Корреляционный и регрессионный анализ
Корреляционный и регрессионный анализ — это два близких метода, которые обычно используются совместно для исследования взаимосвязи между двумя или более непрерывными переменными.
Результаты корреляционного анализа позволяют делать статистические выводы о степени зависимости между переменными.
Величина линейной зависимости между двумя переменными измеряется посредством простого коэффициента корреляции, величина зависимости от нескольких — посредством множественного коэффициента корреляции.
В корреляционном анализе используется также понятие частного коэффициента корреляции, который измеряет линейную взаимосвязь между двумя переменными без учета влияния других переменных.
Если корреляционный анализ позволил установить наличие линейной зависимости наблюдаемой переменной от одной или более независимых, то форма зависимости может быть уточнена методами регрессионного анализа.
Для этого строится так называемое уравнение регрессии, которое связывает зависимую переменную с независимыми и содержит неизвестные параметры. Если уравнение линейно относительно параметров (но необязательно линейно относительно независимых переменных), то говорят о линейной регрессии, в противном случае регрессия нелинейна.
Поэтому результаты корреляционного анализа целесообразно уточнить, проведя регрессионный анализ.
Регрессионный анализ позволяет решать две задачи:
1. устанавливать наличие возможной причинной связи между переменными;
2. предсказывать значения переменной по значениям независимых переменных (эта возможность особенно важна в тех случаях, когда прямые измерения зависимой переменной затруднены).
Если предполагается линейная зависимость между х и у, то она может быть описана уравнением, которое называется простой линейной регрессией у по х, вида:
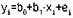
Здесь i=1......... n; n — объем испытаний;
величины b0 и b1 являются неизвестными параметрами;
ei — случайные ошибки испытаний.
Цель регрессионного анализа — найти наилучшие в статистическом смысле оценки параметров b0 и b1 (величину b1 обычно называют коэффициентом регрессии).
Зная значения b0 и b1, можно найти оценку переменной у при x=xi:
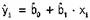
Каким же образом полученное уравнение (или, как говорят, регрессионная модель) может быть использовано для прогнозирования значений зависимой переменной у?
Чтобы ответить на этот вопрос, воспользуемся приводившимся уже примером, связанным с оценкой надежности компьютера. Предположим, исследователю удалось посредством дисперсионного анализа установить наличие зависимости среднего числа отказов от интенсивности обращений к жесткому диску. Предположим также, что корреляционный анализ позволил определить линейный характер этой зависимости. В этом случае, имея уравнение регрессии, связывающее указанные величины, можно для каждого конкретного значения интенсивности обращений к диску «спрогнозировать» соответствующее среднее число отказов.
Разница между наблюдаемым и оцененным значением у при x=xiназывается отклонением (или остатком) di=yi - y'i. Величины отклонений могут быть использованы для проверки адекватности полученной модели. Для этого строится график d=f (у) или d=f (х) (рис. 2.22) и по его виду делается предварительное заключение о степени адекватности модели.
В случае нескольких независимых переменных имеет место множественная линейная регрессия:
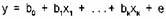
В этом случае для отыскания оценок bi также используется метод наименьших квадратов (МНК).
В случае нелинейной регрессии основой для построения регрессионной модели опять-таки является МНК. Однако в этом случае для отыскания оценок bj строится система нелинейных уравнений (относительно bj), а для ее решения используются различные итерационные методы.
Эффективное использование процедур статистического анализа экспериментальных данных возможно только в том случае, если в распоряжении исследователя имеются соответствующие инструментальные средства, к описанию которых мы теперь можем перейти. Но прежде подведем краткий итог изложенному в этом уроке.
Таким образом: в тех случаях, когда поведение исследуемой системы зависит от воздействия большого числа случайных факторов, либо интерес представляет развитие ситуации во времени, удобнее всего использовать имитационные модели. Основная особенность таких моделей — обеспечение возможности проведения статистического эксперимента.
· В зависимости от того, какие аспекты поведения исследуемой системы или операции вас интересуют, ее модель может быть описана либо как последовательность событий, либо как совокупность взаимодействующих процессов, либо как последовательность операций обслуживания транзактов.
· Создание имитационной модели сложной системы, функционирование которой предполагает наличие параллельных процессов, является весьма сложным делом, требующим от разработчика не только хорошего знания рассматриваемой предметной области, но достаточно прочных навыков в программировании.
· Результаты имитационного эксперимента могут быть использованы для принятия решения лишь при условии их корректной статистической обработки, что предъявляет к уровню подготовки исследователя целый ряд дополнительных требований.
· Существенное повышение технологичности подготовки, проведения и анализа результатов имитационного моделирования возможно в том случае, если в распоряжении исследователя имеются соответствующие инструментальные средства.
Дата добавления: 2016-02-13; просмотров: 871;