Основные представления о корреляционном, дисперсионном и регрессионном анализах
Корреляционный, дисперсионный и регрессионный анализы - это основные статистические методы установления связи между величинами. Указанные анализы тесно взаимосвязаны, дополняют друг друга и решают общую задачу. Поэтому часто объединяются общим термином «регрессионный анализ».
Регрессионный анализ объединяет широкий круг задач, связанных с построением функциональных зависимостей между двумя группами числовых («интервальных» или «относительных») переменных: факторов хi и значений функции («откликов»)уj. Предполагается, что наблюдаемое в опыте значение отклика уj состоит из двух частей:
- одна из них закономерно зависит от хi, т.е. является функцией хi; обозначается f(х);
- другая часть - случайна по отношению к хi, обозначается ε.
Случайное слагаемое ε выражает либо внутренне присущую отклику изменчивость, либо влияние на него неучтённых факторов, либо то и другое вместе. (Иногда ε называют ошибкой эксперимента, связывая ее присутствие с несовершенством метода измерения у, но это не совсем точно.)
В классической модели регрессионного анализа делаются два допущения:
а) все опыты были проведены независимо друг от друга;
б) дисперсия случайных составляющих ε оставалась неизменной во всех опытах (свойство гомоскедастичности).
Корреляционный и дисперсионный анализы обычно предшествуют регрессионному анализу. Это объясняется следующим образом: прежде чем устанавливать характер связи, описывать её уравнением 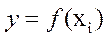 , необходимо убедиться, что достоверная связь между интересующими величинами существует и все изучаемые факторы («предикторы» xi) действительно оказывают существенное влияние на величину «отклика» y. Первую задачу решает корреляционный анализ, а вторую - дисперсионный анализ. Дадим определения этих понятий.
, необходимо убедиться, что достоверная связь между интересующими величинами существует и все изучаемые факторы («предикторы» xi) действительно оказывают существенное влияние на величину «отклика» y. Первую задачу решает корреляционный анализ, а вторую - дисперсионный анализ. Дадим определения этих понятий.
Корреляционный анализ устанавливает зависимости между случайными величинами с одновременной оценкой степени неслучайности их совместного изменения. Классический корреляционный анализ предполагает нормальное распределение рассматриваемых случайных величин.
Дисперсионный анализ служит для сравнения результатов опытов, проведённых на различных уровнях исследуемых факторов, путём анализа дисперсий этих результатов.
В условиях эксперимента факторы могут «варьироваться на разных уровнях», или «иметь несколько уровней». Это позволяет исследовать влияние контролируемого фактора на дисперсию отклика и сравнивать независимые слагаемые «систематической» составляющей дисперсии с дисперсией отклика, обусловленной альтернативными факторами: случайными и неконтролируемыми в данном эксперименте.
При дисперсионном анализе общая вариация случайной величины разлагается на случайную составляющую, а также на несколько независимых слагаемых, каждое из которых характеризует влияние того или иного фактора или их взаимодействия. Итак: сущность дисперсионного анализа заключается в определении систематической (систематических) и случайной составляющих отклика, соотношения (соотношений) этих составляющих и установлении на этой основе существенности вклада каждой из них в величину отклика. А это очень важно для правильной постановки эксперимента. Количество факторов должно быть оптимальным. Оно не может быть очень большим, так как каждый дополнительный фактор в несколько раз увеличивает объём эксперимента. Но при этом следует учитывать факторы, оказывающие существенное влияние на изучаемый зависимый показатель yi, для чего, в частности, используют дисперсионный анализ. Только в случае учёта всех существенно влияющих факторов соотношение между систематической (систематическими) и случайной составляющими yi будет достаточно высоким. Так как результат действия неучтённых факторов суммируется со случайной составляющей, это, в свою очередь, является необходимым условием получения достоверной математической модели.
Корреляционный и дисперсионный анализы необходимы уже на первом этапе построения регрессионной модели (рис. 1.2) - на стадии планирования основного эксперимента, когда имеется лишь априорная информация. С помощью корреляционного и дисперсионного анализов выбирается (предварительно) оптимальное количество основных элементов исследования и анализа:
- «независимых» факторов (называемых также «объясняющими», «экзогенными» переменными или «предикторами», xi)
- «зависимых» элементов (называемых также «эндогенными» переменными или «откликами», yi),
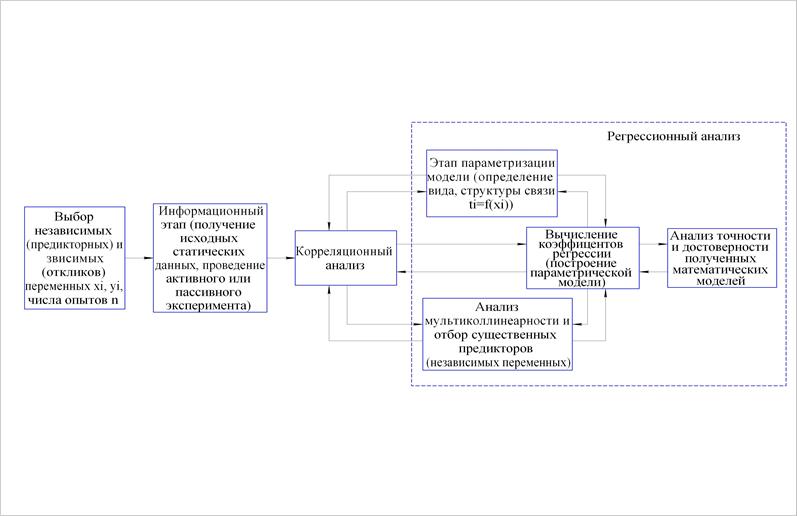
Рис. 1.2. Этапы построения регрессионной модели
- количества опытов или наблюдений n.
В практике статистического анализа для предварительного выбора числа наблюдений n и количества «независимых» факторов m часто используются следующие эмпирические соотношения:
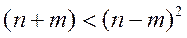 (1.1)
(1.1)
или n > 5m. (1.2)
Кроме того, для так называемого «числа степеней свободы» f должно выполняться соотношение
f = n - m - 1 >> 1. (1.3)
При этом каждый из исследуемых факторов должен быть независимым. Например, нельзя одновременно исследовать влияние факторов, связанных функционально (угловой скорости шпинделя и скорости резания) или факторов, имеющих высокую степень корреляции (величины подачи и шероховатости обработанной поверхности). Поэтому тесноту связи необходимо определять ещё на стадии планирования основного эксперимента (см. рис. 1.2). Следует проводить корреляционный анализ не только между каждым фактором и зависимым признаком («откликом» yi), но и между каждой парой факторов, если их независимость неочевидна. При этом строят так называемую «матрицу корреляций». Высокая корреляция между некоторым фактором xi и «откликом» yi позволяет сделать предварительный вывод о влиянии этого фактора и необходимости его варьирования на нескольких уровнях в ходе эксперимента. Наоборот, в случае установления функциональной или достаточно «тесной» связи (коэффициент корреляции |r| > 0,7) между какими-либо двумя факторами xi (явление «мультиколлинеарности») один из них следует исключить, так как мультиколлинеарность препятствует получению достоверной статистической модели.
В машинных расчётах регрессионной модели, в том числе в MS EXCEL, дисперсионный анализ, как правило, предшествует регрессионному анализу и таблица его результатов («ANOVA») приводится раньше результатов регрессионного анализа. Это объясняется тем, что дисперсионный анализ позволяет оценить правильность выбора варьируемых факторов и правомерность самого регрессионного анализа. Использование в регрессионном анализе «наиболее влияющих» факторов может дать достоверные результаты, так как обеспечивает преобладание «систематических» составляющих дисперсии отклика над «случайной» составляющей.
После проведения эксперимента, располагая большим объёмом данных, корреляционный (а иногда и дисперсионный) анализ повторяют для уточнения существенных предикторов и правильной параметризации создаваемой регрессионной модели.
Наряду с рассмотренными выше взаимосвязями и логическими зависимостями различных видов статистического анализа между линейным коэффициентом корреляции и коэффициентом регрессии существует и чисто функциональная зависимость:
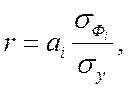 (1.4)
(1.4)
где r - коэффициент корреляции между i-м фактором и откликом y;
ai - коэффициент регрессии относительно i - го фактора;
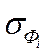 ,
, 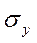 - стандартные отклонения фактора и отклика.
- стандартные отклонения фактора и отклика.
Дата добавления: 2016-01-26; просмотров: 3492;