Понижение размерности входов: признаки
Подобного рода сжатие информации является примером извлечения из непомерно большого числа входных переменных наиболее значимых для предсказания признаков. Способы систематического извлечения признаков уже были описаны в прошлых главах. Их можно (и нужно) с успехом применять и к предсказанию временных рядов.
Важно только, чтобы способ представления входной информации по возможности облегчал процесс извлечения признаков. Вейвлетное представление являет собой пример удачного, с точки зрения извлечения признаков, кодирования (Kaiser, 1995). Например, на следующем рисунке (Рисунок 14) изображен отрезок из 50 значений ряда вместе с его реконструкцией по 10 специальным образом отобранным вейвлет-коэффициентов. Обратите внимание, что несмотря на то, что для этого потребовалось в пять раз меньше даных, непосредственное прошлое ряда восстановлено точно, а более далекое - лишь в общих чертах, хотя максимумы и минимумы отражены верно. Следовательно, можно с приемлемой точностью описывать 50-мерное окно всего лишь 10-мерным входным вектором.
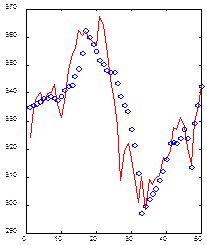
Рисунок 14 Пример 50-мерного окна (сплошная линия) и его реконструкции по 10 вейвлет-коэффициентам.
Еще один возможный подход - использование в качестве возможных кандидатов в пространство признаков различного рода индикаторов технического анализа, которые автоматически подсчитываются в соответствующих программных пакетах (таких как MetaStock или Windows On Wall Street). Многочисленность этих эмпирических признаков (Colby, 1988) затрудняет пользование ими, тогда как каждый из них может оказаться полезным в применении к данному ряду. Описанные ранее методы позволят отобрать наиболее значимую комбинацию технических индикаторов, которую и следует затем использовать в качестве входов нейросети.
Метод искусственных примеров (hints)
Одним из самых "больных мест" в финансовых предсказаниях является дефицит примеров для обучения нейросети. Финансовые рынки, вообще говоря, не стационарны (особенно российские). Появляются новые финансовые инструменты, для которых еще не накоплена история, изменяется характер торговли на прежних рынках. В этих условиях длина доступных для обучения нейросети временных рядов весьма ограничена.
Однако, можно повысить число примеров, используя для этого те или иные априорные соображения об инвариантах динамики временного ряда. Это еще одно физико-математическое понятие, способное значительно улучшить качество финансовых предсказаний. Речь идет о генерации искусственных примеров, получаемых из уже имеющихся применением к ним различного рода преобразований.
Поясним основную мысль на примере. Психологически оправдано следующее предположение: игроки обращают внимание, в основном, на форму кривой цен, а не на конкретные значения по осям. Поэтому если немного растянуть по оси котировок весь временной ряд, то полученный в результате такого преобразования ряд также можно использовать для обучения наряду с исходным. Мы, таким образом, удвоили число примеров за счет использования априорной информации, вытекающей из психологических особенностей восприятия временных рядов участниками рынка.[22] Более того, мы не просто увеличили число примеров, но и ограничили класс функций, среди которых ищется решение, что также повышает качество предсказаний (если, конечно, использованный инвариант соответствует действительности).
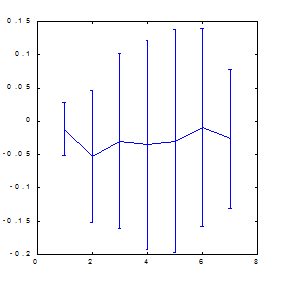
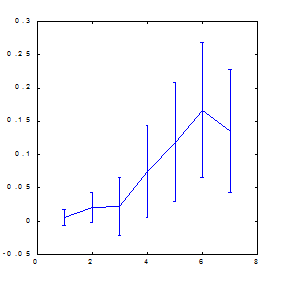
Приведенные ниже результаты вычисления предсказуемости индекса S&P500 методом box-counting (см. Рисунок 15, Рисунок 16) иллюстрируют роль искусственных примеров. Пространство признаков в данном случае формировалось методом ортогонализации, описанным в главе о способах предобработки данных. В качестве входных переменных использовались 30 главных компонент в 100-мерном лаговом пространстве. Из этих главных компонент были выбраны 7 признаков - наиболее значимые ортогональные линейные комбинации. Как видно из этих рисунков, лишь применение искусственных примеров оказалось способным в данном случае обеспечить заметную предсказуемость.
| 
|
| Рисунок 15. Предсказуемость знака изменения котировок индекса S&P500 | Рисунок 16. Предсказуемость знака изменения котировок индекса S&P500 после учетверения числа примеров методом растяжения по оси цен |
Обратите внимание, что использование ортогонального пространства признаков привело к некоторому повышению предсказуемости по сравнению с обычным способом погружения: с 0.12 бит (Рисунок 13) до 0.17 бит (Рисунок 16). Чуть позже, когда пойдет речь о влиянии предсказуемости на прибыль, мы покажем, что за счет этого норма прибыли может увеличиться почти в полтора раза.
Другой, менее тривиальный, пример удачного использования такого рода подсказок (hints) для нейросети в каком направлении искать решение - использование скрытой симметрии в валютной торговле. Смысл этой симметрии в том, что валютные котировки могут рассмматриваться с двух "точек зрения", например как ряд DM/$ или как ряд $/DM. Возрастание одного из них соответствует уменьшению другого. Это свойство можно использовать для удвоения числа примеров: каждому примеру вида можно добавить его симметричный аналог . Эксперименты по нейросетевому предсказанию показали, что для основных валютных рынков учет симметрии поднимает норму прибыли примерно в два раза, конкретно - с 5% годовых до 10% годовых, с учетом реальных транзакционных издержек (Abu-Mostafa, 1995).
Измерение качества предсказаний
Хотя предсказание финансовых рядов и сводится к задаче аппроксимации многомерной функции, оно имеет свои особенности как при формировании входов, так и при выборе выходов нейросети. Первый аспект, касающийся входов, мы уже обсудили. Теперь коснемся особенностей выбора выходных переменных. Но прежде ответим на главный вопрос: как измерить качество финансовых предсказаний. Это поможет определить наилучшую стратегию обучения нейросети.
Дата добавления: 2015-04-10; просмотров: 1350;