Глава 2. ОСНОВНЫЕ ПОНЯТИЯ ИНФОРМАТИКИ
Основными понятиями информатики являются: «информация», «информационная модель», «алгоритм» и «электронно-вычислительная машина» («компьютер»).
ИНФОРМАЦИЯ.Понятие «информация» относится к так называемым первичным, неопределяемым понятиям. В математике существует группа понятий, дать строгое определение которым в принципе невозможно. К ним относятся понятия «множество», «точка» и некоторые другие. Любая попытка каким-либо образом определить их сведется к использованию синонимов. Например, часто используемыми синонимами для термина «информация» являются термины «сведения» и «данные». В таких случаях понятие вводится путем его объяснения, которое опирается на интуицию, здравый смысл или бытовое использование термина.
В вышеприведенном определении предмета «информатика» дано одно из часто используемых пояснений понятия «информация».
| i |
Под информациейпонимается отображение знаний и фактов (сведений, данных), используемых в различных областях человеческой деятельности.
Смысл термина «знание», в котором мы его применяем, также раскрыт выше: это осознанные и запомненные людьми свойства предметов, явлений и связей между ними, а также способы выполнения тех или иных действий для достижения нужных результатов. Примерами знаний являются: знания правил хорошего тона, знания иностранных языков, знания правил выполнения четырех арифметических операций, высказывания типа «при нормальном давлении вода кипит при 100 градусах Цельсия» или «сумма квадратов катетов в прямоугольном треугольнике равна квадрату гипотенузы» и т.д.
Как знания, так и отдельные систематизированные и не систематизированные факты, сведения или данные передаются с помощью сообщений.В качестве примеров таких сообщений можно привести следующие предложения: «Поезд номер 10 задерживается до 12 часов 40 минут московского времени»; «Подозреваемому на вид 40-45 лет, рост 190 см»; «Вес выпавшего осадка 15 мг»; «Уровень радиации не превышает 10 микрорентген в час» и т.д.
Сообщения могут передаваться между людьми: с помощью произнесенных или написанных слов в устной речи или на письме на различных языках — русском, английском, китайском, закодированными с помощью точек и тире, которые передаются по рации (азбука Морзе), закодированными с помощью флажковой азбуки на флоте и т.д. В общем, человечество использует для этого множество самых разнообразных способов. Однако любое сообщение всегда материально, то есть представлено некоторой материальной субстанцией — камнем, глиной, бумагой, магнитной пленкой, электромагнитными или акустическими колебаниями, молекулами или атомами вещества и т.д.
| i |
Сообщение — это материальная форма информации.
Фактически все вышеприведенные примеры, которые трактовались как информация (наскальные рисунки, запахи, звуки, бумажные тексты, фотографии и т.д.), на самом деле представляют собой примеры сообщений, несущих человеку некоторую важную или не важную для него информацию.
| i |
Информация — это нематериальный смысл, извлекаемый человеком из сообщения.
Соответствие между информацией и сообщением, с помощью которого она передается, не является взаимно однозначным. Одна и та же информация может передаваться с помощью различных сообщений. Например, сообщение о задержке рейса, передаваемое в аэропорту на различных языках, — одна и та же информация, а сообщения разные. И наоборот, одно и то же сообщение может нести различную информацию. Сообщение «Над всей Испанией безоблачное небо» было воспринято большинством радиослушателей как часть метеосводки. И лишь очень немногие посвященные знали, что это условный сигнал к началу фашистского мятежа в Испании в 1936 году. Возможность извлекать разную информацию из одного и того же сообщения является следствием того, что разные получатели информации по-разному воспринимают, трактуют, интерпретируют сообщение. А в том случае, когда сообщение передается на неизвестном слушателю языке или же неизвестным образом закодированным (зашифрованное сообщение), его получатель, если он не обладатель «ключа» для данного шифра, вообще не сможет извлечь из такого сообщения никакой информации.
Таким образом, возникает вопрос о способе, качестве и полноте извлечения информации из сообщения. Обычно способ выявления смысла сообщения является общепринятым (естественные языки), результатом договоренности между отправителем и получателем сообщения (шифрованные сообщения) или же он может быть предписан заранее им обоим (азбука Морзе). В общем случае говорят, что задается правило или группа правил интерпретации сообщений. Решающим фактором для извлечения информации из сообщения является знание языка сообщения или способа его кодирования, то есть совокупности правил интерпретации сообщения, истолкования его смысла. В качестве наглядных примеров правил интерпретации сообщений можно указать жаргоны, сленги, естественные, профессиональные и научные языки, криптографические шифры и т.д. Исходя из рассмотренных примеров и аналогий, группу правил, используемую для истолковывания смысла, интерпретации сообщений, то есть для извлечения из сообщения полезной для получателя информации, часто называют языком интерпретации сообщений.
Как правило, сообщения записываются или передаются с помощью некоторой последовательности знаков — букв письменной или звуков разговорной речи, специально подобранных значков: точек и тире, «пляшущих человечков» из рассказов о Шерлоке Холмсе, математических, химических символов и т.д. Набор знаков, которые используются для формирования и передачи сообщений, принято называть алфавитомязыкаинтерпретации сообщений. Алфавит, как правило, задается прямым перечислением всех входящих в него знаков. Например, набор знаков (цифр) {0,1,2,3,4,5,6,7,8,9} представляет собой алфавит, обычно используемый для записи чисел. Человечество за свою историю придумало большое количество различных наборов знаков, которые могут быть использованы для записи или передачи сообщений. Примерами могут служить: алфавиты естественных языков, знаки зодиака, набор знаков азбуки Брайля (для слепых), азбука Морзе, международные флажковый и семафорный коды, которые широко применяются на флоте, набор знаков регулирования дорожного движения и т.д. Поскольку в общем случае для формирования сообщения могут использоваться не только буквы алфавитов естественных языков, принято говорить, что сообщение кодируется тем или иным набором знаков, а сам алфавит или набор знаков иногда называют еще и кодом.
Как было отмечено ранее, одна и та же информация может быть передана с помощью различных сообщений, причем эта разница обычно проявляется в различном выборе языка или кода, с помощью которого оно формируется. Например, международный морской сигнал бедствия SOSможнопередать сообщением на английском языке «Save our soul», аналогичным сообщением на русском — «Спасите наши души», с помощью азбуки Морзе — «…— — —…»и многими другими способами. Но во всех случаях, на любых языках и при любых способах кодирования смысл всех сообщений один и тот же — подан сигнал бедствия. Этот важный момент можно трактовать по-другому, а именно можно считать, что существует только одно сообщение, но применяются разные способы его записи, кодировки.
Иначе говоря, одно и то же сообщение может быть без потери его смысла закодировано разными способами.
Из множества возможных способов кодирования сообщений наиболее важным для информатики частным случаем является кодирование двоичныминаборами знаков, то есть наборами, состоящими всего из двух различных знаков, символов, цифр. Именно к таким наборам относится набор {есть отверстие, нет отверстия}, который использовался для записи информации на перфокартах в упомянутых выше примерах, и двоичный код —набор знаков, алфавит {0,1}, которыйприменяется при хранении информации в памяти компьютера.
Несмотря на существенную разницу между понятиями «сообщение» и «информация», в соответствии с установившейся практикой устной и письменной речи в дальнейшем изложении практически везде используется термин «информация», хотя по контексту следовало бы использовать термин «сообщение».
ИНФОРМАЦИОННАЯ МОДЕЛЬ.Получая какую-либо информацию из окружающей среды, человек определенным образом ее просеивает, отбрасывая несущественную, случайную информацию и оставляя только важную для решаемой им задачи. Любой рассматриваемый объект или явление независимо от его материальности или идеальности имеет некоторые характерные для него черты, свойства, качества. Например, тело как материальный объект имеет геометрические размеры (длину, ширину, высоту), вес, цвет и т.д. А, скажем, исторические события характеризуются датой и местом, где они произошли. Такие характерные, неотъемлемые черты, свойства, качества принято называть атрибутамиобъектов, явлений. Вообще говоря, объект или явление может иметь очень большое количество атрибутов (десятки, сотни тысяч и более). И далеко не все из них существенны, важны для рассматриваемой задачи. Например, мы ожидаем на остановке трамвай номер 20. Мы смотрим на приближающийся трамвай и видим, что трамвай состоит из трех вагонов, что он выкрашен в красный и белый цвета, что водитель трамвая — женщина и что трамвай имеет номер 22. Неосознанно обрабатывая полученную информацию, мы, как правило, обращаем внимание только на то, что нас интересует, а именно на номер трамвая, а все остальные атрибуты отбрасываем как не имеющие значения для решаемой задачи. Таким образом, вместо реального объекта (трамвая) в нашем сознании формируется его образ, модель, лишенная всех несущественных подробностей и содержащая только нужную в данной ситуации информацию.
| i |
Модельюназывается материальный или идеальный образ некоторой совокупности реальных объектов или явлений, полученный отбрасыванием всех несущественных и концентрацией внимания только на некоторых важнейших с точки зрения решаемой задачи атрибутах рассматриваемых предметов или явлений.
При решении задач в различных областях деятельности приходится строить различные модели. В информатике рассматриваются, в основном, информационные и математические модели. Рассмотрим примеры информационных моделей.
Информационная модель личности. На каждого сотрудника какого-либо предприятия или учреждения в его отделе кадров заводится личное дело, в котором, в частности, находится личный листок по учету кадров. В этом документе отражаются такие атрибуты сотрудников, как фамилия, имя и отчество, дата рождения, пол, образование, домашний адрес и т.д. А, например, такие атрибуты, как цвет глаз, рост, вес, в личном листке никак не отражаются. Можно считать, что этот документ представляет собой информационную модель личности сотрудника учреждения. В этой модели отражены только значимые для отдела кадров атрибуты сотрудников. Если же рассмотреть ситуацию, когда создается информационная модель личности преступника, разыскиваемого органами правопорядка, то не значимые ранее атрибуты — цвет глаз, рост и вес — теперь могут стать существенными, а, скажем, образование и точная дата рождения — несущественными.
Информационная модель печатного издания. В библиотеке на каждое печатное издание заводится библиографическая карточка. В ней отражаются инвентарный и каталожные номера, название, фамилия автора или авторов, год и место издания, том, номер и т.д. Все это вместе взятое является информационной моделью печатного издания. Наличие или отсутствие суперобложки, формат (размер) издания, качество бумаги в этой модели — несущественные атрибуты, и поэтому они отбрасываются. С другой стороны, при определении цены издания для его реализации через торговую сеть эти атрибуты становятся важными, и нужно строить другую модель печатного издания.
Итак, один и тот же объект, одно и то же явление, рассматриваемые с различных точек зрения, могут иметь различные информационные модели.
Понятие математической модели очень близко к понятию информационной модели, и многие специалисты рассматривают математическую модель как специфический, частный случай информационной модели. Характерной чертой математической модели является необходимость привлечения математических соотношений, уравнений, ограничений для адекватного описания рассматриваемых явлений или связей между объектами. Например, произошло дорожно-транспортное происшествие. Необходимо определить виновника аварии. В некоторых случаях может помочь измерение длины тормозного пути, по которому, с учетом состояния дорожного покрытия, погодных условий и некоторых других факторов, можно с помощью специальных математических соотношений определить скорости машин, участвовавших в происшествии. Строится математическая модель ситуации, включающая в себя такие атрибуты, как длина тормозного пути, вес и габариты машин, состояние дорожного покрытия, специальные коэффициенты, учитывающие погодные условия, и математические соотношения, связывающие между собой все рассматриваемые величины. Выполнив необходимые математические расчеты, можно решить поставленную задачу и с большой долей уверенности определить виновника аварии.
Отвлечение от несущественных деталей, о котором шла речь выше, принято называть абстрагированием. Таким образом, абстрагирование является одним из важнейших инструментов при построении модели какой-либо предметной области. Естественно, что при абстрагировании осуществляется определенное огрубление реальной действительности. Однако концентрация внимания на наиболее важных аспектах, атрибутах позволяет выявить определяющие свойства, закономерности и, следовательно, понять сущность изучаемого объекта, явления. Наличие адекватной модели, то есть модели, верно отображающей важнейшие особенности реальных объектов или явлений, позволяет спрогнозировать поведение объекта в той или иной ситуации, описать процесс развития явления во времени, вовремя получить нужную информацию (например, узнать время отправления транспортного средства или же приобрести на него билет и т.д.). Построение модели является наиболее важным, наиболее сложным и наиболее творческим этапом при изучении любых объектов или явлений. Разработка модели в ряде случаев требует объединенных усилий высококвалифицированных специалистов в конкретной предметной области (инженера, химика, правоведа, филолога, историка) и специалистов в области информатики
АЛГОРИТМ. Построение информационной модели представляет собой первый, но не единственный этап изучения или использования в практических целях рассматриваемого объекта, явления. После построения информационной или математической модели почти всегда приходится выполнять соответствующую модели обработку конкретной информации (данных).
Осознанная обработка информации до последнего времени происходила, в основном, в мозгу человека или же применялись достаточно простые приспособления — пальцы на руках, камешки, счеты, арифмометры, логарифмические линейки и т.д. Однако схему обработки информации, последовательность действий, которые необходимо выполнить, человек либо запоминал, либо записывал на бумаге для долговременного хранения или для передачи в другие руки.
| i |
Последовательность действий, которую необходимо выполнить над исходными данными, чтобы достичь поставленной цели, принято называть алгоритмом.
Отметим, что приведённое определение понятия алгоритма является не строгим. Его можно считать скорее объяснением на уровне бытового использования термина. Приводить и обсуждать более строгие определения этого понятия в рамках настоящего пособия, по-видимому, нецелесообразно.
Возникновение термина «алгоритм» связывают с именем великого узбекского математика IX века Аль Хорезми, который дал определение правил выполнения основных арифметических операций. В европейских странах его имя трансформировалось в слово «алгорифм», а затем уже в «алгоритм». В дальнейшем этот термин стали использовать для обозначения совокупности правил, определяющих последовательность действий, выполнение которых приведет к достижению поставленной цели. Имеется несколько, в общем-то, сходных объяснений понятия алгоритм, которые акцентируют внимание на различных аспектах этого понятия. Для большей полноты восприятия понятия «алгоритм», приведем еще два достаточно часто используемых его объяснения.
Под алгоритмом понимается строгая, конечная система правил, инструкций для исполнителя, определяющая некоторую последовательность действий и после конечного числа шагов приводящая к достижению поставленной цели.
Можно также сказать, что алгоритм есть описание способа решения задачи, достижения цели, а собственно решение задачи или выполнение действий по данному способу является исполнением алгоритма.
Важным моментом в последних объяснениях является использование еще одного понятия — исполнителя алгоритма. В общем случае исполнять алгоритмы может не только человек. Животные, насекомые и даже растения в процессе своей жизнедеятельности выполняют определенные алгоритмы. В принципе, поручить исполнение алгоритма можно и неодушевленным механизмам и устройствам.
Если провести более или менее внимательный анализ, то окажется, что подавляющее большинство своих действий человек выполняет по определенным алгоритмам, иногда даже не осознавая этого. По определенным рецептам готовятся те или иные кулинарные изделия, по определенным схемам осуществляется пошив одежды, выплавка стали, выращивается зерно, выполняются лабораторные работы на занятиях по физике, химии, биологии, решаются математические задачи. Различные справочники в значительной мере являются сборниками алгоритмов, которые представляют собой способы решения тех или иных задач, разработанные той или иной научной или технической дисциплиной.
Можно утверждать, что алгоритмы — это способ фиксации и передачи знаний, накопленных человечеством, это богатство культуры, науки и техники.
Так что роль алгоритмов в жизни человека весьма многогранна и не сводится только к обработке информации. Однако в процессе обработки информации алгоритмы играют первостепенную роль.
Алгоритмы обладают важнейшим качеством — исполнение одного и того алгоритма в одних и тех же условиях различными людьми (в общем случае — исполнителями), как правило, приводит к одинаковым результатам. Следовательно, можно утверждать, что алгоритмы обладают (точнее, должны обладать) некоторыми свойствами, которые обеспечивают этот эффект. Кроме указанного качества, которое принято называть определенностью(однозначностью)алгоритма, можно указать ещепонятность задания алгоритма его исполнителю, возможность исполнения алгоритма в тех или иных конкретных условиях, принципиальную достижимость результата и некоторые другие качества. Наличие этих свойств, собственно говоря, и делают некоторый набор правил, указаний алгоритмом.
При задании алгоритма необходимо позаботиться о том, чтобы алгоритм воспринимался всеми возможными исполнителями однозначно и точно, чтобы его можно было исполнить при любых допустимых исходных условиях, и чтобы необходимый результат был получен за приемлемое время.
Способы задания (записи) алгоритмов также весьма разнообразны. В частности, можно отметить словесный способ задания алгоритма — на уровне естественного языка, запись музыкальной мелодии в виде нот, графические способы задания алгоритма: чертеж, используемый для изготовления какой-либо детали, маршрут геологической партии, нанесенный на карту, нарисованная по специальным правилам схема выполнения какой-либо последовательности действий (заметим, что такую схему принято называть блок-схемой алгоритма) и т.д.
Как будет выяснено далее, процессор компьютера «понимает» только алгоритмы, которые заданы в виде двоичных машинных кодов. Однако этот «естественный» для компьютеров, обладающий всеми необходимыми свойствами способ задания алгоритмов очень сложен для использования человеком. Поэтому в информатике применяется ряд специальных способов, языков задания, записи алгоритмов, которые, во-первых, призваны обеспечить соответствие алгоритма всем необходимым требованиям, а во-вторых, приспособлены для их использования как человеком, так и — после специальной обработки — процессором компьютера. Искусственные языки, использующиеся для записи алгоритмов и обеспечивающие им наличие всех необходимых свойств, называются алгоритмическими языками.Существует очень большое число различных по своим возможностям и классам решаемых задач алгоритмических языков. В частности, можно упомянуть такие популярные языки, как Паскаль, Модула, Си.
Если имеется алгоритм обработки информации или выполнения тех или иных действий, то, в точности выполняя все предписания алгоритма, можно получить требуемый результат, не имея ни малейшего представления о том, зачем нужно выполнять те или иные действия. Важно только абсолютно точно выполнять предписанные в алгоритме действия и соблюдать порядок их выполнения. Итак, исполнение алгоритмов относительно несложно. Именно поэтому процесс исполнения алгоритмов удается формализовать и поручить его неодушевленным механизмам, автоматическим станкам, электронно-вычислительным машинам и т.д. Разработка же алгоритма, то есть плана выполнения действий, представляет собой весьма сложный творческий процесс, на который иногда затрачиваются годы и десятилетия человеческой жизни. Разработка алгоритмов решения практических задач в различных областях человеческой деятельности осуществляется высококвалифицированными специалистами в сфере обработки данных, которых называют проблемными программистами.
?В качестве иллюстрации процесса разработки алгоритмов рассмотрим, например, построение алгоритма решения часто встречающейся на практике задачи поиска вхождения какой–либо последовательности символов в другую последовательность. С этой задачей приходится сталкиваться, например, при поиске в различного рода словарях объяснения неизвестного слова или при переводе с одного языка на другой. Мы ищем неизвестное слово, которое можно рассматривать как одну последовательность символов, в словаре, который можно рассматривать как другую последовательность символов. Значительно упрощая ситуацию, будем считать, что словарь — это текст, состоящий из какого–либо числа символов N, например, из одной тысячи символов (N=1000), а искомое слово пусть состоит всего из трех символов. То есть последовательность символов, в которой осуществляется поиск, будем называть текстом, а последовательность символов, вхождение которой ищется, будем называть словом. Естественно считать, что текст содержит больше символов, чем слово (в крайнем случае — столько же). Заметим, что конкретные длины рассматриваемых последовательностей символов при решении данной задачи не имеют принципиального значения.
При решении задачи поиска нас будет интересовать только факт наличия или отсутствия искомого слова в тексте. Дополнительные действия, возникающие, скажем, при переводе слова с одного языка на другой, мы обсуждать не будем. Вначале предположим, что мы уже умеем сравнивать одну группу из трех символов с другой группой, также состоящей из трех символов, и делать вывод о том, совпадают они или нет. Введем в рассмотрение величину I, которую мы будем трактовать как номер первого из трех очередных символов текста. Закрепим за этой величиной значение единица и сравним заданное слово с начальными тремя буквами текста. Если они совпадают, то наша задача уже решена,и делается вывод о вхождении заданного слова в рассматриваемый текст. Если имеется несовпадение, то нужно сдвинуться по тексту на одну букву. Другими словами, нужно увеличить номер I на единицу (теперь его текущее значение равно двум) и сравнить с искомым словом вторую, третью и четвертую буквы текста. Если есть совпадение, то задача решена. Если нет, то вновь увеличим номер I на единицу (теперь его текущее значение равно трем) и сравним с искомым словом третью, четвертую и пятую буквы текста. И опять при совпадении заканчиваем решение, а при несовпадении продолжим сдвиг по тексту. Очевидно, этот процесс будет продолжаться до тех пор, пока мы не доберемся до конца текста (при условии, что где-нибудь ранее не найдем совпадения). Завершит в этом случае решение задачи последнее сравнение 998, 999 и 1000 символов текста с заданным словом. Другими словами, сравнение каждой очередной тройки символов текста продолжается до значения номера I, равного N-2 (в нашем случае это 998). При этом значении номера I сравнение осуществляется последний раз. Если и этот последний отрезок не совпадает, то делается вывод об отсутствии искомого слова в тексте.
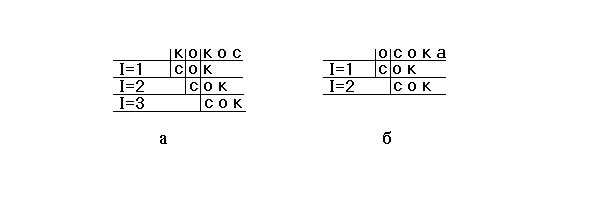 Рис. 2.1. Поиск вхождения слова в текст: а — слово в текст не входит; б — слово входит в текст
Рис. 2.1. Поиск вхождения слова в текст: а — слово в текст не входит; б — слово входит в текст
Посмотрим, как выполняются описанные действия на конкретном примере. Для наглядности еще больше упростим задачу и возьмем текст, состоящий всего из N=5 символов. Еще раз отметим, что работа с текстом из N=1000 символов в принципе выполняется точно так же, как и с текстом из N=100000000 или из N=5 символов, — разница только в количестве повторений одних и тех же действий. Чтобы проиллюстрировать возможные ситуации, возьмем два текста — «кокос» и «осока» и будем искать вхождение в эти тексты слова «сок». Выполняющиеся в этих случаях последовательности действий показаны на рис. 2.1. Величина I, играющая роль номера первого символа сравниваемого со словом участка текста, в данном примере должна пробегать значения от 1 до N–2, то есть до 3. В случае а ни один из участков текста не совпал со словом «сок». В самом деле, при I=1 участок образуют 1, 2 и 3 буквы текста — «кок», при I=2 участок состоит из 2, 3 и 4 букв текста — «око», и, наконец, последнее сравнение при I=3 — 3, 4, и 5 буквы текста образуют «кос». Дальнейшее смещение невозможно, так как при выделении последнего участка достигнута правая граница текста. Итак, в случае а делается вывод о том, что данное слово «сок» в данный текст « кокос» не входит. В случае б совпадение участка текста с заданным словом отмечается при I=2, и дальнейшие сравнения уже не выполняются.
Для завершения обсуждения задачи необходимо еще определить, каким образом следует сравнивать между собой две группы символов. Поскольку в нашем случае эти группы состоят всего из трех букв, можно предложить следующий план действий — взять первую букву слова и первую букву текущей тройки символов текста. Если они не совпадают, следует закончить сравнение с выводом о несовпадении всей группы. При совпадении первых символов перейдем ко вторым символам слова и текущей тройки. И точно так же, при их несовпадении, нужно закончить сравнение с выводом о несовпадении всей группы, а при совпадении перейти к рассмотрению последних символов. Сравнением третьего символа слова и третьего символа текущей тройки заканчивается процедура сравнения групп.
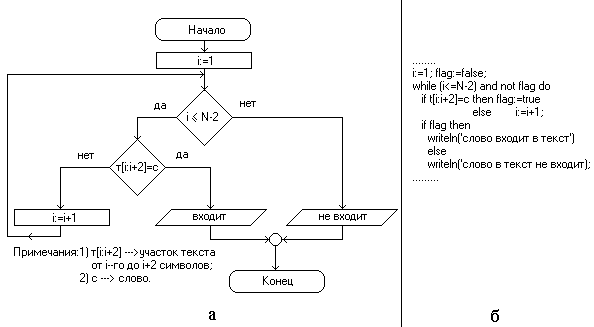 Рис. 2.2. Блок-схема алгоритма и фрагмент программы решения задачи поиска: а — упрощенная блок-схема основного узла алгоритма; б — фрагмент соответствующей программы на языке Паскаль
Рис. 2.2. Блок-схема алгоритма и фрагмент программы решения задачи поиска: а — упрощенная блок-схема основного узла алгоритма; б — фрагмент соответствующей программы на языке Паскаль
Итак, для решения сформулированной задачи поиска мы построили алгоритм, последовательность действий, проработанную до элементарных операций, которые могут быть выполнены процессором компьютера — сравнение двух символов, сравнение двух чисел, закрепление за величиной ее текущего значения, увеличение текущего значения на единицу и т.д. Правда, этот алгоритм записан в словесной форме. На рис. 2.2 изображены упрощенная блок-схема основного участка алгоритма и фрагмент программы решения задачи поиска, записанный на языке Паскаль. Читателям рекомендуется обратить внимание на то, сколько места занимают и насколько понятны записи алгоритма на уровне естественного языка, в виде блок-схемы, а также в виде программы. Если же задать действия алгоритма или программы в соответствующих им машинных кодах, то будет получена программа на машинном языке, которую «понимает» и может выполнять процессор.
КОМПЬЮТЕР. В связи со сделанным выше замечанием об относительной несложности исполнения алгоритмов, в частности алгоритмов обработки информации, у многих ученых возникала мысль перепоручить машине этот процесс, по возможности автоматизировав его полностью или хотя бы частично. Для достижения указанной выше цели в настоящее время используются электронные вычислительные машины или компьютеры. В отечественной литературе до 1985 года, в основном, использовалась аббревиатура ЭВМ. Иногда писали — вычислительная машина (ВМ), вычислительная техника (ВТ), средства обработки данных (СОД). После 1985 года широкое распространение получил эквивалентный англоязычный термин — компьютер. В настоящем пособии все эти термины используются как равноправные.
| i |
Электронно-вычислительная машина (ЭВМ), или компьютер, — это электронное устройство, используемое для автоматизации процессов приема, хранения, обработки и передачи информации, которые осуществляются по заранее разработанным человеком алгоритмам (программам).
Еще раз обращаем внимание на важнейшие моменты этого определения: 1)компьютер представляет собой электронное устройство; 2)компьютер выполняет действия без вмешательства человека — автоматически; 3)но для этого компьютеру должна быть заранее задан разработанный человеком и записанный в специальной форме план действий —программа.
Когда говорят о машинной обработке информации, весьма часто в качестве термина, эквивалентного термину «информация», используется термин «данные».
| i |
Алгоритм, записанный в специальной, «понятной» машине форме, принято называть программой,а обрабатываемую по этой программе информацию, также записанную в «понятной» компьютеру форме, принято называть данными.
Следует отметить, что единственной «понятной» для компьютера формой задания как алгоритмов, так и обрабатываемых данных является упоминавшееся выше двоичное кодирование, то есть запись программ и данных в алфавите {0,1}.
КЛАССИФИКАЦИЯ ЭВМ. К настоящему времени в мире разработаны сотни и тысячи различных моделей компьютеров. Эти модели отличаются друг от друга устройством, способами кодирования информации, наборами возможных действий по обработке данных, объемом запоминаемой информации и скоростью ее обработки. Для того чтобы ориентироваться в этом многообразии средств вычислительной техники, применяются различные классификационные схемы. Необходимо отметить, что эти классификационные схемы, во-первых, достаточно условны и не являются общепринятыми. Во-вторых, с течением времени они претерпевают определенные изменения, связанные с бурным развитием информатики и невозможностью точно предсказать направления будущего развития компьютерной техники. Ниже кратко обсуждаются две наиболее распространенные в настоящее время схемы — классификацияпо поколениям, соответствующая историческому процессу развития вычислительной техники, и классификация по применениям. Используя схему классификации по поколениям, необходимо учитывать, что исторический процесс усовершенствования и создания новых вычислительных машин происходил во времени непрерывно. И, следовательно, имеются машины и группы машин «промежуточных» по своему положению, то есть по одним признакам попадающих в одну категорию, а по другим — в другую. То же самое можно сказать и о классификации по применениям.
К настоящему времени принято выделять пять поколений вычислительной техники. К первому поколению относят машины, построенные на электронных лампах накаливания. В эту группу входят машины, созданные в период, начинающийся с электронной вычислительной машины «EDSAC» и заканчивающийся, примерно, в конце пятидесятых годов. Если судить с современной точки зрения, то можно сказать, что эти машины стоили очень дорого, занимали огромные площади, были не совсем надежны в работе, имели маленькую скорость обработки информации и могли хранить очень мало данных. Создавались они в единичных экземплярах и использовались, в основном, для военных и научных целей. В качестве типичных примеров машин первого поколения можно указать американские компьютеры IBM –701, UNIVAC, а также советские ЭВМ БЭСМ и М-20. Типичная скорость обработки данных для машин первого поколения составляла 5–30 тысяч операций в секунду.
Ко второму поколению относят машины, построенные на транзисторных элементах в период с конца пятидесятых и до середины шестидесятых годов. У этих машин значительно уменьшились стоимость и габариты, выросли надежность, скорость работы и объем хранимой информации. С появлением специальных алгоритмических языков существенно упростилось применение машин для решения практических задач в различных областях. Машины стали использовать для стандартных инженерных расчетов, в экономической деятельности для оптимизации работы отдельных предприятий и даже отраслей и во многих других областях. Типичные представители машин второго поколения — IBM-7090 (США), ATLAS (Великобритания), БЭСМ-4, М-220, Минск-32, БЭСМ-6 (СССР). Скорость обработки данных у машин второго поколения возросла до 1 миллиона операций в секунду.
Машины третьего поколения выполнены на так называемых интегральных схемах,которые сокращенно обозначают ИС.
| i |
Интегральная схема представляет собой электрическую цепь определенного функционального назначения, которая с помощью специальной технологии размещается на очень маленькой кремниевой (или какой-либо другой, подходящей по свойствам) пластинке — «основе».
Площадь такой схемы — порядка одного квадратного сантиметра, но по своим функциональным возможностям интегральная схема эквивалентна сотням и тысячам транзисторных элементов. Из-за очень маленьких размеров и толщины интегральную схему иногда называют микросхемой, а также чипом(chip — тонкий кусочек). Переход от транзисторов к интегральным схемам вызвал соответствующие изменения в стоимости, размерах, надежности, скорости и емкости машин.
Кроме перехода на новую элементную базу, машины начали выпускаться семействами. Машины, входящие в семейство, имеют одинаковую логическую структуру, одни и те же способы работы с информацией, но различные параметры стоимости, скорости и объема хранимых данных. Это позволяет осуществлять широкий обмен программами и данными между разными пользователями без внесения в программы существенных изменений. Машины третьего поколения появились в середине шестидесятых годов. Это были машины семейства IBM/360. Популярность этих машин оказалась настолько велика, что во всем мире их стали копировать или выпускать похожие по функциональным возможностям и совпадающие по способам кодирования и обработки информации. Причем программы, подготовленные для выполнения на машинах IBM, с успехом выполнялись на их аналогах, так же как и программы, написанные для выполнения на аналогах, могли быть выполнены на машинах IBM. Такие модели машин принято называть программно-совместимыми. В нашей стране такой программно-совместимой с семейством IBM/360 была серия машин ЕС ЭВМ, в которую входило около двух десятков различных по мощности моделей.
Начиная с третьего поколения, вычислительные машины становятся повсеместно доступными и широко используются для решения самых различных задач. Характерным для этого времени является коллективное использование машин, так как они все еще достаточно дороги, занимают большие залы и требуют сложного и дорогостоящего обслуживания. Правда доступ к возможностям машины уже организуется и с индивидуально используемых устройств — терминалов(terminal — конечный пункт), которые находятся на некотором удалении от основного оборудования машины, иногда даже на рабочих местах пользователей. В состав терминала, как правило, входят клавиатура, используемая для набора данных и выполнения простейших операций по управлению работой компьютера, и дисплей, служащий для отображения текущей ситуации и полученных результатов вычислений. Носителями первичной информации все еще являются перфокарты и перфоленты, хотя уже много информации сосредотачивается на магнитных носителях — дисках и лентах. Скорость обработки информации у машин третьего поколения достигла нескольких миллионов операций в секунду.
В первой половине семидесятых годов происходит переход от обычных интегральных схем к схемам с большей плотностью монтажа — большим интегральным схемам (БИС). Если обычные интегральные схемы эквивалентны тысячам, то большие интегральные схемы заменяют уже десятки тысяч транзисторных элементов. На фоне этого перехода произошло разделение до этой поры, в общем-то, единого потока развития средств вычислительной техники на две ветви. Одна ветвь продолжала старую тенденцию развития машин по линии наращивания мощности и надежности, а также по линии коллективного использования вычислительных мощностей. Считается, что машины этого направления образуют четвертое поколение ЭВМ. Среди них следует упомянуть семейство машин IBM/370, а также модель IBM 196, скорость которой достигла скорости 15 миллионов операций в секунду. Отечественными представителями машин четвертого поколения являются машины семейства «Эльбрус». Отличительная черта четвертого поколения — наличие в одной машине нескольких (обычно 2-6, иногда до нескольких сотен и даже тысяч) центральных, главных устройств обработки информации — процессоров(от слова process —обработка), которые могут дублировать друг друга или независимым образом выполнять вычисления. Такая структура позволяет резко повысить надежность машин и скорость вычислений. Другая важная особенность — появление мощных средств, обеспечивающих работу компьютерных сетей. Это позволило впоследствии создавать и развивать на их основе глобальные, всемирные компьютерные сети.
Вторая ветвь развития средств вычислительной техники оказалась направленной на миниатюризацию и персонализацию средств обработки данных. Своим рождением это направление обязано появлением в 1971 году первого микропроцессора Intel 4004 (от названия фирмы производителя INTegratet ELectronics — объединенная электроника). Микропроцессоромсчитается процессор, реализованный на одной или нескольких интегральных схемах, без потери функциональных свойств обычных процессоров. Для микропроцессоров введена отдельная классификация, по которой Intel 4004 относится к первому поколениюмикропроцессоров. Основные этапы развития микропроцессорной техники рассматриваются ниже.
Последним на сегодняшний день считается пятое поколение компьютеров. О проекте создания машин этого поколения, рассчитанном на десять лет, объявили в начале восьмидесятых годов японские разработчики. За ними в эту стратегическую гонку втянулись ученые США, СССР и ряда стран Западной Европы. Было заявлено, что к началу девяностых годов будет создано принципиально иное по стилю обработки информации и взаимодействия с пользователем поколение машин. Если ранее человек тщательно и подробно формулировал машине последовательность действий по обработке информации, то теперь машина по поставленной перед ней цели должна самостоятельно составить план действий и выполнить их. Такой способ решения задач принято называть логическим программированием. Кроме того, планировалось ввести общение с машиной на уровне естественного языка. Однако решить полностью весь комплекс задач проекта не удалось и до сих пор. Хотя имеются впечатляющие достижения по каждому из направлений проекта. Возникли определённые финансовые и технические трудности. Да и, кроме того, усилия значительной части разработчиков были переключены на микропроцессорную технику и развитие сетевых технологий.
Классификация по применениям включает следующие группы — микропроцессоры, микроЭВМ, мини-ЭВМ, универсальные машины и суперЭВМ. Микропроцессоры представляют собой программируемые интегральные схемы, встраиваемые в какое–либо отдельное устройство, механизм (автомобиль, металлорежущий станок, крылатую ракету) с целью автоматизации управления или оптимизации работы механизма. Гораздо более выгодно встраивать в различные устройства и механизмы по-разному запрограммированные, но однотипные микропроцессоры, чем для каждого из них заново разрабатывать уникальные устройства управления.
Если к микропроцессору подключить необходимые для компьютера устройства, то получится микроЭВМ, или микрокомпьютер. Оба эти названия постепенно вытесняются более популярными: персональный компьютер и персональная ЭВМ.
| i |
Персональный компьютер —это настольная электронно-вычислительная машина индивидуального использования.
Из определения следует, что персональный компьютер эксплуатируется, как правило, одним человеком или относительно небольшим коллективом специалистов для решения своих профессиональных задач. Иногда персональный компьютер используется как ведущий элемент системы управления группой механизмов. При работе в локальных или глобальных сетях персональный компьютер часто играет роль так называемого интеллектуального терминала —более мощного, чем терминалустройства, работая с которым пользователь получает доступ ко всем ресурсам сети. А предоставляются эти ресурсы более мощными персональными компьютерами, универсальными машинами или суперЭВМ. Машины, которые предоставляют свои ресурсы другим компьютерам, принято называть серверами(serve — обслуживать, быть полезным).
По своим вычислительным возможностям современные персональные компьютеры оставили далеко позади себя машины второго и третьего поколений, не говоря уже о машинах первого поколения. Для большей наглядности можете сравнить 30-тонный «динозавр» ENIAC, с его размерами и скоростью в 5 тысяч операций в секунду, и стандартный современный персональный компьютер, умещающийся на обычном рабочем столе специалиста и обладающий скоростями в десятки и сотни миллионов операций в секунду.
В 1999 году был введен в действие международный стандарт «спецификации PC99», который определяет классификацию, а также требования к аппаратным и программным средствам персональных компьютеров. Термин «спецификация» означает формализованное описание свойств, характеристик и функций некоторого объекта. Таким образом, «спецификации PC99» представляют собой описание характеристик персональных компьютеров (PC — сокращение английского словосочетания personal computer), сформулированные в 1999 году. Сразу же отметим, что классификация персональных компьютеров, предложенная в стандарте PC99, сохранилась и в стандартах, принятых в последующие годы. Согласно указанным стандартам вводится пять категорий персональных компьютеров (в скобках указаны соответствующие официальные термины):
· пользовательский, потребительский, массовый компьютер (Consumer PC), предназначенный для работы, в основном, в домашних условиях;
· офисный, деловой компьютер (Office PC) предназначен для выполнения канцелярской работы в составе компьютерных сетей предприятия, организации и т.д.;
· мобильный, переносной, портативный компьютер (Mobile PC) предназначен для специалистов, которые используют компьютерные технологии в поездках, во время деловых встреч и т.д., когда использование стационарных машин затруднено или вообще невозможно;
· рабочая станция (Workstation PC) используется в качестве сервера в компьютерных сетях, а также как рабочий инструмент разработчиками программных средств, конструкторами, то есть там, где предъявляются повышенные требования к ресурсам компьютера;
· игровые или развлекательные компьютеры (Entertainment PC) используются как игровые, а также для высококачественной работы со звуком и видеозаписями.
Следующая группа — мини-ЭВМ — состоит из машин, используемых для работы в условиях реального производства, для управления поточной линией, цехом, для обеспечения работы научной лаборатории или относительно небольшого учреждения. Как правило, мини-ЭВМ выполнена в виде нескольких напольных стоек, содержащих все её устройства. В качестве примера популярных в свое время мини-ЭВМ можно указать машины отечественного семейства СМ. Это модели СМ–4, СМ–1420 и некоторые другие. В настоящее время мини-ЭВМ практически полностью вытеснены из употребления более мощными и дешевыми персональными компьютерами.
Группа универсальных ЭВМ характеризуется возможностью решать подавляющее большинство задач по обработке информации и практически неограниченными возможностями по ее хранению. Универсальные машины (соответствующий англоязычный термин mainframe — главный каркас, центральное строение) применяются как центральное звено в системах управления производственным циклом, для обеспечения работы крупных НИИ, организаций и учреждений. В последнее время часто используются как ведущий элемент глобальных и локальных сетей, который предоставляет свои вычислительные ресурсы подключенным к сети персональным компьютерам. К группе универсальных ЭВМ относят машины типа ЕС ЭВМ, «Эльбрус» и другие, аналогичные им. Так же, как группа мини-ЭВМ, эта группа машин постепенно вытесняется мощными персональными ЭВМ.
СуперЭВМ используются для решения задач так называемых предельных классов, для которых требуется колоссальное сосредоточение вычислительных мощностей. Это задачи метеопрогноза в планетарных масштабах, задачи расчета и проектирования современных самолетов и космических кораблей, задачи из области ядерной физики и космогонических исследований, задачи управления системами противоракетной и космической обороны, задачи обеспечения работы глобальных сетей общемирового значения и т.д. К группе суперЭВМ относятся модели ILLIAC – 4 (50 миллионов операций в секунду), CRAY –1 (130 миллионов операций в секунду), CRAY – MP (50 миллиардов операций в секунду, 64 процессора). Мощнейшей (на момент написания пособия) считается модель ASCI White, которая работает со скоростью 12,4 триллионов операций в секунду. Во всем мире насчитываются не более одной-двух тысяч машин класса суперЭВМ в силу их чрезвычайно высокой сложности и стоимости.
Контрольные вопросы
Что понимается под термином «информация»?
Как связаны между собой информация и сообщение?
Приведите примеры языков интерпретации сообщений и их алфавитов.
Дайте определение и приведите примеры информационной и математической моделей.
Что понимается под термином «алгоритм»?
Какова роль алгоритмов в жизни человека?
Приведите примеры алгоритмов.
Чем отличается исполнение алгоритма от его разработки?
Укажите возможные способы задания алгоритмов.
Что такое алгоритмический язык и какими свойствами он должен обладать?
Дайте определение терминам «программа» и «данные».
Что такое ЭВМ? Чем отличается ПЭВМ от ЭВМ?
Что такое интегральная схема, процессор, микропроцессор?
Что такое терминал, какую роль играет сервер?
Опишите классификационную схему ЭВМ по поколениям.
Опишите классификационную схему ЭВМ по применению.
Опишите классификацию персональных компьютеров.
Дата добавления: 2016-01-26; просмотров: 2055;