Методы построения кодов. Код Фано
Один из методов алфавитного кодирования был предложен Фано. Схема кодирования по методу Фано заключается в следующем. Предположим, что кодируемые сообщения источника (знаки исходного алфавита) располагаются в последовательности 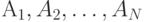 так, что соответствующие им вероятности не возрастают, т. е.
так, что соответствующие им вероятности не возрастают, т. е. 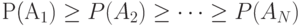 . Рассмотрим разбиения последовательности A 1, A2, …, AN на две подпоследовательности
. Рассмотрим разбиения последовательности A 1, A2, …, AN на две подпоследовательности 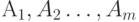 и
и 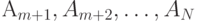 Каждое такое разбиение определяется числом
Каждое такое разбиение определяется числом 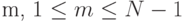 , которое определяет, сколько элементов исходной последовательности входит в первую и вторую части разбиения. Среди
, которое определяет, сколько элементов исходной последовательности входит в первую и вторую части разбиения. Среди 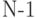 разбиения выберем такое, чтобы модуль разности
разбиения выберем такое, чтобы модуль разности 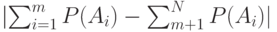 был минимальным. Всем сообщениям из первой части разбиения в качестве первого знака кодового слова приписываем 0, а сообщениям из второй части 1. По тому же принципу каждая из полученных подпоследовательностей снова разбивается на две части, и это раз-биение определяет значение второго символа кодового слова. Процедура продолжается до тех пор, пока все множество не будет разбито на отдельные сообщения. В результате каждому из сообщений будет сопоставлено кодовое слово из нулей и единиц.
был минимальным. Всем сообщениям из первой части разбиения в качестве первого знака кодового слова приписываем 0, а сообщениям из второй части 1. По тому же принципу каждая из полученных подпоследовательностей снова разбивается на две части, и это раз-биение определяет значение второго символа кодового слова. Процедура продолжается до тех пор, пока все множество не будет разбито на отдельные сообщения. В результате каждому из сообщений будет сопоставлено кодовое слово из нулей и единиц.
Описанную процедуру построения кода Фано на примере из пяти сообщений иллюстрирует следующая таблица.
| Таблица 6.1. | ||||||
| Сообщения | Вероятности сообщений | Знаки кодовых слов | Кодовое слово | |||
| 1-й знак | 2-й знак | 3-й знак | ||||
| 0.4 | |||||
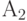
| 0.15 | |||||
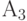
| 0.15 | |||||
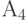
| 0.15 | |||||
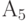
| 0.15 |
Понятно, что чем более вероятно сообщение, тем быстрее оно образует "самостоятельную" группу и тем более коротким словом оно будет закодировано. Это обстоятельство и обеспечивает высокую экономность кода Фано. Код, построенный для данного источника методом Фано, имеет среднюю длину кодового слова равную 2,3.
Код, построенный методом Фано, всегда является префиксным. Действительно, на первом шаге построения кода методом Фано множество сообщений источника разбивается на два подмножества. Все кодовые слова, соответствующие первому подмножеству, имеют однобуквенный префикс, состоящий из 0, а все слова, соответствующие второму подмножеству, имеют однобуквенный префикс, состоящий из 1 (или наоборот). Поэтому ни одно слово, соответствующее какому-нибудь из сообщений из первого подмножества, не может быть префиксом ни для какого слова, соответствующего сообщению из второго подмножества. Аналогичная процедура разбиения применяется к каждому подмножеству сообщений с одинаковыми префиксами при добавлении нового знака к формируемым кодовым словам. При этом число подмножеств, на которые разбивается исходное множество сообщений источника (блоков разбиения), увеличивается. Важным свойством разбиений является то, что для кодовых слов, соответствующих сообщениям из разных блоков разбиения, имеются различные префиксы. Построение кода завершаетсяразбиением множества сообщений на блоки, содержащие по одному сообщению. Из-за отмеченного свойства разбиений ни одно кодовое слово не является префиксом другого кодового слова, то есть построенный методом Фано код является префиксным.
Описанный метод кодирования можно применять и в случае произвольного алфавита из 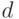 символов, с той лишь разницей, что на каждом шаге следует производить разбиение на равновероятных групп.
символов, с той лишь разницей, что на каждом шаге следует производить разбиение на равновероятных групп.
Дата добавления: 2015-08-11; просмотров: 1193;