Текстологические методы
Группа текстологических методов объединяет методы извлечения знаний, основанные на изучении специальных текстов из учебников, монографий, статей, методик и других носителей профессиональных знаний.
В буквальном смысле текстологические методы не относятся к текстологии, науке, которая родилась в русле филологии с целью критического прочтения литературных текстов, изучения и интерпретации источников с узко прикладной задаче - подготовки текстов к изданию. Сейчас текстология расширила свои границы включением аспектов смежных наук - герменевтики (науки правильного толкования древних текстов - библии, античных рукописей и др.), семиотики, психолингвистики и др.
Текстологические методы извлечения знаний, безусловно, используя основные положения текстологии, отличаются принципиально от ее методологии, во-первых, характером и природой своих источников (профессиональная специальная литература, а не художественная, живущая по своим особым законам), а во-вторых, жесткой прагматической направленностью извлечения конкретных профессиональных знаний.
Среди методов извлечения знаний эта группа является наименее разработанной, по ней практически нет никакой библиографии, поэтому дальнейшее изложение ни в коей мере не претендует на полноту.
Задачу извлечения знаний из текстов можно сформулировать как задачу понимания и выделения смысла текста. Сам текст на естественном языке является лишь проводников смысла, а замысел и знания автора лежат во вторичной структуре (смысловой структуре или макроструктуре текста), настраиваемой над естественным текстом. «Текст не содержит и не передает смысл, а является лишь инструментом для автора текста».
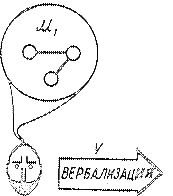
|
| Эксперт |
|

|
| Аналитик |
Рис. ?. Схема извлечения знаний из специальных текстов
Можно выделить две такие смысловые структуры: M1 - смысл, который пытался заложить автор, это его модель мира, и М2 - смысл, который постигает читатель, в данном случае инженер по знаниям (аналитик) в процессе интерпретации 1, При этом Т - это словесное одеяние M1, т. е. результат вербализации V.
Сложность процесса заключается в принципиальной невозможности совпадения знаний, образующих M1 и М2, из-за того, что М1 образуется за счет всей совокупности представлений, потребностей, интересов и опыта автора, лишь малая часть которых находит отражение в тексте Т. Соответственно и М2 образуется в процессе интерпретации текста Т за счет привлечения всей совокупности научного и человеческого багажа читателя. Таким образом, два инженера по знаниям извлекут из одного Т две различные модели М2i и М2j.
Встает задача: выяснить, за счет чего можно достичь максимальной адекватности M1 и М2, помня при этом, что понимание всегда относительно, поскольку это синтез двух смыслов «свое - чужое».
Рассмотрим подробнее, какие источники питают модель M1 и создают текст Т. Существуют два компонента любого научного текста. Это первичный материал наблюдений a и система научных понятий b в момент создания текста. В дополнение к этому, помимо объективных данных экспериментов и наблюдений, в тексте обязательно присутствуют субъективные взгляды автора g, результат его личного опыта, а также некоторые «общие места» или «вода» d, кроме этого, любой научный текст содержит заимствования из других источников (статей, монографий и т. д.) q. При этом все компоненты погружены в языковую среду L. Можно записать
Т = (a, b, g, d, q )L.
Таким образом, компоненты научного текста Т:
- наблюдения - a
- научные понятия - b
- субъективные взгляды - g
- общие места - d
- заимствования - q
При этом компоненты a,g, часть а входят и в модель М1.
При извлечении знаний аналитику, интерпретирующему текст, приходится решать задачу декомпозиции этого текста (на перечисленные выше компоненты для выделения истинно значимых для реализации базы знаний фрагментов). Сложность интерпретации научных и специальных текстов заключается еще и в том, что любой текст приобретает смысл только в контексте, где под контекстом понимается окружение, в которое «погружен» текст.
Различают микро- и макроконтекст. Микроконтекст – это ближайшее окружение текста. Так, предложение получает смысл в контексте абзаца, абзац в (контексте главы и т. д. Макроконтекст - это вся система знаний, связанная с предметной областью (т. е. знания об особенностях и свойствах, явно не указанных в тексте). Другими словами, любое знание обретает смысл в контексте некоторого метазнания.
Теперь несколько подробнее о центральном звене процедуры извлечения знания - о понимании текста, классическим в текстологии является определение немецкого философа и языковеда В. фон Гумбольдта:
«...Люди понимают друг друга не потому, что передают собеседнику знаки предметов, и даже не потому, что взаимно настраивают друг друга на точное и полное воспроизведение идентичного понятия, а потому, что взаимно затрагивают друг в друге одно и то же звено цепи чувственных представлений и зачатков внутренних понятий, прикасаются к одним и тем же клавишам инструмента своего духа, благодаря чему у каждого вспыхивает в сознании соответствующие, но не тождественные смыслы».
Говоря на языке современного языкознания, понимание - это формирование «второго текста», т.е. семантической структуры (понятийной структуры). В нашей терминологии - это попытка воссоздания семантической структуры M1 в процессе формирования модели М2, т. е. это первый шаг структурирования знаний.
Как происходит процесс понимания? Изложим одну из возможных схем. Эта схема согласуется со стратегией изучения всего нового. Основными моментами понимания текста являются:
1. Выдвижение предварительной гипотезы о смысле всего текста (предугадывание).
2. Определение значений непонятных слов (т. е. специальной терминологии).
3. Возникновение общей гипотезы о содержании текста (о знаниях).
4. Уточнение значения терминов и интерпретация отдельных фрагментов текста под влиянием общей гипотезы (от целого к частям).
5. Формирование некоторой смысловой структуры текста за счет установления внутренних связей между отдельными важными (ключевыми) словами и фрагментами, а также за счет образования абстрактных понятий, обобщающих конкретные фрагменты знаний.
6. корректировка общей гипотезы относительно содержащихся в тексте фрагментов знаний (от частей к целому).
7. Принятие основной гипотезы, т. е. формирование М2. Следует отметить наличие как дедуктивной (от целого к частям), так и индуктивной (от частей к целому) составляющей процесса понимания. Такой двуединый подход позволяет охватывать текст как смысловое единство особого рада, с его основными признаками, такими, как связность, цельность, законченность и др.
Центральными моментами процесса I являются шаги 5 и 7, т. е. формирование смысловой структуры или выделение «опорных», ключевых, слов или «смысловых вех», а также заключительное схватывание «смысловых вех» в единую семантическую структуру.
При анализе текста важно выявление внутренних связей между отдельными элементами текста и понятиями. Традиционно выделяют два вида связей в тексте - эксплицитные (или явные связи), которые выражаются во внешнем дроблении текста, и имплицитные (скрытые связи - внутренние). Эксплицитные связи делят текст на параграфы с помощью перечисления компонентов вводных слов (или коннекторов) типа «во-первых ... , во-вторых ... , однако и т. д.». Имплицитные, или внутренние, связи между отдельными «смысловыми вехами» вызывают основное затруднение при понимании.
Итак, семантическая структура текста образуется в сознании познающего субъекта с помощью знаний о языке, знаний о мире, а также общих знаний (фоновых), в той предметной области, которой посвящен текст. «Тексты пишут для посвященных». Другими словами, если текст не является научно-популярными то для его адекватного прочтения требуется некоторая подготовка.
Таким образом, путь к знаниям удлиняется еще на одно звено. Если мы раньше говорили, что сами текстологические методы редко употребляются как самостоятельный метод извлечения, а обычно используются как некоторая подготовка к коммуникативному взаимодействию, то теперь утверждаем, что и для прочтения текстов нужна подготовка.
Подготовкой к прочтению специальных текстов является выбор совместно с экспертами некоторого «базового» списка литературы, который постепенно введет аналитика в предметную область. В этом списке могут быть учебники для начинающих, главы и фрагменты из монографий, популярные издания. Только после ознакомления с «базовым» списком целесообразно приступать к чтению специальных текстов.
Компоненты формирования смысла текста М2;
- личный опыт a на ли тика - j
- общенаучная эрудиция аналитика - e
- предварительные знания аналитика о по –w
- экстракт текста Т -(a, b, g, q )
Таким образом, на процесс понимания 1 и модель М2 влияют следующие компоненты:
- экстракт компонентов (a, b, g, q ) почерпнутый из текста Т;
- предварительные знания аналитика о предметной области w;
- общенаучная эрудиция аналитика e;
- его личный опыт j.
М2=[(a, b, g, q )’ w, e, j].
Процесс 1 - это очень сложный, не поддающийся формализации процесс, на который существенным образом влияют такие чисто индивидуальные компоненты, как когнитивный стиль познания, интеллектуальные характеристики и др.
Но процедура разбивки текста на части («смысловые группы»), а затем сгущение, сжатие содержимого каждого смыслового куска в «смысловую веху» является, видимо, основой для любого индивидуального процесса понимания. Такая компрессия текста в виде набора ключевых слов, передающих основное содержание текста, может служить удобной методологической основой для проведения текстологических процедур извлечения знаний
В качестве ключевого слова может служить любая часть речи (существительное, прилагательное, глагол и т. д.) или их сочетание. Набор ключевых слов (НКС) - это набор опорных точек, по которым развертывается текст при кодировании в память и осознается при декодировании, это семантическое ядро цельности.
В качестве примера приведем результаты эксперимента по формированию НКС. Знания извлекались из следующего текста.
«Теория фреймов относится к психологическим понятиям, касающимся понимания того, что мы видим и слышим. Эти способы восприятия трактуются с последовательной точки зрения, на их основании осуществляется концептуальное моделирование, целесообразность полученных моделей исследуется вместе с различными проблемами, возникающими в этих двух областях.
Для осознания того факта, что заданная информация в этих областях имеет единственный смысл, человеческая память прежде всего должна быть способна увязывать эту информацию со специальными концептуальными объекта. МП. В противном случае не удается систематизировать информацию, которая выглядит разрозненной. В основе теории фреймов лежит восприятие фактов посредством сопоставления полученной извне информации с конкретными элементами и значениями, а также с рамками, определенными для каждого концептуального объекта в нашей памяти. Структура, представляющая эти рамки, называется фреймом. Поскольку между различными концептуальными объектами имеются некоторые аналогии, то образуется иерархическая структура с классификационными и обобщающими свойствами. Собственно она представляет собой иерархическую структуру отношений типа «абстрактное - конкретное». Сложные объекты представлены комбинацией нескольких фреймов, другими словами, они соответствуют фреймовой сети. Кроме того, каждый фрейм дополняется связанными с ним фактами и процедурой, обеспечивающей выполнение запросов к другим фреймам.
Причиной, по которой представление знаний фреймами выглядит достаточно точным, является возможность более полного описания процесса мышления человека посредством определения крупной и структурированной основной единицы представления знаний и более тесной связи знаний, основанных на фактах, и процедурных знаний. Тем не менее, как было отмечено ее автором, теорию фреймов следует скорее отнести к теории постановки задач, чем к результативной теории. Можно считать, что она существенно повышает уровень и детализирует механизм памяти человека, выводов, понимания и обучения».
Интересно, что одна из гипотез лингвостатистики о том, что наиболее употребляемые слова являются наиболее важными с точки зрения содержания текста, т. е. отражают его тематическую структуру, частично подтвердилась.
Выделим три вида текстологических методов:
1) анализ специальной литературы,
2) анализ учебников,
3) анализ методик.
Обозначенные три метода существенно отличаются, во-вторых, по степени концентрированности специальных знаний, и, во-вторых, по соотношению специальных и фоновых знаний. Наиболее простым методом является анализ учебников, в которых логика изложения обычно соответствует логике предмета и поэтому макроструктура такого текста будет, наверное, более значима, чем структура текста какой-нибудь специальной статьи. Анализ методик затруднен как раз сжатостью изложения и практическим отсутствием комментариев, т. е. фоновых знаний, облегчающих понимание для неспециалистов. Поэтому можно рекомендовать для практической работы комбинацию перечисленных методов.
В заключение приведём одну из возможных практических методик анализа текстов с целью извлечения и структурирования знаний.
1. Составление «базового» списка литературы для ознакомления с предметной областью и чтение по списку.
2. Выбор текста для извлечения знаний.
3. Первое знакомство с текстом (беглое прочтение). Для определения значения незнакомых слов -консультации со специалистами или привлечение справочной литературы.
4. Формирование первой гипотезы о макроструктуре текста.
5. Внимательное прочтение текста с выписыванием ключевых слов и выражений, т.е. выделение "смысловых вех" (компрессия текста).
6. Определение связей между ключевыми словами, разработка макроструктуры текста в форме графа или "сжатого" текста (реферата).
7. Формирование поля знаний на основании макроструктуры текста.
Дата добавления: 2016-03-05; просмотров: 1230;