Язык управления выбором данных
Вторым типом управления является управление данными, которые динамически меняются в процессе вывода. В общем случае это управление состоит в выборе подстановки или порядке обработки данных, что может существенно влиять на результат вывода в системе.
Традиционным способом задания стратегии обработки является фиксация типов данных и программирование "вручную" способа их обработки. Такое управление данными называют встроенным. Например, в различных версиях лингвистических процессоров использовались разнообразные встроенные порядки обработки строк: слева направо, справа налево, с возвратом на начало строки, без возврата и их комбинации. Если над обрабатываемыми данными зафиксировано отношение частичного порядка, то примером могут служить переборы в глубину и в ширину.
Основной недостаток встроенной стратегии обработки данных состоит в том, что пользователь вынужден настраивать свои предметные знания на заданную стратегию поиска, которая, как правило, не является единственно возможной и единственно оправданной.
Более естественным является такой способ описания предметной области, при котором эксперт, не связанный жесткой стратегией, формулирует сначала продукции и лишь после этого — правила обхода структур данных, используя, если необходимо в разных фрагментах данных различные стратегии. Такой способ задания управления данными называют настраиваемым. Он задается в виде лаконичной спецификации на языке управления данными.
Неформально язык управления данными аналогичен языку управления применением продукций и состоит в следующем.
Для каждого текущего состояния базы данных dr шага вывода r задается подмножество данных 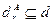 , на которых (и только на них) в текущий момент вывода проверяются условия применимости активированных продукций. Такие
, на которых (и только на них) в текущий момент вывода проверяются условия применимости активированных продукций. Такие 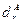 будем называть активированными данными. Поскольку данные в процессе вывода изменяются (добавляются новые и, возможно, исключаются старые факты), то описать множества статически до начала вывода невозможно, в связи, с чем необходимы средства динамического задания множеств .
будем называть активированными данными. Поскольку данные в процессе вывода изменяются (добавляются новые и, возможно, исключаются старые факты), то описать множества статически до начала вывода невозможно, в связи, с чем необходимы средства динамического задания множеств .
Будем определять управление данными по некоторому выделенному отношению f0 Î F над термами, которое задает структуру M(dr, f0)Í dr зависящую от текущего состояния dr и f0. В этой структуре между элементами определяется как минимальная длина пути между ними, а пара (центр, радиус), где центр — произвольный элемент структуры, радиус — натуральное число, задает в этой структуре окрестность поиска, содержащую в себе все элементы структуры, расстояние до которых от центра не больше радиуса окрестности. Множество активированных данных составляют те факты из текущего dr,в которые входят термы, принадлежащие окрестности поиска. Окрестность поиска называют иногда "окном активации".
Центр и радиус текущей окрестности могут быть заданы явно (точным указанием) либо вычисляться через центр и радиус окрестности, определенные над структурой предыдущего шага вывода. В результате применения продукций формируется dr+1 состояние базы, которое получается из dr добавлением или вычеркиванием некоторых фактов.
Рассмотрим вывод в окрестности на некотором произвольном шаге т. Пусть dr — текущее состояние базы данных, Wr — окрестность поиска шага вывода r. Если окрестность не пуста, то в ней проверяются условия применимости активированных продукций шага вывода r. Продукции с истинными условиями применяются, что приводит к состоянию dr+1. Если dr+1 содержит специальный выделенный символ неудачного вывода l, то вывод "зависает". В противном случае и тогда, когда текущая окрестность поиска пуста, происходит формирование Wr+1 окрестности поиска, центр и радиус которой вычисляются через соответствующие компоненты Wr, а активированные данные берутся из текущего dr+1 состояния базы данных. Если Wr+1 содержит специальный выделенный символ конца, то происходит остановка, означающая конец описания стратегии, а полученное состояние базы данных содержит результат, выводимый продукциями из заданного начального состояния по фиксированному порядку обработки данных.
Описанные выше языки управления выводом предназначены для двух основных целей. С одной стороны, они являются достаточно простым и лаконичным средством определения требований и спецификации логики поведения систем продукций, с другой — это точки настройки в программных реализациях, дающие основу для построения технологического пакета систем продукций. В рамках этого пакета каждая из точек настройки интерпретируется соответствующим механизмом (особенно на этапе отладки системы), а наиболее часто встречающиеся дисциплины применения продукций и порядки обработки данных встраиваются в технологический пакет в виде стандартных модулей. Спецификация соответствующей формулы вызывает эти модули и собирает необходимую конфигурацию.
Дата добавления: 2016-03-05; просмотров: 727;