Теоретичні положення
Ефективне або статистичне кодування застосовують для зменшення довжини повідомлення без втрат (або майже без втрат) інформації. Статистичним його називають тому, що при побудові коду враховуються статистичні (ймовірнісні) характеристики джерела інформації, а саме: довжина кодової комбінації, якою кодується символ джерела, пов’язується із ймовірністю його появи. Більш ймовірним символам джерела намагаються зіставити більш короткі кодові комбінації, тобто код буде нерівномірним. Врешті решт середня довжина кодової комбінації буде меншою ніж, наприклад, при застосуванні рівномірного коду.
Будемо розглядати тільки двійкові ефективні коди, алфавіт яких має два символи, наприклад, 0 та 1. Такі коди використовуються в переважній більшості технічних систем.
Потенційні можливості ефективного кодування визначає першатеорема Шеннона, яка для двійкових кодів формулюється так: для будь-якого дискретного джерела інформації можна розробити такий спосіб кодування, що середня довжина 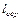 кодової комбінації двійкового коду в розрахунку на один символ джерела буде як завгодно близькою до ентропії цього джерела, вираженої в бітах, але не може бути меншою за неї.
кодової комбінації двійкового коду в розрахунку на один символ джерела буде як завгодно близькою до ентропії цього джерела, вираженої в бітах, але не може бути меншою за неї.
Щоб нерівномірний код можна було застосувати для кодування послідовності символів, яка утворюється дискретним джерелом інформації, він повинен відповідати деяким вимогам. Розглянемо, наприклад, дискретне джерело з алфавітом {x1, x 2 , x 3} та ймовірностями появи символів p(x1) = 0,5; p(x2) = 0,4; p(x3) = 0,1. Здавалося б, що для кодування символів цього джерела можна застосувати такі комбінації: 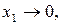
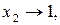
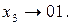 Припустимо, що на виході джерела з’явилась послідовність
Припустимо, що на виході джерела з’явилась послідовність 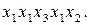 На виході кодера, що кодує символи джерела запропонованим кодом, буде така двійкова послідовність 000101. Ця послідовність допускає декілька різних результатів декодування, а саме:
На виході кодера, що кодує символи джерела запропонованим кодом, буде така двійкова послідовність 000101. Ця послідовність допускає декілька різних результатів декодування, а саме: 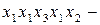 збігається з послідовністю, що була закодована;
збігається з послідовністю, що була закодована; 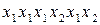 та
та 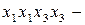 відрізняються від послідовності, яку згенерувало джерело. Це означає, що такий код не забезпечує однозначне декодування.
відрізняються від послідовності, яку згенерувало джерело. Це означає, що такий код не забезпечує однозначне декодування.
Необхідною умовою однозначного декодування нерівномірного двійкового коду є виконання співвідношення ( нерівність Крафта )
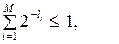
| (7.1) |
де 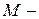 кількість кодових комбінацій коду;
кількість кодових комбінацій коду;
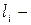 довжина i - ої кодової комбінації.
довжина i - ої кодової комбінації.
Для запропонованого вище коду ця умова не виконується:
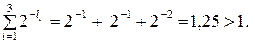
|
При 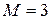 нерівність Крафта буде виконуватись, наприклад, якщо
нерівність Крафта буде виконуватись, наприклад, якщо 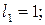
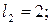
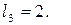
Однозначне декодування забезпечують коди, в яких жодна з більш коротких кодових комбінацій не збігається з початковою частиною кожної більш довгої кодової комбінації. Такі коди називають префіксними. У запропонованому коді кодова комбінація 0 для символу 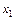 співпадає з початком кодової комбінації 01 для символу
співпадає з початком кодової комбінації 01 для символу 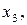 тобто цей код не є префіксним.
тобто цей код не є префіксним.
Побудова префіксних кодів пов’язана зі спеціальними графами, які мають назву кодових дерев (або просто дерев). m - ковим деревом називають граф, тобто систему вузлів і гілок (ребер), в якому відсутні петлі (замкнені шляхи) та із кожного вузла виходить не більше ніж m гілок, а в кожний вузол, крім одного (кореня дерева), входить точно одна гілка. Вузол, з якого не виходить жодної гілки, називають кінцевим, інші вузли – некінцеві. Кожній гілці приписується один символ алфавіту коду, який складається з 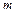 символів, при цьому різним гілкам, що виходять із одного вузла, приписують різні символи.
символів, при цьому різним гілкам, що виходять із одного вузла, приписують різні символи.
Кожному вузлу, крім кореня, можна поставити у відповідність кодову комбінацію, яка формується як послідовність символів, приписаних тим гілкам дерева, які утворюють шлях від кореня до даного вузла.
На рис. 7.1 зображено двійкове ( 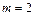 ) кодове дерево.
) кодове дерево.
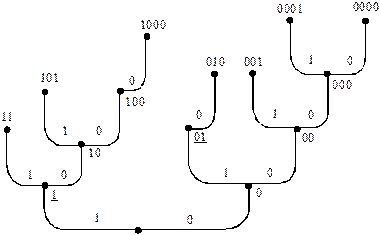
Рис. 7.1. Двійкове кодове дерево
Гілкам, що виходять з вузлів ліворуч, приписано символ 1, а що виходять праворуч, – символ 0, але притримуватися такої системи необов’язково. Необхідно тільки, щоб одній з гілок, яка виходить із будь-якого вузла, відповідав символ 0, а іншій гільці, яка виходить з того ж самого вузла, – символ 1. Біля кожного вузла (крім кореня) зображено комбінацію. Комбінації, які відповідають некінцевим вузлам, підкреслені. Кодові комбінації кінцевих вузлів завжди утворюють префіксний код. Так, до складу коду, який відповідає кінцевим вузлам зображеного на рис. 7.1 дерева, входять комбінації: 11, 101, 1000, 010, 001, 0001, 0000. Легко пересвідчитись, що цей код є префіксним.
Включення до коду будь-якої кодової комбінації, що відповідає некінцевому вузлу, дає код, який не є префіксним. Дійсно, шлях від кореня до будь-якого некінцевого вузла завжди збігається з початковою частиною шляху від кореня до хоча б одного кінцевого вузла, а це означає, що кодова комбінація, яка відповідає цьому некінцевому вузлу буде збігатися із початковою частиною хоча б однієї більш довгої кодової комбінації. Ці ствердження справедливі для будь-якого кодового дерева. Розглянемо алгоритм синтезу нерівномірного ефективного префіксного коду, який базується на побудові кодового дерева. Цей алгоритм був запропонований у 1952 р. Д. Хаффменом, тому такі коди мають назву кодів Хаффмена.
Припустимо, що треба розробити нерівномірний ефективний код для немарковського дискретного джерела, алфавіт якого має вісім символів: 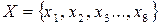 . Ймовірності виникнення символів є такими:
. Ймовірності виникнення символів є такими:
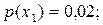
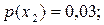
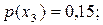
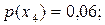
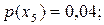
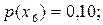
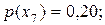
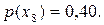
Процес побудови кодового дерева є таким (див. рис.7.2). Кожному символу дерева поставимо у відповідність кінцевий вузол кодового дерева. Разом з позначенням символу запишемо біля вузла значення ймовірності його появи. Для зручності пояснення вузли дерева занумеровані. Кінцеві вузли мають номери з 1-го по 8-ий. Далі вибираємо два вузли, яким відповідають найменші значення ймовірностей (це вузли 1 та 2), об’єднуємо (склеюємо) їх, в результаті чого отримуємо новий вузол (номер 9), котрому приписуємо ймовірність, що дорівнює сумі ймовірностей об’єднаних вузлів. Знову вибираємо два вузли з найменшими ймовірностями, але тепер не враховуємо вузли, що були об’єднанні (тобто вузли 1 та 2), а беремо до уваги вузол, який з’явився (вузол 9). В даному випадку це вузли 5 та 9. Об’єднуємо їх у вузол 10, та приписуємо ймовірність 0,09. Повторюємо процедуру об’єднання вузлів з найменшими ймовірностями доки не утвориться кореневий вузол. Таким чином отримуємо кодове дерево. Гілки дерева можуть перехрещуватись.
| х1 | х2 | х3 | х4 | х5 | х6 | х7 | х8 |
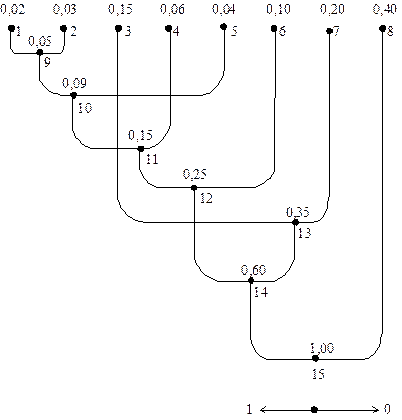
Рис.2.2. Двійкове дерево Хаффмена
Слід зауважити, що процес побудови кодового дерева не завжди є однозначним. Так, у прикладі, що розглядається, вузол 6 об’єднано з вузлом 11, однак його можна було б об’єднати замість того з вузлом 3, оскільки і вузлу 11 і вузлу 3 приписані ймовірності 0,15. Вибір того, чи іншого варіанта побудови кодового дерева не змінює середню довжину кодової комбінації коду Хаффмена.
Щоб не захаращувати рисунок, символи двійкового алфавіту коду, що приписуються кожній гілці графа, не показані. Натомість домовимося, що гілці, яка відходить від вузла ліворуч, відповідає символ 1, праворуч – символ 0. Тепер, використовуючи побудоване кодове дерево, запишемо кодові комбінації для символів джерела як послідовності символів 0 та 1, що зустрічаються на шляху від кореня дерева до кінцевих вузлів, які зіставлені відповідним символам джерела.
Результати побудови коду занесені в таблицю 7.1, там же наведені значення довжин li кодових комбінацій.
Таблиця 7.1
| xi | p(xi) | Кодова комбінація | li |
| x1 | 0,02 | ||
| x2 | 0,03 | ||
| x3 | 0,15 | ||
| x4 | 0,06 | ||
| x5 | 0,04 | ||
| x6 | 0,10 | ||
| x7 | 0,20 | ||
| x8 | 0,40 |
Розрахуємо середню довжину 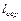 кодової комбінації:
кодової комбінації:
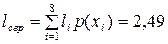 . .
|
Ентропія джерела
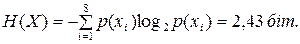
|
Відзначимо, що рівномірний код для кодування символів цього джерела буде мати довжину 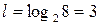 .
.
Код Хаффмена є оптимальним ефективним кодом, тобто таким, що для джерела із заданими потужністю алфавіту та розподілом ймовірностей появи символів гарантує найменшу середню довжину кодової комбінації. Але ж у прикладі, що розглядається, середня довжина кодової комбінації побудованого за методикою Хаффмана двійкового коду перевищує ентропію на 2,49 – 2,43 = 0,06. В той же час у першій теоремі Шеннона стверджується, що цю різницю можна зробити як завгодно малою. Яким же чином її можна зменшити? Для цього необхідно будувати ефективний нерівномірний код для кодування не окремих символів джерела, а слів (блоків) по декілька символів. Якщо будувати код для слів по два символи, то для даного прикладу це будуть слова 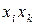 ;
; 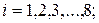
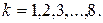 Таку процедуру називають укрупненням алфавіту. По суті отримуємо нове джерело з потужністю алфавіту 64, та з розподілом ймовірностей, які будуть визначатись ймовірностями
Таку процедуру називають укрупненням алфавіту. По суті отримуємо нове джерело з потужністю алфавіту 64, та з розподілом ймовірностей, які будуть визначатись ймовірностями 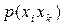 появи пар символів. Побудований для такого джерела код забезпечить середню довжину кодової комбінації в розрахунку на один символ вихідного джерела з алфавітом
появи пар символів. Побудований для такого джерела код забезпечить середню довжину кодової комбінації в розрахунку на один символ вихідного джерела з алфавітом 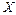 (питому середню довжину), що буде меншою, ніж 2,49. При збільшенні довжини слів, які підлягають кодуванню, ця питома середня довжина коду буде асимптотично наближатись до 2,43. В той же час збільшення довжини слів призводить до швидкого зростання об’єму коду.
(питому середню довжину), що буде меншою, ніж 2,49. При збільшенні довжини слів, які підлягають кодуванню, ця питома середня довжина коду буде асимптотично наближатись до 2,43. В той же час збільшення довжини слів призводить до швидкого зростання об’єму коду.
Інший алгоритм побудови ефективного префіксного коду був запропонований у 1948р. К.Шенноном, а трохи пізніше модифікований Р. Фано. Тому ці коди називають кодами Шеннона-Фано. Методику побудови коду Шеннона-Фано розглядаємо на прикладі дискретного немарковського джерела з алфавітом 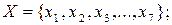 ймовірності появи символів є таким:
ймовірності появи символів є таким:
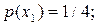 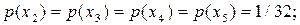
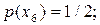 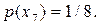
|
Процес побудови коду ілюструється таблицею 7.2. Упорядковуємо символи джерела по незростанню значень ймовірностей їх появи, тобто ймовірність появи символу, який знаходиться на деякій позиції другої колонки таблиці, не повинна перевищувати ймовірність появи символу, що розташований вище.
Таблиця 7.2
| p(xi) | xi | Кодова комбінація | li | Номер поділу | |
| 1/2 | x6 | ||||
| 1/4 | x1 | ||||
| 1/8 | x7 | ||||
| 1/32 | x2 | ||||
| 1/32 | x3 | ||||
| 1/32 | x4 | ||||
| 1/32 | x5 |
Можна упорядкувати символи також по незменшенню. Далі поділяємо множину упорядкованих символів горизонтальним відрізком на дві підмножини таким чином, щоб сума ймовірностей появи символів, розташованих над відрізком, була якомога ближче до суми ймовірностей появи символів, розташованих під відрізком. В даному випадку цю умову можна виконати ідеально, якщо відрізок провести між 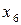 та
та 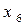 :
:
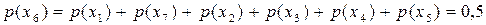 . Це буде перше розділення, що фіксується в п’ятій колонці таблиці 7.2. Символам джерела, що розташовані вище відрізка, приписуємо символ 1 двійкового коду, нижче – символ 0 (можна символи алфавіту коду поміняти місцями). Це будуть перші символи кодових комбінацій. Далі аналогічні процедури необхідно виконувати над отриманими підмножинами. Оскільки одна із підмножин містить лише один символ
. Це буде перше розділення, що фіксується в п’ятій колонці таблиці 7.2. Символам джерела, що розташовані вище відрізка, приписуємо символ 1 двійкового коду, нижче – символ 0 (можна символи алфавіту коду поміняти місцями). Це будуть перші символи кодових комбінацій. Далі аналогічні процедури необхідно виконувати над отриманими підмножинами. Оскільки одна із підмножин містить лише один символ 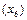 , процес формування кодової комбінації для нього закінчено. Другим поділом розділяємо підмножину символів
, процес формування кодової комбінації для нього закінчено. Другим поділом розділяємо підмножину символів 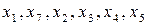 на
на 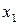 та
та 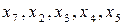 . Цей поділ також буде ідеальним, оскільки
. Цей поділ також буде ідеальним, оскільки 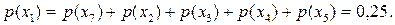 Як і раніше, символам цієї підмножини, розташованим вище відрізка другого поділу, приписуємо символ 1, нижче – символ 0. Процедуру розділення підмножин та послідовного приписування символів алфавіту коду закінчуємо, коли кожна підмножина буде містити точно один символ.
Як і раніше, символам цієї підмножини, розташованим вище відрізка другого поділу, приписуємо символ 1, нижче – символ 0. Процедуру розділення підмножин та послідовного приписування символів алфавіту коду закінчуємо, коли кожна підмножина буде містити точно один символ.
Отриманий код є префіксним. Середня довжина кодової комбінації:
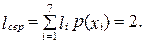
|
Ентропія джерела:
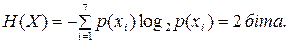
|
Середня довжина кодової комбінації точно збігається із значенням ентропії джерела. В такому випадку кажуть, що ефективний код є ідеальним. Необхідною і достатньою умовами можливості побудови ідеального ефективного коду за методикою Шеннона-Фано або Хаффмена для немарковського джерела є рівність ймовірності появи кожного символу його алфавіту будь-який цілій (зрозуміло, від’ємний) степені двійки. Легко пересвідчитись, що в даному випадку ця умова задовольняється.
Коди, побудовані для одного і того ж джерела за методиками Шеннона-Фано та Хаффмена, можуть цілком збігатися. Але якщо це і не так, середні довжини кодових комбінацій цих кодів майже завжди будуть рівними.
Побудова нерівномірного ефективного коду для кодування символів марковського джерела найчастіше не дає бажаних результатів. Так, можна уявити марковське джерело, у якого безумовні ймовірності 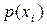 виникнення для всіх символів будуть мати одне і те ж значення (рівноймовірний розподіл):
виникнення для всіх символів будуть мати одне і те ж значення (рівноймовірний розподіл): 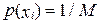 , M – потужність алфавіту, але ентропія буде значно меншою, ніж максимально можлива H max = = log 2 M для алфавіту потужності M. Зменшення ентропії у такого джерела спричиняється тільки наявністю пам’яті. Спроба побудувати нерівномірний ефективний код для кодування символів такого джерела, базуючись тільки на безумовних ймовірностях виникнення символів, призведе до того, що для середньої довжини коду буде завжди виконуватись співвідношення l cep ³ H max , причому рівність буде мати місце тільки тоді, коли M = 2 m, де m – натуральне число; до речі, код у цьому випадку буде рівномірним.
, M – потужність алфавіту, але ентропія буде значно меншою, ніж максимально можлива H max = = log 2 M для алфавіту потужності M. Зменшення ентропії у такого джерела спричиняється тільки наявністю пам’яті. Спроба побудувати нерівномірний ефективний код для кодування символів такого джерела, базуючись тільки на безумовних ймовірностях виникнення символів, призведе до того, що для середньої довжини коду буде завжди виконуватись співвідношення l cep ³ H max , причому рівність буде мати місце тільки тоді, коли M = 2 m, де m – натуральне число; до речі, код у цьому випадку буде рівномірним.
Якщо марковське джерело має невелику глибину пам’яті, хороші результати можна отримати, якщо побудувати нерівномірний ефективний код для укрупненого алфавіту. Взагалі укрупнення алфавіту та побудова для нього ефективного коду є універсальним способом стиснення повідомлень. Але для марковських джерел, що мають велику глибину пам’яті, треба виконувати значне укрупнення. Це призводить до кодів з такою кількістю кодових комбінацій, що практична реалізація процедур кодування та декодування стає неможливою.
Іншим способом ефективного кодування для марковських джерел з невеликою глибиною пам’яті є спосіб l – грамм ( g – грамм) або марковський алгоритм. Суть способу полягає в тому, що для кожного стану марковського джерела будується нерівномірний ефективний код для кодування символів джерела з урахуванням умовних ймовірностей появи символів, тобто маємо набір кодових таблиць, кількість яких дорівнює кількості 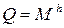 станів джерела. Ці таблиці зберігаються в кодері та декодері, і для кодування та декодування кожного наступного символу вибирається таблиця у відповідності із станом джерела, який визначається набором h попередніх символів.
станів джерела. Ці таблиці зберігаються в кодері та декодері, і для кодування та декодування кожного наступного символу вибирається таблиця у відповідності із станом джерела, який визначається набором h попередніх символів.
Запропонувати універсальний алгоритм стиснення даних такий, що дозволяв би не занадто складну технічну реалізацію для різноманітних реальних повідомлень, які можна представити як результат генерування марковських джерел з великою глибиною пам’яті (текстові дані, нерухомі та рухомі зображення), неможливо. Це пояснюється значними відмінностями структурних характеристик цих повідомлень. Для кожного типу таких даних розроблені досить складні специфічні процедури стиснення [25]. Слід, однак, зауважити, що майже кожна з таких процедур включає етапи побудови та застосування нерівномірних ефективних кодів Шеннона-Фано або Хаффмена.
Дата добавления: 2014-12-22; просмотров: 1380;