива
опустошением магазина.
Доказательство. Пусть L = L(M) для некоторого МП- автомата . Построим новый МП-автомат M', допускающий тот же язык опустошением магазина.
Пусть 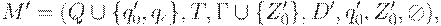 где функция переходов D' определена следующим образом:
где функция переходов D' определена следующим образом:
1. Если 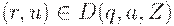 , то
, то 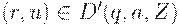 для всех
для всех 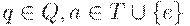 и
и 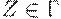 (моделирование М ),
(моделирование М ),
2. 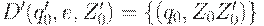 (начало работы),
(начало работы),
3. Для всех и 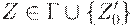 множество D'(q, e, Z) содержит (qe, e) (переход в состояние сокращения магазина без продвижения),
множество D'(q, e, Z) содержит (qe, e) (переход в состояние сокращения магазина без продвижения),
4. D'(qe, e, Z) = {(qe, e)} для всех , (сокращение магазина).
Автомат сначала переходит в конфигурацию 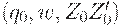 соответственно определению D' в п.2, затем в
соответственно определению D' в п.2, затем в 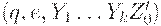 ,
,
соответственно п.1, затем в 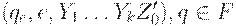 соответственно п.3, затем в (qe, e, e)соответственно п.4. Нетрудно показать по индукции, что
соответственно п.3, затем в (qe, e, e)соответственно п.4. Нетрудно показать по индукции, что 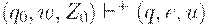 (где ) выполняется для автомата M тогда и только тогда, когда
(где ) выполняется для автомата M тогда и только тогда, когда 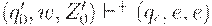 выполняется для автомата M'. Поэтому L(M) = L', где L' - язык, допускаемый автоматом M' опустошением магазина.
выполняется для автомата M'. Поэтому L(M) = L', где L' - язык, допускаемый автоматом M' опустошением магазина.
Обратно, пусть 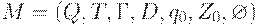 - МП - автомат, допускающий опустошением магазина язык L. Построим автомат M', допускающий тот же язык по заключительному состоянию.
- МП - автомат, допускающий опустошением магазина язык L. Построим автомат M', допускающий тот же язык по заключительному состоянию.
Пусть 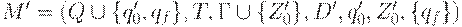 , где D' определяется следующим образом:
, где D' определяется следующим образом:
1. - переход в "режим M ",
2. Для каждого 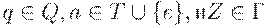 определим
определим 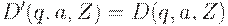 - работа в "режиме M " ,
- работа в "режиме M " ,
3. Для всех 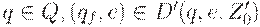 - переход в заключительное состояние.
- переход в заключительное состояние.
Нетрудно показать по индукции, что L = L(M'). Одним из важнейших результатов теории контекстно-свободных языков являетсядоказательство эквивалентности МП-автоматов и КС-грамматик.
Теорема 4.2. Язык является контекстно-свободным тогда и только тогда, когда он допускается МП-авто- матом.
Доказательство. Пусть G = (N, T, P, S) - КС-граммати- ка. Построим МП-автомат, допускающий язык L(G) опустошением магазина.
Пусть 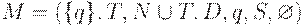 , где D определяется следующим образом:
, где D определяется следующим образом:
1. Если 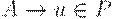 , то
, то 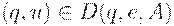 ,
,
2. D(q, a, a) = {(q, e)} для всех .
Фактически, этот МП-автомат в точности моделирует все возможные выводы в грамматике G. Нетрудно показать по индукции, что для любой цепочки вывод S =>+w в грамматике G существует тогда и только тогда, когда существует последовательность тактов 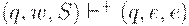 автомата M.
автомата M.
Наоборот, пусть дан - МП- автомат, допускающий опустошением магазина язык L.
Построим грамматику G, порождающую язык L.
Пусть 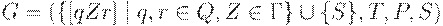 , где P состоит из правил следующего вида:
, где P состоит из правил следующего вида:
1. 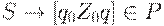 для всех .
для всех .
2. Если 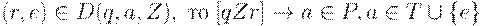 ,
,
3. Если 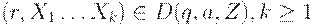 , то
, то
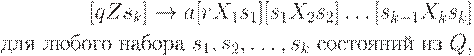
Нетерминалы и правила вывода грамматики определены так, что работе автомата M при обработке цепочки w соответствует левосторонний вывод w в грамматике G.
Индукцией по числу шагов вывода в G или числу тактов M нетрудно показать, что 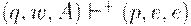 тогда и только тогда, когда [qAp] =>+ w.
тогда и только тогда, когда [qAp] =>+ w.
Тогда, если 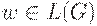 , то S => [q0Z0q] =>+ w для некоторого . Следовательно,
, то S => [q0Z0q] =>+ w для некоторого . Следовательно, 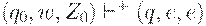 и поэтому
и поэтому 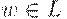 . Аналогично, если , то
. Аналогично, если , то 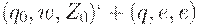 . Значит, S =>[q0Z0q] =>+ w, и поэтому .
. Значит, S =>[q0Z0q] =>+ w, и поэтому .
МП-автомат называется детерминированным (ДМП-автоматом), если выполнены два следующих условия:
(1) Множество D(q, a, Z) содержит не более одного элемента для любых 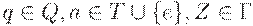 ;
;
(2) Если 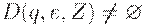 , то
, то 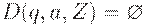 для всех .
для всех .
Допускаемый ДМП-автоматом язык называется детерминированным КС-языком.
Так как функция переходов ДМП-автомата содержит не более одного элемента для любой тройки аргументов, мы будем пользоваться записью D(q, a, Z) = (p, u) для обозначения D(q, a, Z) = {(p, u)}.
Пример 4.2. Рассмотрим ДМП-автомат
M = ({q0, q1, q2}, {a, b, c}, {Z, a, b}, D, q0, Z, {q2}),
функция переходов которого определяется следующим образом:
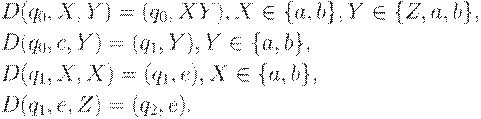
Нетрудно показать, что этот детерминированный МП-автомат допускает язык 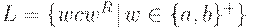 .
.
К сожалению, ДМП-автоматы имеют меньшую распознавательную способность, чем МП-автоматы. Доказано, в частности, что существуют КС-языки, не являющиеся детерминированными КС-языками (таковым, например, является язык из примера 4.1).
Рассмотрим еще один важный вид МП-автомата.
Расширенным автоматом с магазинной памятью назовем семерку , где смысл всех символов тот же, что и для обычного МП-автомата, кроме D, представляющего собой отображение конечного подмножествамножества 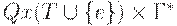 во множество конечных подмножеств множества . Все остальные определения (конфигурации, такта, допустимости) для расширенного МП-автомата остаются такими же, как для обычного.
во множество конечных подмножеств множества . Все остальные определения (конфигурации, такта, допустимости) для расширенного МП-автомата остаются такими же, как для обычного.
Теорема 4.3. Пусть - расширенный МП-автомат. Тогда существует МП- автомат M' , такой, что L(M') = L(M).
Расширенный МП-автомат называется детерминированным, если выполнены следующие условия:
(1) Множество D(q, a, u) содержит не более одного элемента для любых 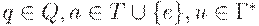 ,
,
(2) Если 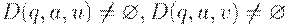 и
и 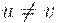 , то не существует цепочки x такой, что u = vx или v = ux,
, то не существует цепочки x такой, что u = vx или v = ux,
(3) Если 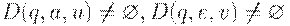 , то не существует цепочки x такой, что u = vx или v = ux.
, то не существует цепочки x такой, что u = vx или v = ux.
Теорема 4.4. Пусть - расширенный ДМП-автомат. Тогда существует ДМП- автомат M', такой, что L(M') = L(M).
ДМП-автомат и расширенный ДМП-автомат лежат в основе рассматриваемых далее в этой главе, соответственно, LL- и LR-анализаторов.
Определение. Говорят, что КС-грамматика находится в нормальной форме Хомского, если каждое правило имеет вид:
(1) либо A -> BC, A, B, C - нетерминалы,
(2) либо A -> a, a - терминал,
(3) либо S -> e и в этом случае S - не встречается в правых частях правил.
Утверждение. Любую КС-грамматику можно преобразовать в эквивалентную ей в нормальной форме Хомского.
Утверждение. Если КС-грамматика находится в нормальной форме Хомского, тогда для любой цепочки 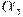 если
если 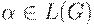 и m - высота дерева вывода с кроной
и m - высота дерева вывода с кроной 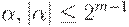 .
.
Теорема 4.5. (Лемма о разрастании для контекстно- свободных языков). Для любого КС-языка L существуют такие целые l и k,что любая цепочка 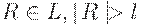 , представима в виде R = uvwxy, где
, представима в виде R = uvwxy, где
(1) |vwx| <= k
(2) 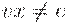
(3) 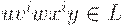 для любого i >= 0.
для любого i >= 0.
Доказательство. Пусть L = L(G), где 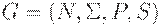 - контекстно- свободная грамматика в нормальной форме Хомского. Обозначим через n число нетерминалов, т.е. n = |N|, и рассмотрим l = 2n и k = 2n+1.
- контекстно- свободная грамматика в нормальной форме Хомского. Обозначим через n число нетерминалов, т.е. n = |N|, и рассмотрим l = 2n и k = 2n+1.
Для доказательства того, что l и k удовлетворяют условию теоремы, рассмотрим произвольную цепочку  , для которой
, для которой 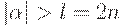 . В силу Утверждения получаем, что высота дерева с кроной
. В силу Утверждения получаем, что высота дерева с кроной 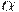 больше n + 1 и есть путь по дереву (обозначим его через P ), который проходит более чем через n + 1 вершин. Отсюда по определению дерева вывода имеем, что P содержит более n вершин, помеченных нетерминалами. Таким образом, существует нетерминал, который метит не менее двух вершин пути P. Среди всех таких нетерминалов пусть A - такой, что его вхождение, ближайшее к листу, не содержит других нетерминалов, обладающих этим свойством (если бы это было не так, то выбрали бы этот другой). Пусть q - вхождение A, ближайшее к листу, p - расположенное выше. Представим крону в виде uvwxy, где w - крона поддерева D1 с корнем q иvwx - крона поддерева D2 с корнем p. Тогда высота поддерева D2 не более (n - 1) + 2 + 1 = n + 2, так что |vwz| <= 2n+1.
больше n + 1 и есть путь по дереву (обозначим его через P ), который проходит более чем через n + 1 вершин. Отсюда по определению дерева вывода имеем, что P содержит более n вершин, помеченных нетерминалами. Таким образом, существует нетерминал, который метит не менее двух вершин пути P. Среди всех таких нетерминалов пусть A - такой, что его вхождение, ближайшее к листу, не содержит других нетерминалов, обладающих этим свойством (если бы это было не так, то выбрали бы этот другой). Пусть q - вхождение A, ближайшее к листу, p - расположенное выше. Представим крону в виде uvwxy, где w - крона поддерева D1 с корнем q иvwx - крона поддерева D2 с корнем p. Тогда высота поддерева D2 не более (n - 1) + 2 + 1 = n + 2, так что |vwz| <= 2n+1.
Также очевидно, что , поскольку в силу определения нормальной формы Хомского p имеет двух сыновей, помеченных нетерминалами, из которых не выводится пустая цепочка.
Кроме того, S =>* u Ay =>* uvAxy =>* uvwxy, а также A =>* vAx =>* vwx. Отсюда получаем A =>* viwxi для всех i >= 0 иS =>* uviwxiy для всех i >= 0.
Пример. Покажем, что язык L = {anbncn|n>=1} не является контекстно-свободным языком.
Если бы он был КС-языком, то мы взяли бы константу k, которая определяется в лемме о разрастании. Пусть z = akbkck. Тогдаz = uvwxy. Так как |vwx| <= k, то в цепочке vwx не могут быть вхождения каждого из символов a, b и c. Таким образом, цепочка uwy, которая по лемме о разрастании принадлежит L, содержит либо k символов a, либо k символов c. Но она не может иметь k вхождений каждого из символов a, b и c, потому, что |uwy| < 3k. Значит, вхождений какого-то из этих символов в uwy больше, чем другого и, следовательно, 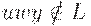 . Полученное противоречие позволяет заключить, что L - не КС-язык.
. Полученное противоречие позволяет заключить, что L - не КС-язык.
Дата добавления: 2016-06-13; просмотров: 2226;