Оптимізація швидкості обробки інформації і підвищення якості з 2D кодами
У чому ж може полягати практична користь від нового типу штрихів-кодів? Багато компаній, у тому числі і логистичні, друкують етикетки з декількома лінійними штрих-кодами. Наприклад, при переміщенні вантажу з одного розподільного центра в інший або при доставці безпосередньо в пункт пересортування створюється внутрішня накладна на вантаж. Ця накладна формується в залежності від вимог служби і як приклад може містити: код одержувача, номер партії, код товару, кількість, серійний номер, дату відвантаження або термін придатності і т. ін. у виді окремих лінійних штрихів-кодів на ній.
При одержанні вантажу оператор на прийманні послідовно сканує ці штрихи-коди у визначену форму введення в інформаційній системі.
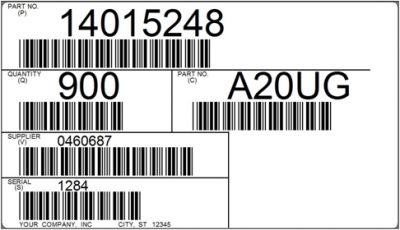 |
Рисунок 4 – Вид етикетки з кількома лінійними штрих-кодами
Детально процес виглядає так: оператор переміщає курсор миші на поле введення, наприклад, на поле з артикулом товару. Далі він знаходить на етикетці вантажу штрих-код, що відповідає артикулові, і сканує його. Після чого переходить до введення дати відправлення з наступного штрих-коду. Якщо оператор досвідчений, переміщення між формою введення даних і скануванням виконується швидко. Але людина не машина і йому властиво робити помилки. Він можевідсканувати не той штрих-кодабопоставити курсор не в те поле.
Помилки звичайно можна контролювати і мінімізувати на рівні програмування інформаційної системи за рахунок обробки формату одержуваних даних штрих-коду або автоматичного переміщення курсору. Однак потрібно розуміти, що ця задача трудозатратна, тому що прийдеться додатково допрацьовувати програмне забезпечення, і, звичайно ж, не вирішує проблеми, якщо формат даних, що зчитується, зі штрих-коду однаковий.
На заповнення форми введення і сканування 4-5 штрихів-кодів досвідчений оператор витрачає порядку 2 хвилин. Але навіть він не застрахований від операторських помилок, що зберігаються в базі даних (БД) і далі сніжною грудкою наростають під час неправильної роботи з цими даними по всьому логістичному процесі.
Усуненням таких помилок звичайно займаються високооплачувані IT фахівці, що розбираються із ситуацією і правлять помилки прямо в базі даних, або розробляють спеціальні форми коректування.
Описана вище проблема елегантно вирішується за допомогою двовимірного штрих-коду,здатного містити велику кількість структурованих даних. Всьогоодне скануванняі за набудованими заздалегідь правилами практичнонеобмежена кількість параметрів,що зашиті у штрих-коді, переміщається в потрібні поля інтерфейсу оператора і зберігаються в базі даних. Помилок оператора немає.
Наступною особливістю двовимірного штрих-коду можна назвати його самодостатність. Розкриємо, що це означає. Часто потрібно одержати детальну інформацію про вантаж або товар за межами організації, тобто в тім місці, де немає доступу до інформаційної системи компанії або попросту відсутній проводовий і безпроводовий зв'язок.
Наприклад, оператори здійснюють приймання товару на вулиці. У цьому випадку двовимірний шрих-код дозволяє повноцінно обробити вантаж, тому що вся інформація про нього утримується безпосередньо в штрих-коді. Не потрібно буде зчитувати ідентифікатор вантажу з лінійного штрих-коду, відправляти його у вилучену інформаційну систему й одержувати інформацію з неї. Вся інформація про цей товар є на самому товарі і її легко вважати за одне сканування. Це властивість технології можна використовувати і при інвентаризації вилучених підрозділів, де немає доступу до мережі. При цьому вся інформація про властивості об'єкта інвентаризації буде утримуватися на одному штрих-коді. Він може зберігати інформацію про те, кому належить об'єкт, якої він ваги, форми, кольору, які в нього інші характеристики.
Дата добавления: 2015-09-29; просмотров: 857;