Задача 7.2.4
Маємо дискретне марковське джерело інформації, алфавіт котрого містить два символи {A,B}, а глибина пам’яті h = 1. Умовні ймовірності появи символів мають такі значення
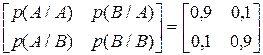 .
.
Розробити нерівномірні ефективні коди для кодування слів джерела довжиною від 1 до 4. Прослідкувати наближення середньої довжини кодової комбінації (в розрахунку на один символ джерела) до ентропії джерела. Закодувати розробленими кодами послідовність із 24 символів ВВВВВААААААААААААААААААА, яку згенерувало джерело.
Розв’язання. Для розрахунку ймовірностей появи слів на виході джерела та його ентропії необхідно знати безумовні ймовірності p(A) та p(B) виникнення символів. Користуючись методикою, що застосована у задачі 7.2.6, легко отримати p(A) = p(B) = 0,5. За виразом (7.27) знаходимо значення ентропії H П1 = 0,47 біт.
Побудова коду для кодування окремих символів, тобто слів довжиною у один символ, дасть середню довжину кодової комбінації lcep (1) = 1, оскільки одному із символів, наприклад А, зіставляється 0, а іншому – 1.
Для побудови ефективних кодів, призначених для кодування слів джерела більшої довжини, необхідно знати ймовірності появи таких слів на виході джерела. Всі дані для розрахунків маємо. Так, ймовірність p(AB) появи слова АВ буде дорівнювати p(AB)= = p(A)×p(B/A)=0,5×0,1 =0,05, а слова ВВАА :
p(BBAA)= p(B)×p(B/B)×p(A/B)×p(A/A)=0,5×0,9×0,1×0,9 =0,04505.
Таблиці 7.5, 7.6, 7.7 відображають процес та результат побудови кодів Шеннона - Фано для кодування слів джерела довжиною у 2, 3 та 4 символи.
Таблиця 7.5
| Слово джерела ( СД ) | Ймовірність появи СД | Кодова комбінація ( КК ) | Довжина КК | Номер поділу | |
| АА | 0,45 | ||||
| ВВ | 0,45 | ||||
| АВ | 0,05 | ||||
| ВА | 0,05 |
Отримаємо значення середньої довжини lcep ( N )кодової комбінації ( в розрахунку на один символ джерела ) для коду, розробленого для кодування слів джерела довжиною N:
lcep ( 2 ) = [(1+2)´0,45+3´2´0,05]/2 = 0,825;
lcep ( 3 ) = [(1+2)´0,405+(4´3+5)´0,045+6´2´0,05]/3 = 0,68;
lcep ( 4 ) = [(1+2)´0,3645+(4+5´5)´0,0405+(7+8´5)´0,0045+
+9´2´0,0005]/4 = 0,622.
Таблиця 7.6
| Слово джерела ( СД ) | Ймовірність появи СД | Кодова комбінація ( КК ) | Довжина КК | Номер поділу | |
| ААА | 0,405 | ||||
| ВВВ | 0,405 | ||||
| ААВ | 0,045 | ||||
| АВВ | 0,045 | ||||
| ВВА | 0,045 | ||||
| ВАА | 0,045 | ||||
| АВА | 0,005 | ||||
| ВАВ | 0,005 |
Відносна різниця між середньою довжиною кодової комбінації та ентропією джерела для побудованих кодів складає 75%, 44%, 32%. При збільшенні довжини N слів, що підлягають кодуванню, середня довжина lcep ( N ) кодової комбінації буде асимптотично наближатися до ентропії джерела.
Можна переконатися, що коди, побудовані за методикою Хаффмена, в даному випадку будуть мати такі ж середні довжини кодових комбінацій. Це означає, що всі отримані коди є оптимальними, але кожен для свого джерела. Перший – для джерела, алфавіт, якого складається із чотирьох символів {AA,BB,AB,BA}, ймовірності появи яких наведені в табл. 7.5, другий – для джерела із алфавітом потужності 8 ( табл. 7.6 ), третій – для джерела із алфавітом потужності 16 (табл. 7.7); тобто для джерел з укрупненим алфавітом відносно вихідного джерела, яке задане в умовах задачі. Всі укрупнені символи цих джерел мають такі ж ймовірності появи, що і відповідні слова, які генеруються вихідним джерелом. Це дозволяє побудовані для джерел коди використовувати для кодування послідовностей символів вихідного джерела.
Таблиця 7.7
| Слово джерела ( СД ) | Ймовірність появи СД | Кодова комбінація ( КК ) | Довжина КК | Номер поділу | |
| АААА | 0,3645 | ||||
| ВВВВ | 0,3645 | ||||
| АААВ | 0,0405 | ||||
| ААВВ | 0,0405 | ||||
| АВВВ | 0,0405 | ||||
| ВААА | 0,0405 | ||||
| ВВАА | 0,0405 | ||||
| ВВВА | 0,0405 | ||||
| ААВА | 0,0045 | ||||
| АВАА | 0,0045 | ||||
| АВВА | 0,0045 | ||||
| ВААВ | 0,0045 | ||||
| ВВАВ | 0,0045 | ||||
| ВАВВ | 0,0045 | ||||
| АВАВ | 0,0005 | ||||
| ВАВА | 0,0005 |
Щоб закодувати згенеровану джерелом послідовність символів побудованими кодами, поділяємо її на підпослідовності ( слова ) відповідної довжини та застосовуємо коди таблиць 7.5, 7.6, 7.7. В результаті отримаємо:
– для слів по два символи 0101000111111111, довжина закодованої послідовності L2 = 16 ;
– для слів по три символи 010001111111, довжина закодованої послідовності L3 = 12 ;
– для слів по чотири символи 01000111111, довжина закодованої послідовності L4 = 11.
Дата добавления: 2014-12-22; просмотров: 677;