Модели с дихотомическими (фиктивными) переменными
5.1. Необходимость использования фиктивных переменных.В регрессионных моделях в качестве факторных признаков часто приходится использовать не только количественные признаки, но и качественные. Например, спрос на продукцию может зависеть от вкусов потребителей, их национальных или религиозных особенностей и т. п.
Обычно в моделях влияние качественного фактора выражается в виде фиктивной (искусственной) переменной, которая отражает два противоположных состояния качественного фактора:
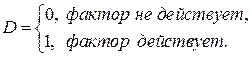
Переменная  называется фиктивной (искусственной, двоичной) переменной (индикатором).
называется фиктивной (искусственной, двоичной) переменной (индикатором).
Таким образом, в регрессионном анализе рассматриваются модели, содержащие только количественные факторные признаки (обозначаемые 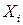 ), или качественные факторы (обозначаемые
), или качественные факторы (обозначаемые 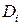 ), или те и другие одновременно.
), или те и другие одновременно.
Регрессионные модели, содержащие только качественные факторы, называются ANOVA – моделями (моделями дисперсионного анализа). Например, ANOVA - модель парной регрессии имеет вид:
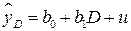 .
.
Очевидно, что условное математическое ожидание результативного признака равно:
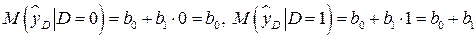 .
.
Следовательно, коэффициент 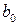 определяет среднее начальное значение результативного признака, коэффициент
определяет среднее начальное значение результативного признака, коэффициент 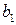 указывает, на какую величину отличается среднее начальное значение результативного признака при наличии или отсутствии качественного показателя. Проверяя статистическую значимость коэффициента при помощи
указывает, на какую величину отличается среднее начальное значение результативного признака при наличии или отсутствии качественного показателя. Проверяя статистическую значимость коэффициента при помощи 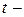 статистики, можно определить, влияет или нет фиктивный признак на результативный фактор.
статистики, можно определить, влияет или нет фиктивный признак на результативный фактор.
5.2. Регрессионные модели с количественными и качественными переменными.Модели, которые содержат количественные и качестенные факторные признаки, называются ANCOVA – моделями (моделями ковариационного анализа). Простейшая ANCOVA – модель с одним количественным и одним качественным признаками имеет вид:
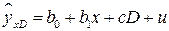 . (5.1)
. (5.1)
Ожидаемое значение результативного признака при альтернативных значениях фиктивного признака равно:
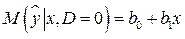 , (5.2)
, (5.2)
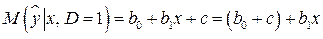 . (5.3)
. (5.3)
Из моделей (5.2) и (5.3) следует, что значение результативного признака изменяется с одним и тем же коэффициентом пропорциональности , отличаются лишь свободные члены на величину 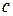 . Проверив при помощи статистики статистические значимости коэффициентов и
. Проверив при помощи статистики статистические значимости коэффициентов и 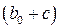 , можно определить влияние фиктивной переменной на результативный признак. При статистической значимости коэффициентов подтверждается влияние фиктивного фактора на результативный признак.
, можно определить влияние фиктивной переменной на результативный признак. При статистической значимости коэффициентов подтверждается влияние фиктивного фактора на результативный признак.
Значение фиктивного признака при 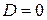 называется базовым или сравнительным. Коэффициент в модели (5.1) называется дифференциальным коэффициентом свободного члена, так как он показывает, на какую величину отличается свободный член модели при значении фиктивной переменной, равным единице, от свободного члена модели при базовом значении фиктивной переменной (при ).
называется базовым или сравнительным. Коэффициент в модели (5.1) называется дифференциальным коэффициентом свободного члена, так как он показывает, на какую величину отличается свободный член модели при значении фиктивной переменной, равным единице, от свободного члена модели при базовом значении фиктивной переменной (при ).
В регрессионную модель можно вводить произвольное число качественных переменных. Например, регрессионная модель с двумя качественными признаками имеет вид:
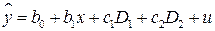 , (5.4)
, (5.4)
где
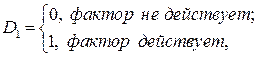
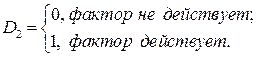
Из этой модели выводятся следующие регрессионные зависимости:
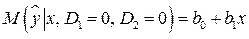 ,
,
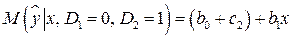 ,
,
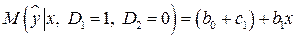 ,
,
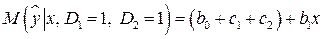 .
.
Регрессии отличаются лишь свободными членами. Дальнейшее определение статистической значимости коэффициентов 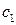 и
и 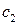 позволяет убедиться, влияют ли фиктивные факторы на результативный признак.
позволяет убедиться, влияют ли фиктивные факторы на результативный признак.
Описанные схемы могут быть распространены на регрессии с произвольным числом количественных и качественных факторов, при этом отметим, что если качественный фактор имеет 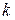 альтернативных состояний, то для его описания используется
альтернативных состояний, то для его описания используется 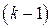 фиктивных переменных.
фиктивных переменных.
В рассмотренных выше случаях, предполагалось, что изменение значения качественного фактора влияет лишь на изменение свободного члена. Но существуют ситуации, когда изменение качественного фактора приводит к изменению, как свободного члена уравнения, так и коэффициента регрессии. Это характерно для временных рядов экономических данных при изменении институциональных условий, введении новых правовых или налоговых ограничений. В этом случае уравнение регрессии будет иметь вид:
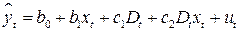 , (5.5)
, (5.5)
где
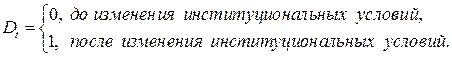
Ожидаемые значения результативного признака определяются уравнениями:
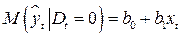 , (5.6)
, (5.6)

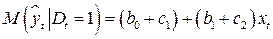 . (5.7)
. (5.7)
Коэффициенты и в уравнении (5.5) называются дифференциальным свободным членом и дифференциальным угловым коэффициентом соответственно. Фиктивный фактор 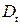 в уравнении регрессии (5.5) используется как в аддитивном виде
в уравнении регрессии (5.5) используется как в аддитивном виде 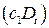 , так и в мультипликативном
, так и в мультипликативном 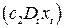 , что позволяет разбивать уравнение регрессии на два уравнения, связанные с периодами изменения рассматриваемого в модели качественного фактора.
, что позволяет разбивать уравнение регрессии на два уравнения, связанные с периодами изменения рассматриваемого в модели качественного фактора.
Для ответа на вопрос, можно ли за весь рассматриваемый период времени строить единое уравнение регрессии, или же нужно разбить временной интервал на части и на каждой из них строить свое уравнение регрессии, используется тест Чоу. Применение теста Чоу состоит в следующем.
1. Строится уравнение регрессии по выборке объема 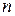 и вычисляется сумма квадратов отклонений значений
и вычисляется сумма квадратов отклонений значений 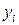 от общего уравнения регрессии:
от общего уравнения регрессии:  .
.
2. Выборку разбиваем на две подвыборки объемами 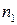 и
и 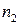 соответственно
соответственно 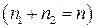 .
.
3. Для каждой из подвыборок строим уравнения регрессий и вычисляем суммы квадратов отклонений 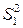 и
и 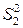 значений , для каждой из подвыборок, от соответствующих уравнений регрессий.
значений , для каждой из подвыборок, от соответствующих уравнений регрессий.
4. Проводим сравнение дисперсий на основе 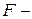 статистики:
статистики:
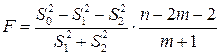 ,
,
имеющей распределение Фишера с числом степеней свободы 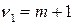 и
и 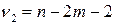 , где
, где 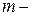 число факторных признаков во всех трех уравнениях регрессий. статистика близка к нулю, если
число факторных признаков во всех трех уравнениях регрессий. статистика близка к нулю, если 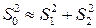 . Тогда
. Тогда 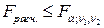 и это означает, что нет смысла разбивать уравнение регрессии на части. Если же
и это означает, что нет смысла разбивать уравнение регрессии на части. Если же 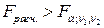 , то это означает необходимость введения в уравнение регрессии фиктивной переменной, т.е. целесообразность разбиения на подвыборки с точки зрения улучшения качества модели.
, то это означает необходимость введения в уравнение регрессии фиктивной переменной, т.е. целесообразность разбиения на подвыборки с точки зрения улучшения качества модели.
5.3. Модели с фиктивными результативными признаками.Рассмотрим модели с фиктивными результативными признаками, факторные признаки которых могут быть как количественными, так и качественными. Например, при анализе наличия работы у гражданина в зависимости от возраста, образования, семейного положения, доходов остальных членов семьи и т.д., то в качестве результативного признака выступает фиктивная переменная:
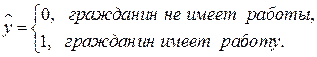
Указанные модели представимы в виде:
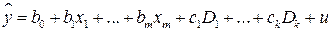 . (5.8)
. (5.8)
Модели (5.8) называются линейными вероятностными моделями (LPM – моделями).
Предположим, что зависимость фиктивного результативного признака и количественного факторного признака описывается уравнением регрессии:
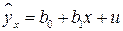 . (5.9)
. (5.9)
Из уравнения (5.9) следует, что среднее ожидаемое значение  при
при  , с учетом того, что
, с учетом того, что 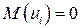 , определяется соотношением
, определяется соотношением 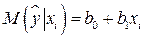 . По определению математического ожидания,
. По определению математического ожидания, 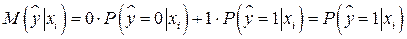 . Следовательно,
. Следовательно,
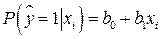 .
.
Так как 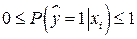 , то получено противоречие с определением вероятности. Это противоречие и другие ограничения применения МНК устраняются применением logit моделей.
, то получено противоречие с определением вероятности. Это противоречие и другие ограничения применения МНК устраняются применением logit моделей.
Поскольку использование LPM моделей имеет определенные ограничения, то применяются logit модели, в которых вероятности 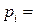
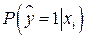 представляются в виде: =
представляются в виде: = 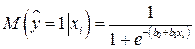 и рассматривается логарифм отношения вероятностей
и рассматривается логарифм отношения вероятностей
 ,
,
выражаемый линейной функцией. Для определения коэффициентов и применяется взвешенный метод наименьших квадратов. При этом предварительно определяются значения 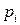 , используя эмпирические данные. Если эмпирические данные описываются выборкой сгруппированных данных, то в качестве вероятностей можно использовать их оценки – относительные частоты
, используя эмпирические данные. Если эмпирические данные описываются выборкой сгруппированных данных, то в качестве вероятностей можно использовать их оценки – относительные частоты 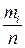 . При несгруппированных данных для нахождения оценок вероятностей используется метод максимального правдоподобия.
. При несгруппированных данных для нахождения оценок вероятностей используется метод максимального правдоподобия.
Дата добавления: 2015-08-20; просмотров: 1941;